If you’re interested in this project and would like to help in engineering efforts, or have general usage questions, we are happy to have you!
We hold a weekly meeting that all audiences are welcome to attend.
We would appreciate your feedback so that we can make Talos even better!
To do so, you can take our survey.
You can subscribe to this meeting by joining the community forum above.
Note: You can convert the meeting hours to your local time.
Enterprise
If you are using Talos in a production setting, and need consulting services to get started or to integrate Talos into your existing environment, we can help.
Sidero Labs, Inc. offers support contracts with SLA (Service Level Agreement)-bound terms for mission-critical environments.
A quick introduction in to what Talos is and why it should be used.
Talos is a container optimized Linux distro; a reimagining of Linux for distributed systems such as Kubernetes.
Designed to be as minimal as possible while still maintaining practicality.
For these reasons, Talos has a number of features unique to it:
it is immutable
it is atomic
it is ephemeral
it is minimal
it is secure by default
it is managed via a single declarative configuration file and gRPC API
Talos can be deployed on container, cloud, virtualized, and bare metal platforms.
Why Talos
In having less, Talos offers more.
Security.
Efficiency.
Resiliency.
Consistency.
All of these areas are improved simply by having less.
1.2 - Quickstart
A short guide on setting up a simple Talos Linux cluster locally with Docker.
Local Docker Cluster
The easiest way to try Talos is by using the CLI (talosctl) to create a cluster on a machine with docker installed.
Prerequisites
talosctl
Download talosctl (macOS or Linux):
brew install siderolabs/tap/talosctl
kubectl
Download kubectl via one of methods outlined in the documentation.
Create the Cluster
Now run the following:
talosctl cluster create
Note
If you are using Docker Desktop on a macOS computer you will need to enable the default Docker socket in your settings.
You can explore using Talos API commands:
talosctl dashboard --nodes 10.5.0.2
Verify that you can reach Kubernetes:
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
talos-default-controlplane-1 Ready master 115s v1.27.4 10.5.0.2 <none> Talos (v1.4.8) <host kernel> containerd://1.5.5
talos-default-worker-1 Ready <none> 115s v1.27.4 10.5.0.3 <none> Talos (v1.4.8) <host kernel> containerd://1.5.5
Destroy the Cluster
When you are all done, remove the cluster:
talosctl cluster destroy
1.3 - Getting Started
A guide to setting up a Talos Linux cluster on multiple machines.
This document will walk you through installing a full Talos Cluster.
If this is your first use of Talos Linux, we recommend the Quickstart first, to quickly create a local virtual cluster on your workstation.
Regardless of where you run Talos, in general you need to:
acquire the installation image
decide on the endpoint for Kubernetes
optionally create a load balancer
configure Talos
configure talosctl
bootstrap Kubernetes
Prerequisites
talosctl
talosctl is a CLI tool which interfaces with the Talos API in
an easy manner.
Install talosctl before continuing:
curl -sL https://talos.dev/install | sh
Acquire the installation image
The most general way to install Talos is to use the ISO image (note there are easier methods for some platforms, such as pre-built AMIs for AWS - check the specific Installation Guides.)
The latest ISO image can be found on the Github Releases page:
When booted from the ISO, Talos will run in RAM, and will not install itself
until it is provided a configuration.
Thus, it is safe to boot the ISO onto any machine.
Alternative Booting
For network booting and self-built media, you can use the published kernel and initramfs images:
Note that to use alternate booting, there are a number of required kernel parameters.
Please see the kernel docs for more information.
Decide the Kubernetes Endpoint
In order to configure Kubernetes, Talos needs to know
what the endpoint (DNS name or IP address) of the Kubernetes API Server will be.
The endpoint should be the fully-qualified HTTP(S) URL for the Kubernetes API
Server, which (by default) runs on port 6443 using HTTPS.
Thus, the format of the endpoint may be something like:
https://192.168.0.10:6443
https://kube.mycluster.mydomain.com:6443
https://[2001:db8:1234::80]:6443
The Kubernetes API Server endpoint, in order to be highly available, should be configured in a way that functions off all available control plane nodes.
There are three common ways to do this:
Dedicated Load-balancer
If you are using a cloud provider or have your own load-balancer (such
as HAProxy, nginx reverse proxy, or an F5 load-balancer), using
a dedicated load balancer is a natural choice.
Create an appropriate frontend matching the endpoint, and point the backends at the addresses of each of the Talos control plane nodes.
(Note that given we have not yet created the control plane nodes, the IP addresses of the backends may not be known yet.
We can bind the backends to the frontend at a later point.)
Layer 2 Shared IP
Talos has integrated support for serving Kubernetes from a shared/virtual IP address.
This method relies on Layer 2 connectivity between control plane Talos nodes.
In this case, we choose an unused IP address on the same subnet as the Talos
control plane nodes.
For instance, if your control plane node IPs are:
192.168.0.10
192.168.0.11
192.168.0.12
you could choose the ip 192.168.0.15 as your shared IP address.
(Make sure that 192.168.0.15 is not used by any other machine and that your DHCP server
will not serve it to any other machine.)
Once chosen, form the full HTTPS URL from this IP:
https://192.168.0.15:6443
If you create a DNS record for this IP, note you will need to use the IP address itself, not the DNS name, to configure the shared IP (machine.network.interfaces[].vip.ip) in the Talos configuration.
For more information about using a shared IP, see the related
Guide
DNS records
You can use DNS records to provide a measure of redundancy.
In this case, you would add multiple A or AAAA records (one for each control plane node) to a DNS name.
For instance, you could add:
kube.cluster1.mydomain.com IN A 192.168.0.10
kube.cluster1.mydomain.com IN A 192.168.0.11
kube.cluster1.mydomain.com IN A 192.168.0.12
Then, your endpoint would be:
https://kube.cluster1.mydomain.com:6443
Decide how to access the Talos API
Many administrative tasks are performed by calling the Talos API on Talos Linux control plane nodes.
We recommend directly accessing the control plane nodes from the talosctl client, if possible (i.e. set your endpoints to the IP addresses of the control plane nodes).
This requires your control plane nodes to be reachable from the client IP.
If the control plane nodes are not directly reachable from the workstation where you run talosctl, then configure a load balancer for TCP port 50000 to be forwarded to the control plane nodes.
Do not use Talos Linux’s built in VIP support for accessing the Talos API, as it will not function in the event of an etcd failure, and you will not be able to access the Talos API to fix things.
If you create a load balancer to forward the Talos API calls, make a note of the IP or
hostname so that you can configure your talosctl tool’s endpoints below.
Configure Talos
When Talos boots without a configuration, such as when using the Talos ISO, it
enters a limited maintenance mode and waits for a configuration to be provided.
In other installation methods, a configuration can be passed in on boot.
For example, Talos can be booted with the talos.config kernel
commandline argument set to an HTTP(s) URL from which it should receive its
configuration.
Where a PXE server is available, this is much more efficient than
manually configuring each node.
If you do use this method, note that Talos requires a number of other
kernel commandline parameters.
See required kernel parameters.
If creating EC2 kubernetes clusters, the configuration file can be passed in as --user-data to the aws ec2 run-instances command.
In any case, we need to generate the configuration which is to be provided.
We start with generating a secrets bundle which should be saved in a secure location and used
to generate machine or client configuration at any time:
talosctl gen secrets -o secrets.yaml
Now, we can generate the machine configuration for each node:
talosctl gen config --with-secrets secrets.yaml <cluster-name> <cluster-endpoint>
Here, cluster-name is an arbitrary name for the cluster, used
in your local client configuration as a label.
It should be unique in the configuration on your local workstation.
The cluster-endpoint is the Kubernetes Endpoint you
selected from above.
This is the Kubernetes API URL, and it should be a complete URL, with https://
and port.
(The default port is 6443, but you may have configured your load balancer to forward a different port.)
For example:
$ talosctl gen config --with-secrets secrets.yaml my-cluster https://192.168.64.15:6443
generating PKI and tokens
created /Users/taloswork/controlplane.yaml
created /Users/taloswork/worker.yaml
created /Users/taloswork/talosconfig
When you run this command, a number of files are created in your current
directory:
controlplane.yaml
worker.yaml
talosconfig
The .yaml files are Machine Configs.
They provide Talos Linux servers their complete configuration,
describing everything from what disk Talos should be installed on, to network settings.
The controlplane.yaml file describes how Talos should form a Kubernetes cluster.
The talosconfig file (which is also YAML) is your local client configuration file.
Controlplane and Worker
The two types of Machine Configs correspond to the two roles of Talos nodes, control plane (which run both the Talos and Kubernetes control planes) and worker nodes (which run the workloads).
The main difference between Controlplane Machine Config files and Worker Machine
Config files is that the former contains information about how to form the
Kubernetes cluster.
Modifying the Machine configs
The generated Machine Configs have defaults that work for many cases.
They use DHCP for interface configuration, and install to /dev/sda.
If the defaults work for your installation, you may use them as is.
Sometimes, you will need to modify the generated files so they work with your systems.
A common example is needing to change the default installation disk.
If you try to to apply the machine config to a node, and get an error like the below, you need to specify a different installation disk:
$ talosctl apply-config --insecure -n 192.168.64.8 --file controlplane.yaml
error applying new configuration: rpc error: code= InvalidArgument desc= configuration validation failed: 1 error occurred:
* specified install disk does not exist: "/dev/sda"
You can verify which disks your nodes have by using the talosctl disks --insecure command.
Insecure mode is needed at this point as the PKI infrastructure has not yet been set up.
For example:
$ talosctl -n 192.168.64.8 disks --insecure
DEV MODEL SERIAL TYPE UUID WWID MODALIAS NAME SIZE BUS_PATH
/dev/vda - - HDD - - virtio:d00000002v00001AF4 - 69 GB /pci0000:00/0000:00:06.0/virtio2/
In this case, you would modiy the controlplane.yaml and worker.yaml and edit the line:
install:
disk: /dev/sda # The disk used for installations.
to reflect vda instead of sda.
Customizing Machine Configuration
The generated machine configuration provides sane defaults for most cases, but machine configuration
can be modified to fit specific needs.
Some machine configuration options are available as flags for the talosctl gen config command,
for example setting a specific Kubernetes version:
talosctl gen config --with-secrets secrets.yaml --kubernetes-version 1.25.4 my-cluster https://192.168.64.15:6443
Other modifications are done with machine configuration patches.
Machine configuration patches can be applied with talosctl gen config command:
talosctl gen config --with-secrets secrets.yaml --config-patch-control-plane @cni.patch my-cluster https://192.168.64.15:6443
Note: @cni.patch means that the patch is read from a file named cni.patch.
Machine Configs as Templates
Individual machines may need different settings: for instance, each may have a
different static IP address.
When different files are needed for machines of the same type, there are two supported flows:
Use the talosctl gen config command to generate a template, and then patch
the template for each machine with talosctl machineconfig patch.
Generate each machine configuration file separately with talosctl gen config while applying patches.
For example, given a machine configuration patch which sets the static machine hostname:
The insecure flag is necessary because the PKI infrastructure has not yet been made available to the node.
Note: the connection will be encrypted, it is just unauthenticated.
If you have console access you can extract the server certificate fingerprint and use it for an additional layer of validation:
Using the fingerprint allows you to be sure you are sending the configuration to the correct machine, but it is completely optional.
After the configuration is applied to a node, it will reboot.
Repeat this process for each of the nodes in your cluster.
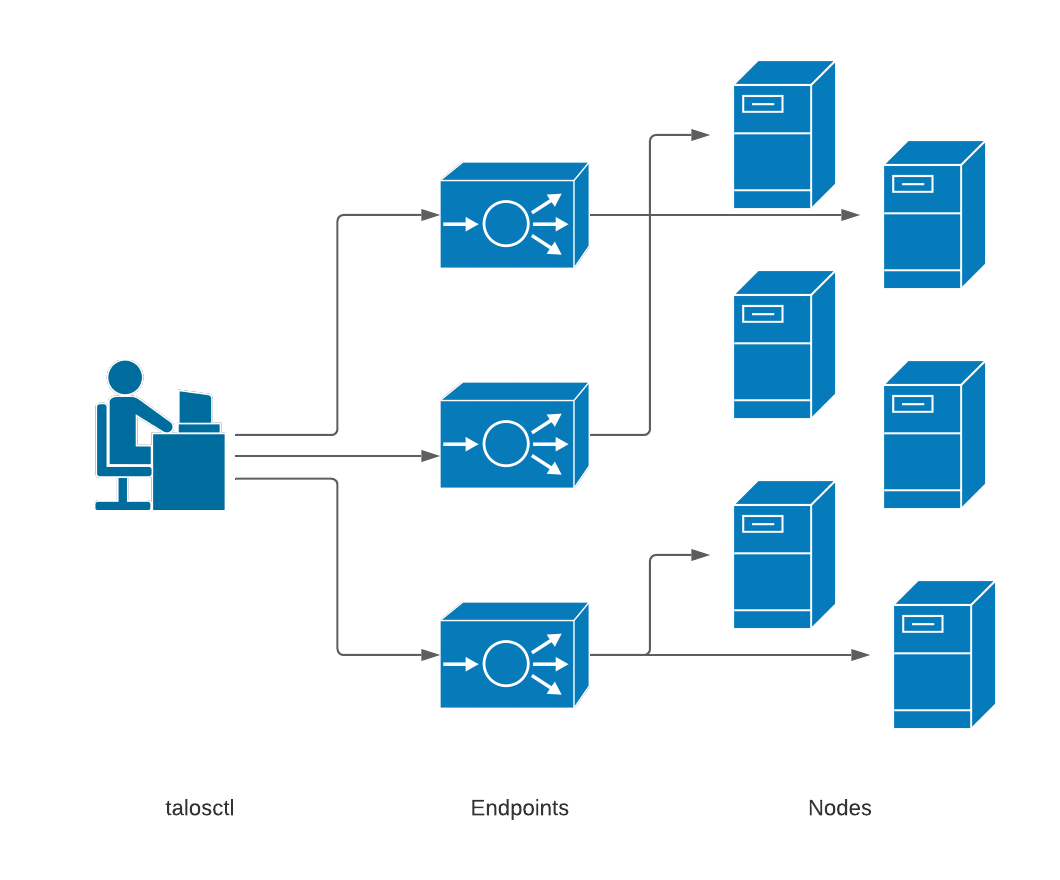
Understand talosctl, endpoints and nodes
It is important to understand the concept of endpoints and nodes.
In short: endpoints are the nodes that talosctl sends commands to, but nodes are the nodes that the command operates on.
The endpoint will forward the command to the nodes, if needed.
Endpoints
Endpoints are the IP addresses to which the talosctl client directly talks.
These should be the set of control plane nodes, either directly or through a load balancer.
Each endpoint will automatically proxy requests destined to another node in the cluster.
This means that you only need access to the control plane nodes in order to access the rest of the network.
talosctl will automatically load balance requests and fail over between all of your endpoints.
You can pass in --endpoints <IP Address1>,<IP Address2> as a comma separated list of IP/DNS addresses to the current talosctl command.
You can also set the endpoints in your talosconfig, by calling talosctl config endpoint <IP Address1> <IP Address2>.
Note: these are space separated, not comma separated.
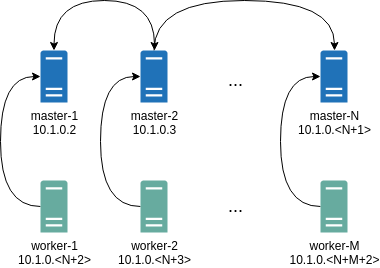
As an example, if the IP addresses of our control plane nodes are:
The node is the target you wish to perform the API call on.
When specifying nodes, their IPs and/or hostnames are as seen by the endpoint servers, not as from the client.
This is because all connections are proxied through the endpoints.
You may provide -n or --nodes to any talosctl command to supply the node or (comma-separated) nodes on which you wish to perform the operation.
For example, to see the containers running on node 192.168.0.200:
talosctl -n 192.168.0.200 containers
To see the etcd logs on both nodes 192.168.0.10 and 192.168.0.11:
talosctl -n 192.168.0.10,192.168.0.11 logs etcd
It is possible to set a default set of nodes in the talosconfig file, but our recommendation is to explicitly pass in the node or nodes to be operated on with each talosctl command.
For a more in-depth discussion of Endpoints and Nodes, please see talosctl.
Default configuration file
You can reference which configuration file to use directly with the --talosconfig parameter:
talosctl --talosconfig=./talosconfig \
--nodes 192.168.0.2 version
However, talosctl comes with tooling to help you integrate and merge this configuration into the default talosctl configuration file.
This is done with the merge option.
talosctl config merge ./talosconfig
This will merge your new talosconfig into the default configuration file ($XDG_CONFIG_HOME/talos/config.yaml), creating it if necessary.
Like Kubernetes, the talosconfig configuration files has multiple “contexts” which correspond to multiple clusters.
The <cluster-name> you chose above will be used as the context name.
Kubernetes Bootstrap
Bootstrapping your Kubernetes cluster with Talos is as simple as:
talosctl bootstrap --nodes 192.168.0.2
The bootstrap operation should only be called ONCE and only on a SINGLE control plane node!
The IP can be any of your control planes (or the loadbalancer, if used for the Talos API endpoint).
At this point, Talos will form an etcd cluster, generate all of the core Kubernetes assets, and start the Kubernetes control plane components.
After a few moments, you will be able to download your Kubernetes client configuration and get started:
talosctl kubeconfig
Running this command will add (merge) you new cluster into your local Kubernetes configuration.
If you would prefer the configuration to not be merged into your default Kubernetes configuration file, pass in a filename:
talosctl kubeconfig alternative-kubeconfig
You should now be able to connect to Kubernetes and see your nodes:
kubectl get nodes
And use talosctl to explore your cluster:
talosctl -n <NODEIP> dashboard
For a list of all the commands and operations that talosctl provides, see the CLI reference.
1.4 - System Requirements
Hardware requirements for running Talos Linux.
Minimum Requirements
Role
Memory
Cores
System Disk
Control Plane
2 GiB
2
10 GiB
Worker
1 GiB
1
10 GiB
Recommended
Role
Memory
Cores
System Disk
Control Plane
4 GiB
4
100 GiB
Worker
2 GiB
2
100 GiB
These requirements are similar to that of Kubernetes.
Storage
Talos Linux itself only requires less than 100 MB of disk space, but the EPHEMERAL partition is used to store pulled images, container work directories, and so on.
Thus a minimum is 10 GiB of disk space is required.
100 GiB is desired.
Note, however, that because Talos Linux assumes complete control of the disk it is installed on, so that it can control the partition table for image based upgrades, you cannot partition the rest of the disk for use by workloads.
Thus it is recommended to install Talos Linux on a small, dedicated disk - using a Terabyte sized SSD for the Talos install disk would be wasteful.
Sidero Labs recommends having separate disks (apart from the Talos install disk) to be used for storage.
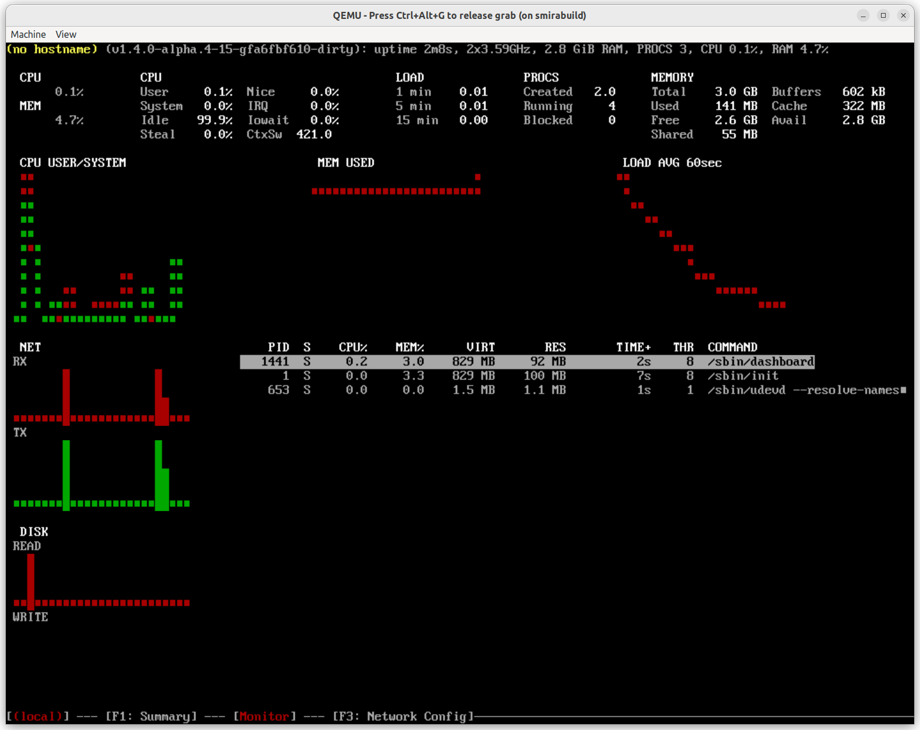
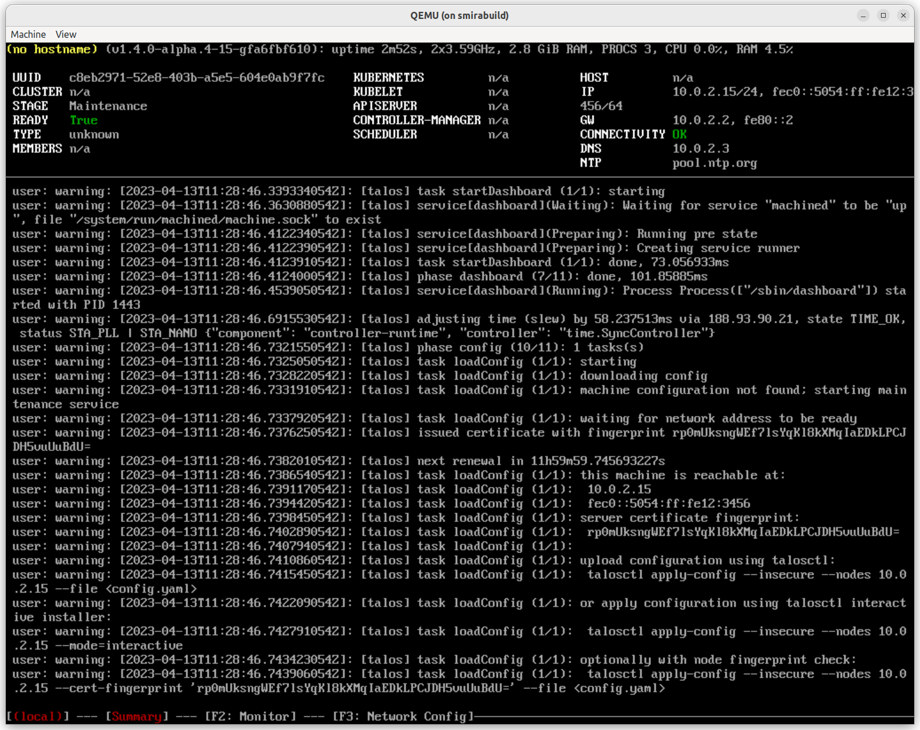
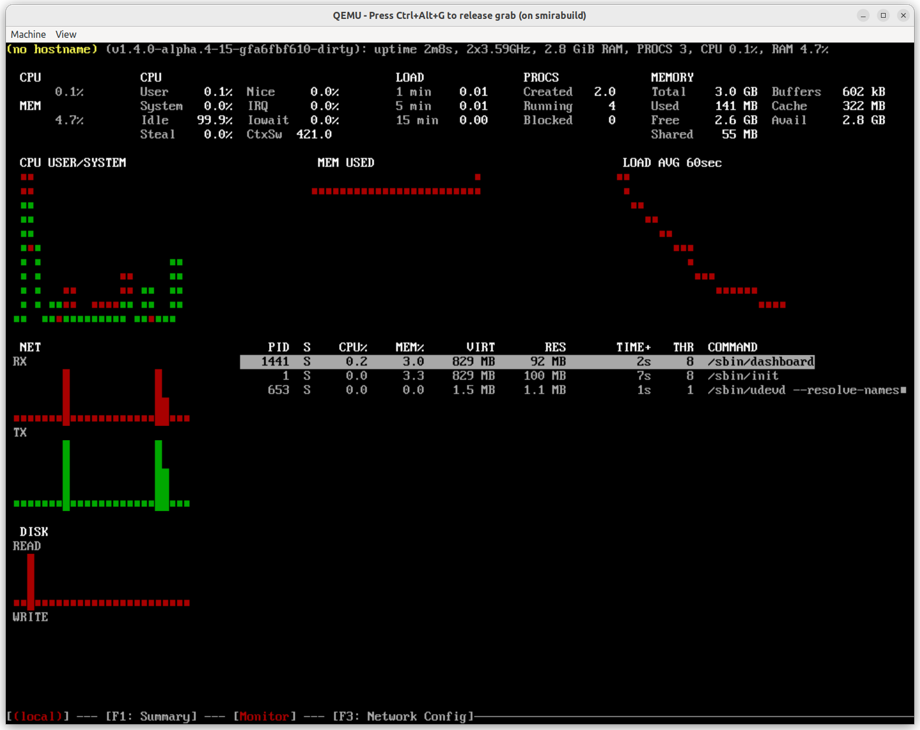
Talos now starts a text-based UI dashboard on virtual console /dev/tty2 and switches to it by default upon boot.
Kernel logs remain available on /dev/tty1.
To switch between virtual TTYs, use the Alt+F1 and Alt+F2 keys.
You can disable this new feature by setting the kernel parameter talos.dashboard.disabled=1.
The dashboard is disabled by default on SBCs to limit resource usage.
The output to the serial console is not affected by this change.
Interactive Dashboard on QEMU VM
Boot Process
Talos now ships with the latest Linux LTS kernel 6.1.x.
GRUB Menu Wipe Options
Talos ISO GRUB menu now an includes an option to wipe completely a Talos installed on a system disk.
Talos GRUB menu for a system disk boot now includes an option to wipe STATE and EPHEMERAL partition returning the
machine to the maintenance mode.
Kernel Modules
Talos now automatically loads kernel drivers built as modules.
If any system extensions or the Talos base kernel build provides kernel modules and if they matches the system hardware (via PCI IDs), they will be loaded automatically.
Modules can still be loaded explicitly by defining it in machine configuration.
At the moment only a small subset of device drivers is built as modules, but we plan to expand this list in the future.
Kernel Modules Tree
Talos now supports re-building the kernel modules dependency tree information on upgrades.
This allows modules of same name to co-exist as in-tree and external modules.
System Extensions can provide modules installed into extras directory and when loading it’ll take precedence over the in-tree module.
Kernel Argument talos.environment
Talos now supports passing environment variables via talos.environment kernel argument.
talosctl logs -k and talosctl containers -k now support and output container display names with their ids.
This allows to distinguish between containers with the same name.
talosctl dashboard
A dashboard now shows same information as interactive console (see above), but in a remote way over the Talos API:
talosctl dashboard CLI
Previous monitoring screen can be accessed by using <F2> key.
talosctl logs
An issue was fixed which might lead to the log output corruption in the CLI under certain conditions.
talosctl netstat
Talos API was extended to support retrieving a list of network connections (sockets) from the node and pods.
talosctl netstat command was added to retrieve the list of network connections.
talosctl reset
Talos now supports resetting user disks through the Reset API,
the list of disks to wipe can be passed using the --user-disks-to-wipe flag to the talosctl reset command.
Miscellaneous
Registry Mirror Catch-All Option
Talos now supports a catch-all option for registry mirrors:
Talos now supports a new os:operator role for the Talos API.
This role allows everything os:reader role allows plus access to maintenance APIs:
rebooting, shutting down a node, accessing packet capture, etcd alarm APIs, etcd backup, etc.
VMware Platform
Talos now supports loading network configuration on VMWare platform from the metadata key.
See CAPV IPAM Support and
Talos issue 6708 for details.
Component Updates
Linux: 6.1.24
containerd: v1.6.20
runc: v1.1.5
Kubernetes: v1.27.1
etcd: v3.5.8
CoreDNS: v1.10.1
Flannel: v0.21.4
Talos is built with Go 1.20.3.
1.6 - Support Matrix
Table of supported Talos Linux versions and respective platforms.
x86: BIOS, UEFI; arm64: UEFI; boot: ISO, PXE, disk image
x86: BIOS, UEFI; arm64: UEFI; boot: ISO, PXE, disk image
- virtualized
VMware, Hyper-V, KVM, Proxmox, Xen
VMware, Hyper-V, KVM, Proxmox, Xen
- SBCs
Banana Pi M64, Jetson Nano, Libre Computer Board ALL-H3-CC, Nano Pi R4S, Pine64, Pine64 Rock64, Radxa ROCK Pi 4c, Raspberry Pi 4B, Raspberry Pi Compute Module 4
Banana Pi M64, Jetson Nano, Libre Computer Board ALL-H3-CC, Nano Pi R4S, Pine64, Pine64 Rock64, Radxa ROCK Pi 4c, Raspberry Pi 4B, Raspberry Pi Compute Module 4
In this guide we will create an Kubernetes cluster with 1 worker node, and 2 controlplane nodes.
We assume an existing digital rebar deployment, and some familiarity with iPXE.
We leave it up to the user to decide if they would like to use static networking, or DHCP.
The setup and configuration of DHCP will not be covered.
Create the Machine Configuration Files
Generating Base Configurations
Using the DNS name of the load balancer, generate the base configuration files for the Talos machines:
$ talosctl gen config talos-k8s-metal-tutorial https://<load balancer IP or DNS>:<port>
created controlplane.yaml
created worker.yaml
created talosconfig
The loadbalancer is used to distribute the load across multiple controlplane nodes.
This isn’t covered in detail, because we assume some loadbalancing knowledge before hand.
If you think this should be added to the docs, please create a issue.
At this point, you can modify the generated configs to your liking.
Optionally, you can specify --config-patch with RFC6902 jsonpatch which will be applied during the config generation.
Validate the Configuration Files
$ talosctl validate --config controlplane.yaml --mode metal
controlplane.yaml is valid for metal mode
$ talosctl validate --config worker.yaml --mode metal
worker.yaml is valid for metal mode
Publishing the Machine Configuration Files
Digital Rebar has a built-in fileserver, which means we can use this feature to expose the talos configuration files.
We will place controlplane.yaml, and worker.yaml into Digital Rebar file server by using the drpcli tools.
Copy the generated files from the step above into your Digital Rebar installation.
drpcli file upload <file>.yaml as <file>.yaml
Replacing <file> with controlplane or worker.
Download the boot files
Download a recent version of boot.tar.gz from github.
At this point we can retrieve the admin kubeconfig by running:
talosctl --talosconfig talosconfig kubeconfig .
2.1.1.2 - Equinix Metal
Creating Talos clusters with Equinix Metal.
You can create a Talos Linux cluster on Equinix Metal in a variety of ways, such as through the EM web UI, the metal command line too, or through PXE booting.
Talos Linux is a supported OS install option on Equinix Metal, so it’s an easy process.
Regardless of the method, the process is:
Create a DNS entry for your Kubernetes endpoint.
Generate the configurations using talosctl.
Provision your machines on Equinix Metal.
Push the configurations to your servers (if not done as part of the machine provisioning).
configure your Kubernetes endpoint to point to the newly created control plane nodes
bootstrap the cluster
Define the Kubernetes Endpoint
There are a variety of ways to create an HA endpoint for the Kubernetes cluster.
Some of the ways are:
DNS
Load Balancer
BGP
Whatever way is chosen, it should result in an IP address/DNS name that routes traffic to all the control plane nodes.
We do not know the control plane node IP addresses at this stage, but we should define the endpoint DNS entry so that we can use it in creating the cluster configuration.
After the nodes are provisioned, we can use their addresses to create the endpoint A records, or bind them to the load balancer, etc.
Create the Machine Configuration Files
Generating Configurations
Using the DNS name of the loadbalancer defined above, generate the base configuration files for the Talos machines:
$ talosctl gen config talos-k8s-em-tutorial https://<load balancer IP or DNS>:<port>
created controlplane.yaml
created worker.yaml
created talosconfig
The port used above should be 6443, unless your load balancer maps a different port to port 6443 on the control plane nodes.
Validate the Configuration Files
talosctl validate --config controlplane.yaml --mode metal
talosctl validate --config worker.yaml --mode metal
Note: Validation of the install disk could potentially fail as validation
is performed on your local machine and the specified disk may not exist.
Passing in the configuration as User Data
You can use the metadata service provide by Equinix Metal to pass in the machines configuration.
It is required to add a shebang to the top of the configuration file.
The convention we use is #!talos.
Provision the machines in Equinix Metal
Using the Equinix Metal UI
Simply select the location and type of machines in the Equinix Metal web interface.
Select Talos as the Operating System, then select the number of servers to create, and name them (in lowercase only.)
Under optional settings, you can optionally paste in the contents of controlplane.yaml that was generated, above (ensuring you add a first line of #!talos).
You can repeat this process to create machines of different types for control plane and worker nodes (although you would pass in worker.yaml for the worker nodes, as user data).
If you did not pass in the machine configuration as User Data, you need to provide it to each machine, with the following command:
This guide assumes the user has a working API token,and the Equinix Metal CLI installed.
Because Talos Linux is a supported operating system, Talos Linux machines can be provisioned directly via the CLI, using the -O talos_v1 parameter (for Operating System).
Note: Ensure you have prepended #!talos to the controlplane.yaml file.
Now our control plane nodes have been created, and we know their IP addresses, we can associate them with the Kubernetes endpoint.
Configure your load balancer to route traffic to these nodes, or add A records to your DNS entry for the endpoint, for each control plane node.
e.g.
host endpoint.mydomain.com
endpoint.mydomain.com has address 145.40.90.201
endpoint.mydomain.com has address 147.75.109.71
endpoint.mydomain.com has address 145.40.90.177
This only needs to be issued to one control plane node.
Retrieve the kubeconfig
At this point we can retrieve the admin kubeconfig by running:
talosctl --talosconfig talosconfig kubeconfig .
2.1.1.3 - ISO
Booting Talos on bare-metal with ISO.
Talos can be installed on bare-metal machine using an ISO image.
ISO images for amd64 and arm64 architectures are available on the Talos releases page.
Talos doesn’t install itself to disk when booted from an ISO until the machine configuration is applied.
Please follow the getting started guide for the generic steps on how to install Talos.
Note: If there is already a Talos installation on the disk, the machine will boot into that installation when booting from a Talos ISO.
The boot order should prefer disk over ISO, or the ISO should be removed after the installation to make Talos boot from disk.
In this guide we will create an HA Kubernetes cluster with 3 worker nodes using an existing load balancer and matchbox deployment.
Creating a Cluster
In this guide we will create an HA Kubernetes cluster with 3 worker nodes.
We assume an existing load balancer, matchbox deployment, and some familiarity with iPXE.
We leave it up to the user to decide if they would like to use static networking, or DHCP.
The setup and configuration of DHCP will not be covered.
Create the Machine Configuration Files
Generating Base Configurations
Using the DNS name of the load balancer, generate the base configuration files for the Talos machines:
$ talosctl gen config talos-k8s-metal-tutorial https://<load balancer IP or DNS>:<port>
created controlplane.yaml
created worker.yaml
created talosconfig
At this point, you can modify the generated configs to your liking.
Optionally, you can specify --config-patch with RFC6902 jsonpatch which will be applied during the config generation.
Validate the Configuration Files
$ talosctl validate --config controlplane.yaml --mode metal
controlplane.yaml is valid for metal mode
$ talosctl validate --config worker.yaml --mode metal
worker.yaml is valid for metal mode
Publishing the Machine Configuration Files
In bare-metal setups it is up to the user to provide the configuration files over HTTP(S).
A special kernel parameter (talos.config) must be used to inform Talos about where it should retrieve its configuration file.
To keep things simple we will place controlplane.yaml, and worker.yaml into Matchbox’s assets directory.
This directory is automatically served by Matchbox.
Create the Matchbox Configuration Files
The profiles we will create will reference vmlinuz, and initramfs.xz.
Download these files from the release of your choice, and place them in /var/lib/matchbox/assets.
Now that we have our configuration files in place, boot all the machines.
Talos will come up on each machine, grab its configuration file, and bootstrap itself.
At this point we can retrieve the admin kubeconfig by running:
talosctl --talosconfig talosconfig kubeconfig .
2.1.1.5 - Network Configuration
In this guide we will describe how network can be configured on bare-metal platforms.
By default, Talos will run DHCP client on all interfaces which have a link, and that might be enough for most of the cases.
If some advanced network configuration is required, it can be done via the machine configuration file.
But sometimes it is required to apply network configuration even before the machine configuration can be fetched from the network.
Kernel Command Line
Talos supports some kernel command line parameters to configure network before the machine configuration is fetched.
Note: Kernel command line parameters are not persisted after Talos installation, so proper network configuration should be done via the machine configuration.
Address, default gateway and DNS servers can be configured via ip= kernel command line parameter:
Some platforms (e.g. AWS, Google Cloud, etc.) have their own network configuration mechanisms, which can be used to perform the initial network configuration.
There is no such mechanism for bare-metal platforms, so Talos provides a way to use platform network config on the metal platform to submit the initial network configuration.
The platform network configuration is a YAML document which contains resource specifications for various network resources.
For the metal platform, the interactive dashboard can be used to edit the platform network configuration.
The current value of the platform network configuration can be retrieved using the MetaKeys resource (key 0xa):
talosctl get meta 0xa
The platform network configuration can be updated using the talosctl meta command for the running node:
talosctl meta write 0xa '{"externalIPs": ["1.2.3.4"]}'talosctl meta delete 0xa
The initial platform network configuration for the metal platform can be also included into the generated Talos image:
docker run --rm -i ghcr.io/siderolabs/imager:v1.4.8 iso --arch amd64 --tar-to-stdout --meta 0xa='{...}' | tar xz
docker run --rm -i --privileged ghcr.io/siderolabs/imager:v1.4.8 image --platform metal --arch amd64 --tar-to-stdout --meta 0xa='{...}' | tar xz
The platform network configuration gets merged with other sources of network configuration, the details can be found in the network resources guide.
2.1.1.6 - PXE
Booting Talos over the network on bare-metal with PXE.
Talos can be installed on bare-metal using PXE service.
There are two more detailed guides for PXE booting using Matchbox and Digital Rebar.
This guide describes generic steps for PXE booting Talos on bare-metal.
First, download the vmlinuz and initramfs assets from the Talos releases page.
Set up the machines to PXE boot from the network (usually by setting the boot order in the BIOS).
There might be options specific to the hardware being used, booting in BIOS or UEFI mode, using iPXE, etc.
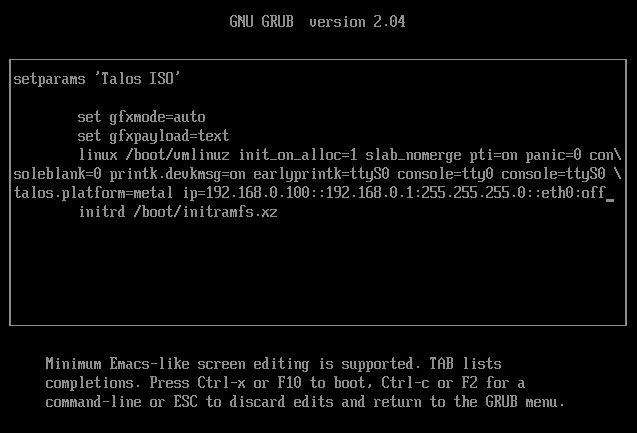
Talos requires the following kernel parameters to be set on the initial boot:
talos.platform=metal
slab_nomerge
pti=on
When booted from the network without machine configuration, Talos will start in maintenance mode.
Please follow the getting started guide for the generic steps on how to install Talos.
Note: If there is already a Talos installation on the disk, the machine will boot into that installation when booting from network.
The boot order should prefer disk over network.
Talos can automatically fetch the machine configuration from the network on the initial boot using talos.config kernel parameter.
A metadata service (HTTP service) can be implemented to deliver customized configuration to each node for example by using the MAC address of the node:
Note: The talos.config kernel parameter supports other substitution variables, see kernel parameters reference for the full list.
2.1.1.7 - Sidero Metal
Sidero Metal is a project created by the Talos team that has native support for Talos.
Sidero Metal is a project created by the Talos team that provides a bare metal installer for Cluster API, and that has native support for Talos Linux.
It can be easily installed using clusterctl.
The best way to get started with Sidero Metal is to visit the website.
2.1.2 - Virtualized Platforms
Installation of Talos Linux for virtualization platforms.
2.1.2.1 - Hyper-V
Creating a Talos Kubernetes cluster using Hyper-V.
Pre-requisities
Download the latest talos-amd64.iso ISO from github releases page
Create a New-TalosVM folder in any of your PS Module Path folders $env:PSModulePath -split ';' and save the New-TalosVM.psm1 there
Plan Overview
Here we will create a basic 3 node cluster with a single control-plane node and two worker nodes.
The only difference between control plane and worker node is the amount of RAM and an additional storage VHD.
This is personal preference and can be configured to your liking.
We are using a VMNamePrefix argument for a VM Name prefix and not the full hostname.
This command will find any existing VM with that prefix and “+1” the highest suffix it finds.
For example, if VMs talos-cp01 and talos-cp02 exist, this will create VMs starting from talos-cp03, depending on NumberOfVMs argument.
Setup a Control Plane Node
Use the following command to create a single control plane node:
This will create two VMs: talos-worker01 and talos-wworker02 and attach an additional VHD of 50GB for storage (which in my case will be passed to Mayastor).
Pushing Config to the Nodes
Now that our VMs are ready, find their IP addresses from console of VM.
With that information, push config to the control plane node with:
# set control plane IP variable$CONTROL_PLANE_IP='10.10.10.x'# Generate talos configtalosctl gen config talos-cluster https://$($CONTROL_PLANE_IP):6443 --output-dir .
# Apply config to control plane nodetalosctl apply-config --insecure --nodes $CONTROL_PLANE_IP --file .\controlplane.yaml
Now that our nodes are ready, we are ready to bootstrap the Kubernetes cluster.
# Use following command to set node and endpoint permanantly in config so you dont have to type it everytimetalosctl config endpoint $CONTROL_PLANE_IPtalosctl config node $CONTROL_PLANE_IP# Bootstrap clustertalosctl bootstrap
# Generate kubeconfigtalosctl kubeconfig .
This will generate the kubeconfig file, you can use to connect to the cluster.
2.1.2.2 - KVM
Talos is known to work on KVM.
We don’t yet have a documented guide specific to KVM; however, you can have a look at our
Vagrant & Libvirt guide which uses KVM for virtualization.
If you run into any issues, our community can probably help!
2.1.2.3 - Proxmox
Creating Talos Kubernetes cluster using Proxmox.
In this guide we will create a Kubernetes cluster using Proxmox.
Video Walkthrough
To see a live demo of this writeup, visit Youtube here:
Installation
How to Get Proxmox
It is assumed that you have already installed Proxmox onto the server you wish to create Talos VMs on.
Visit the Proxmox downloads page if necessary.
Install talosctl
You can download talosctl via
curl -sL https://talos.dev/install | sh
Download ISO Image
In order to install Talos in Proxmox, you will need the ISO image from the Talos release page.
You can download talos-amd64.iso via
github.com/siderolabs/talos/releases
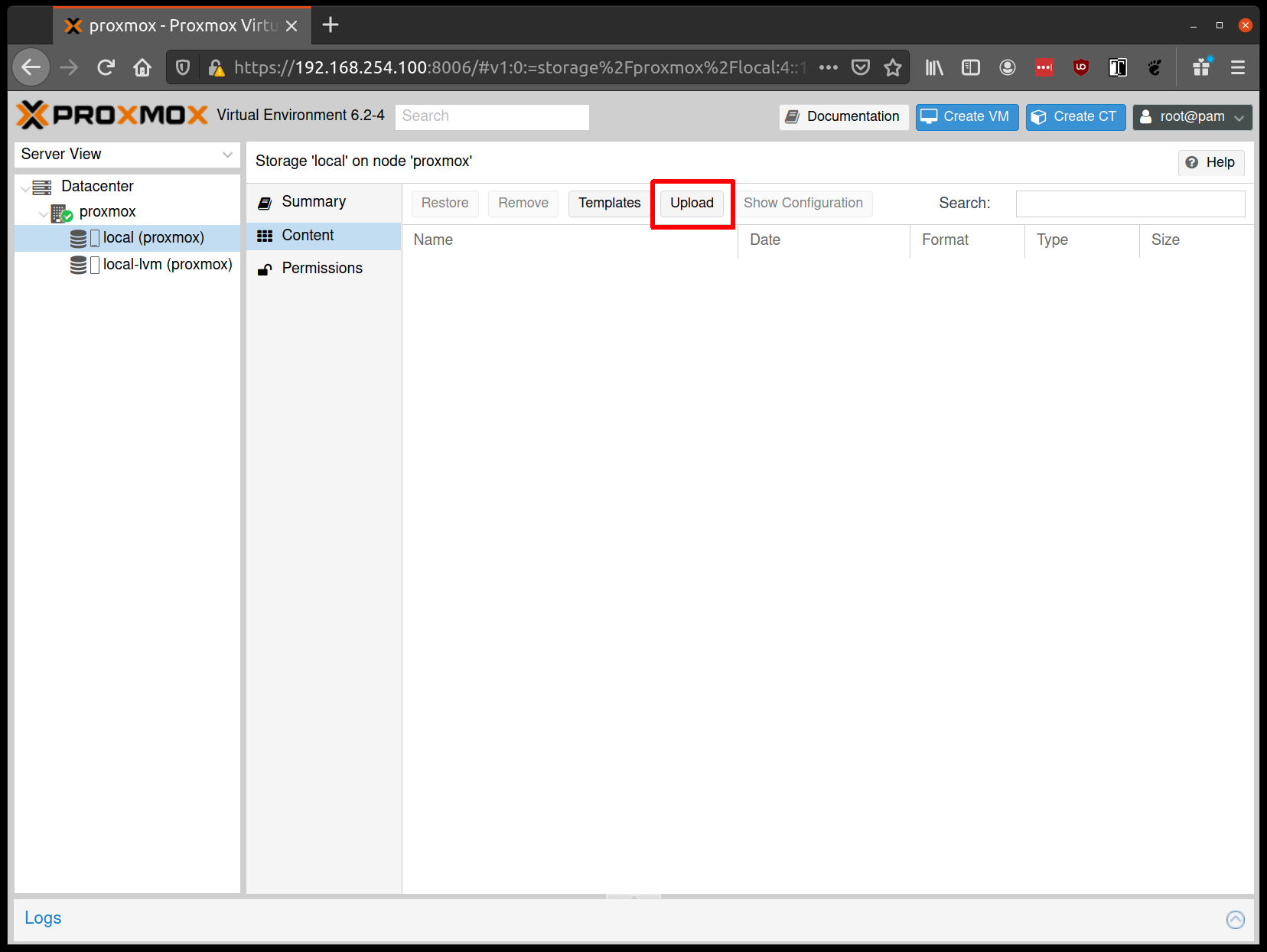
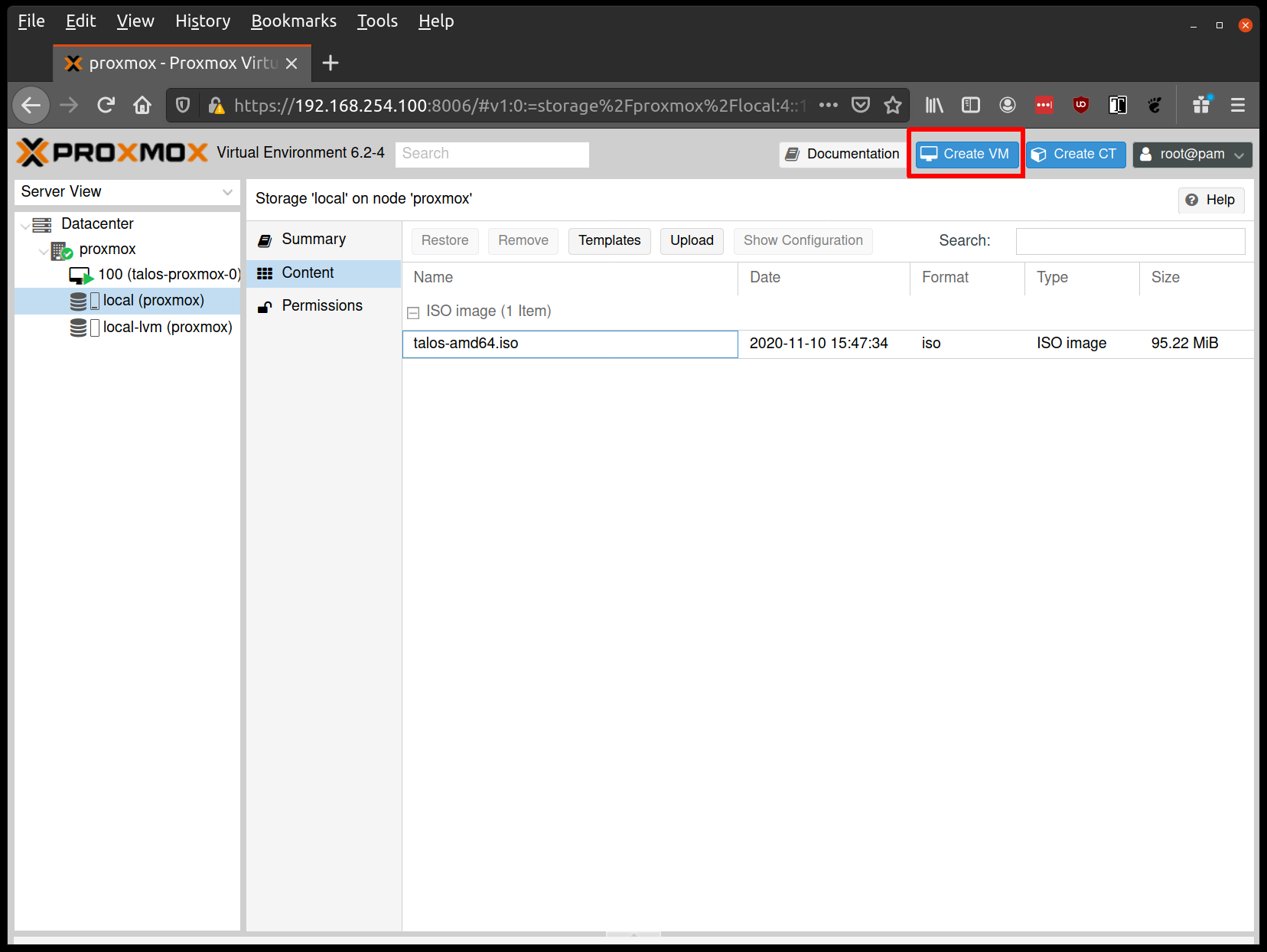
From the Proxmox UI, select the “local” storage and enter the “Content” section.
Click the “Upload” button:
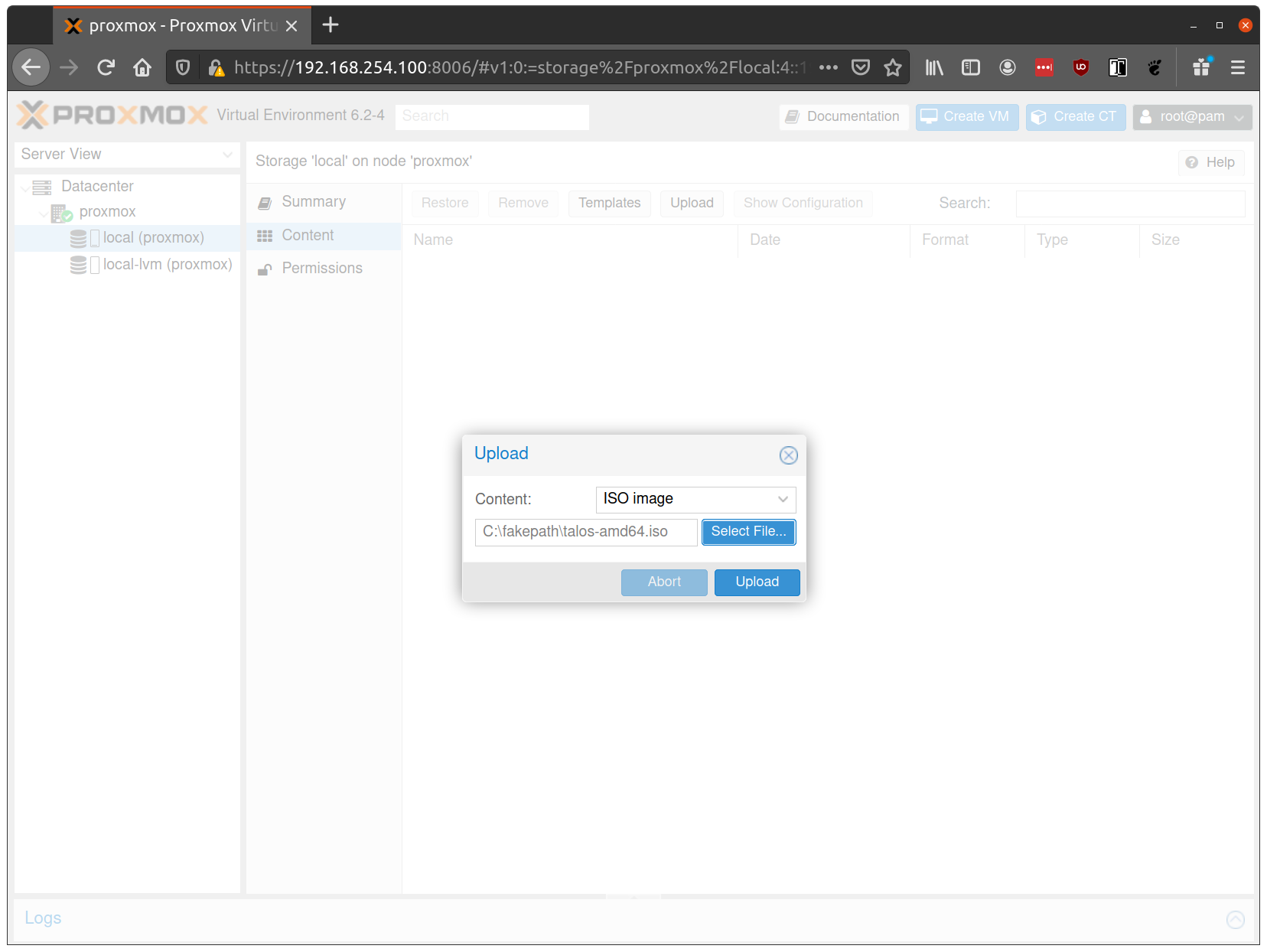
Select the ISO you downloaded previously, then hit “Upload”
Create VMs
Before starting, familiarise yourself with the
system requirements for Talos and assign VM
resources accordingly.
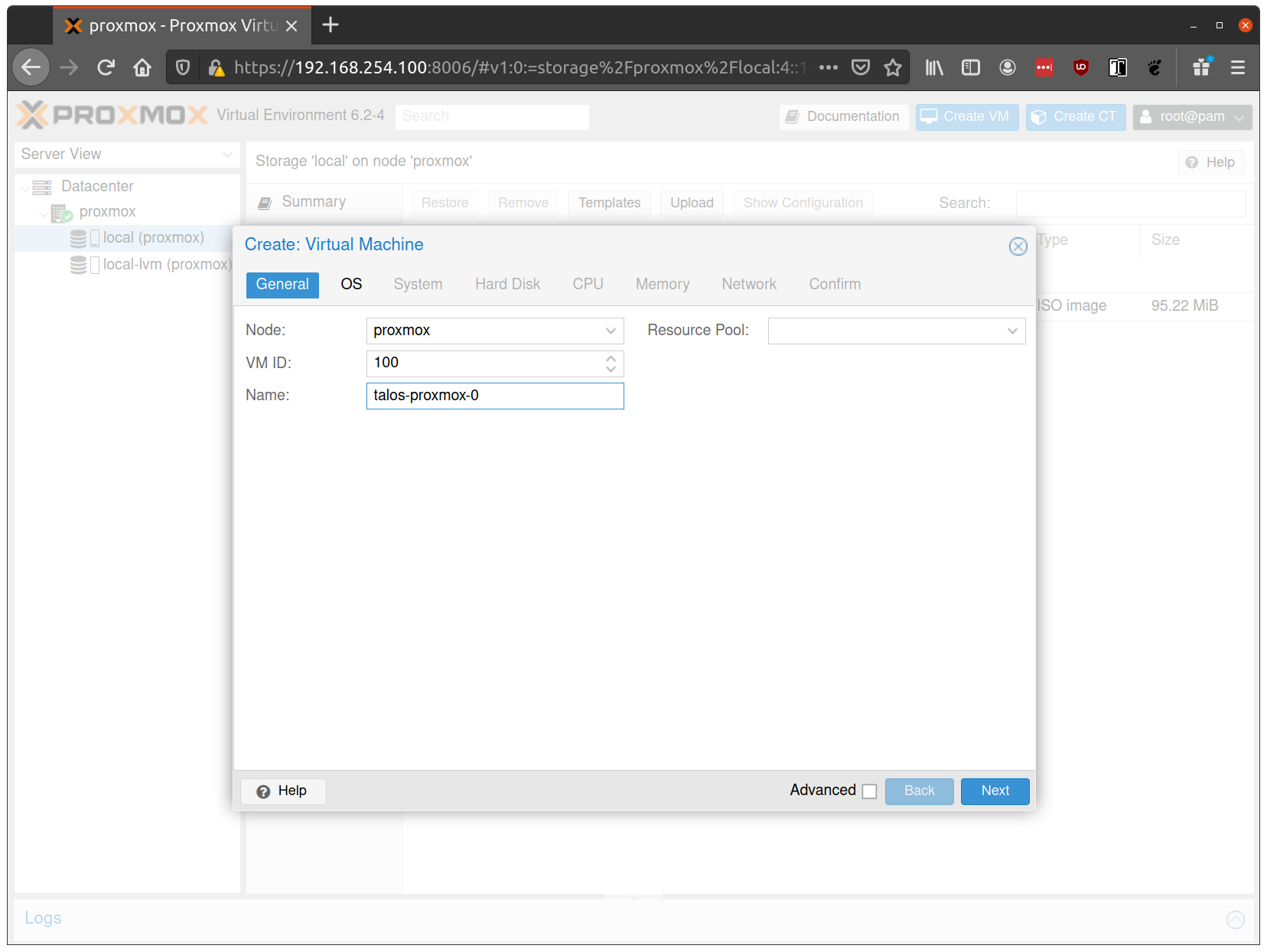
Create a new VM by clicking the “Create VM” button in the Proxmox UI:
Fill out a name for the new VM:
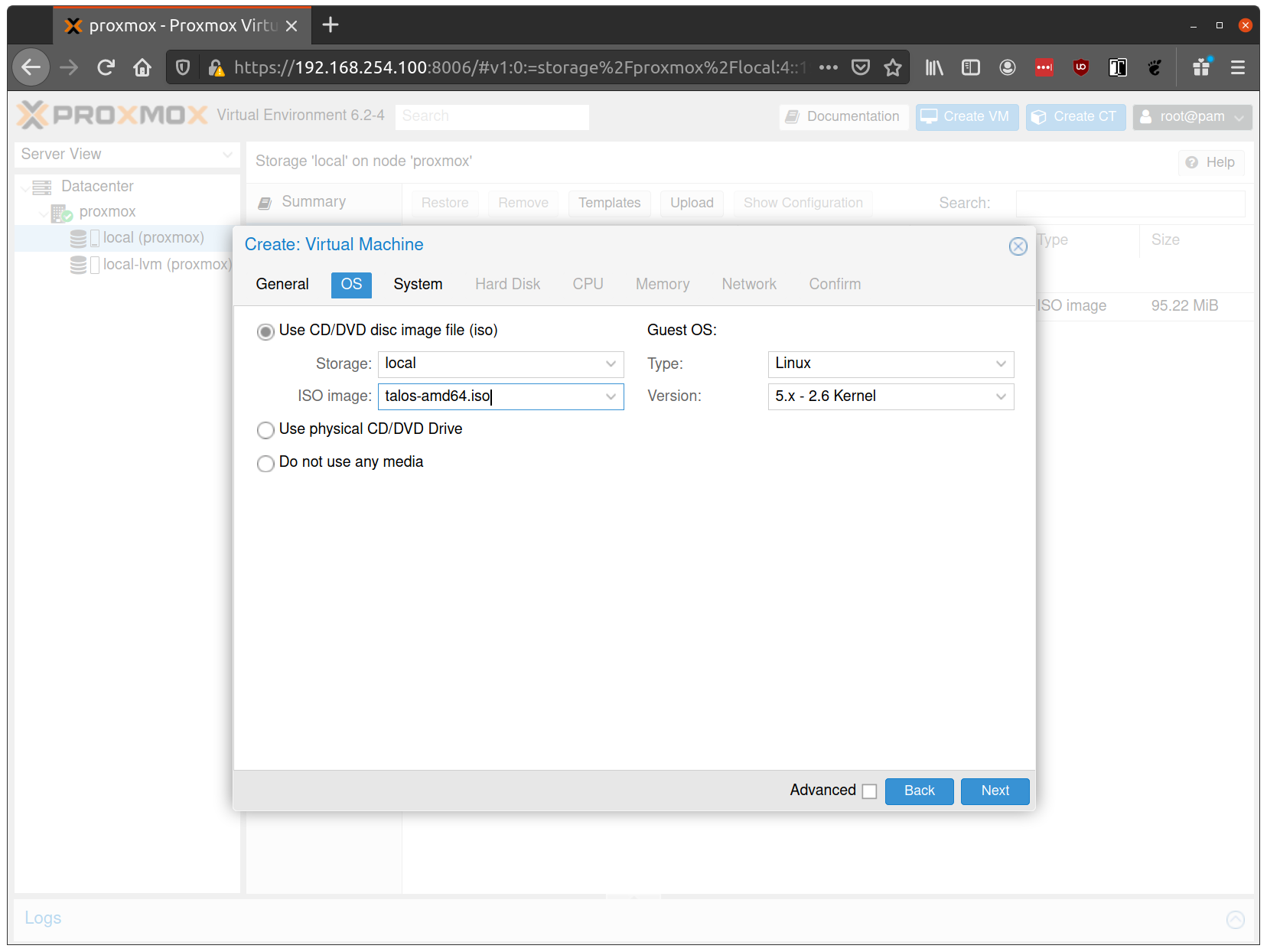
In the OS tab, select the ISO we uploaded earlier:
Keep the defaults set in the “System” tab.
Keep the defaults in the “Hard Disk” tab as well, only changing the size if desired.
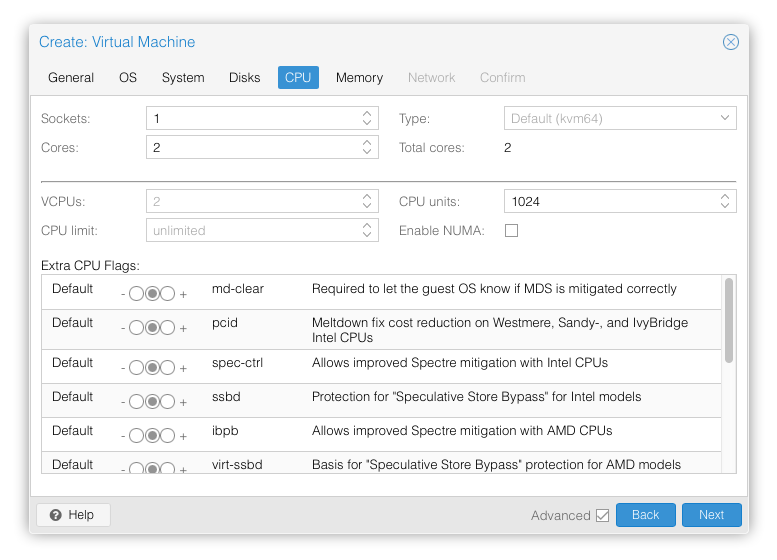
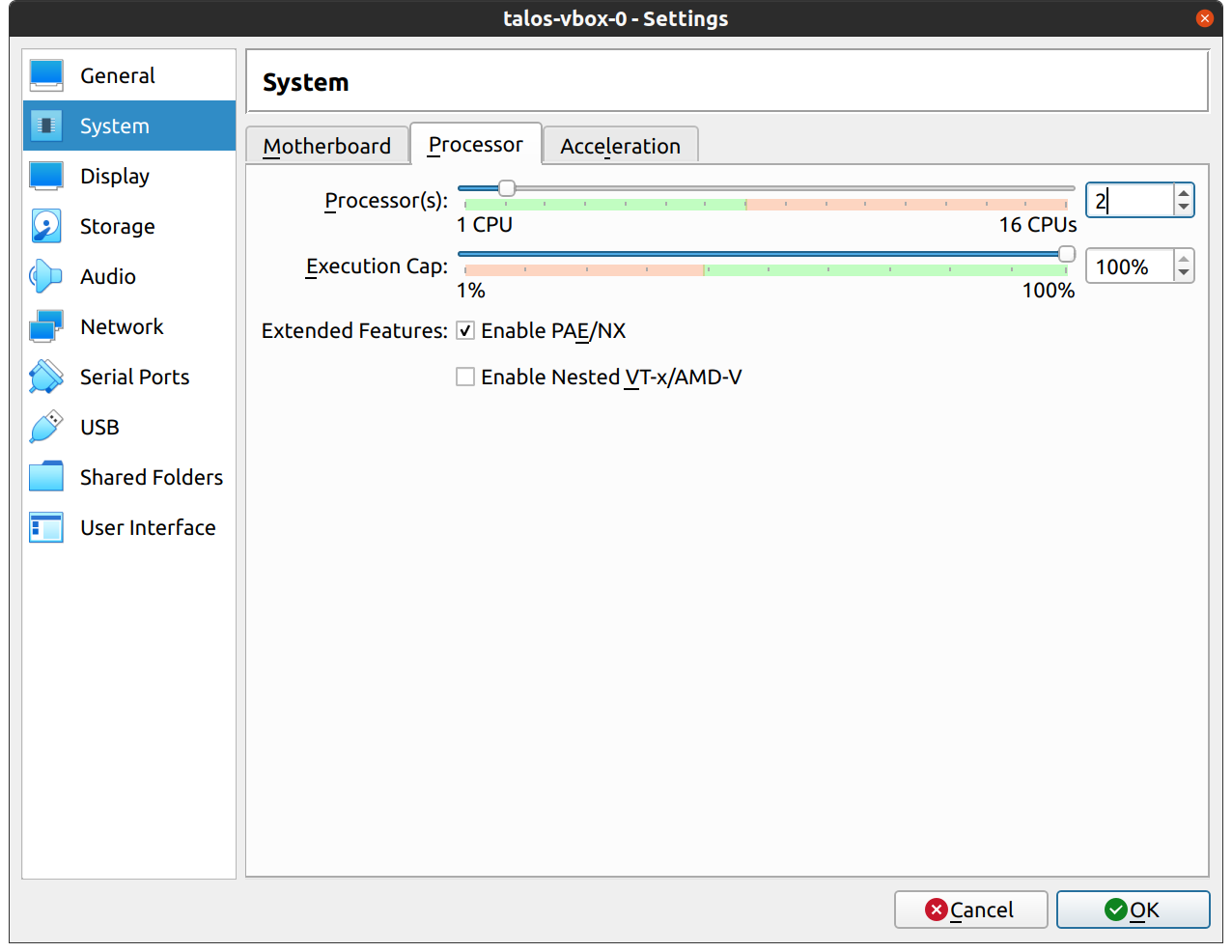
In the “CPU” section, give at least 2 cores to the VM:
Note: As of Talos v1.0 (which requires the x86-64-v2 microarchitecture), prior to Proxmox V8.0, booting with the
default Processor Type kvm64 will not work.
You can enable the required CPU features after creating the VM by
adding the following line in the corresponding /etc/pve/qemu-server/<vmid>.conf file:
Alternatively, you can set the Processor Type to host if your Proxmox host supports these CPU features,
this however prevents using live VM migration.
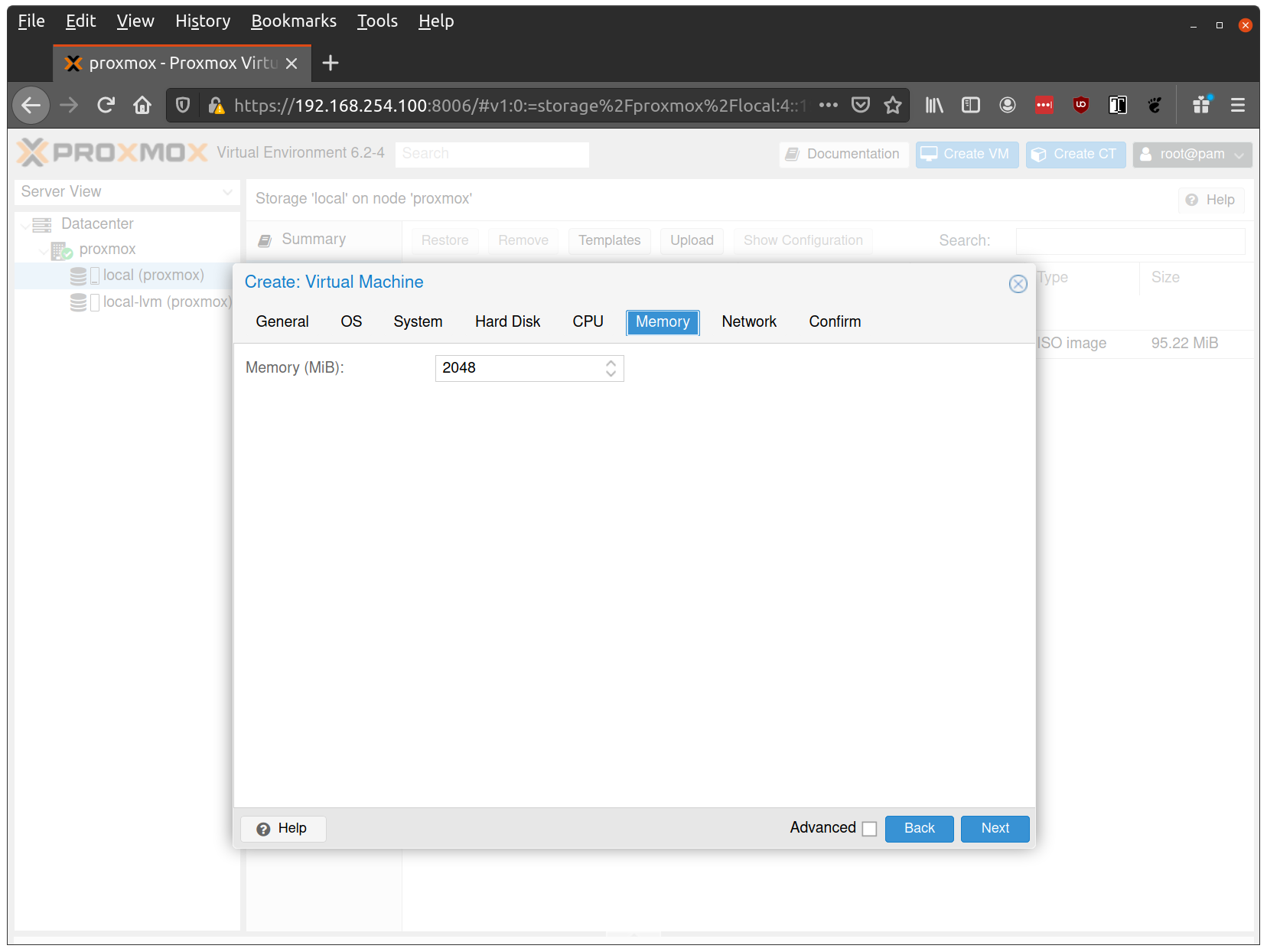
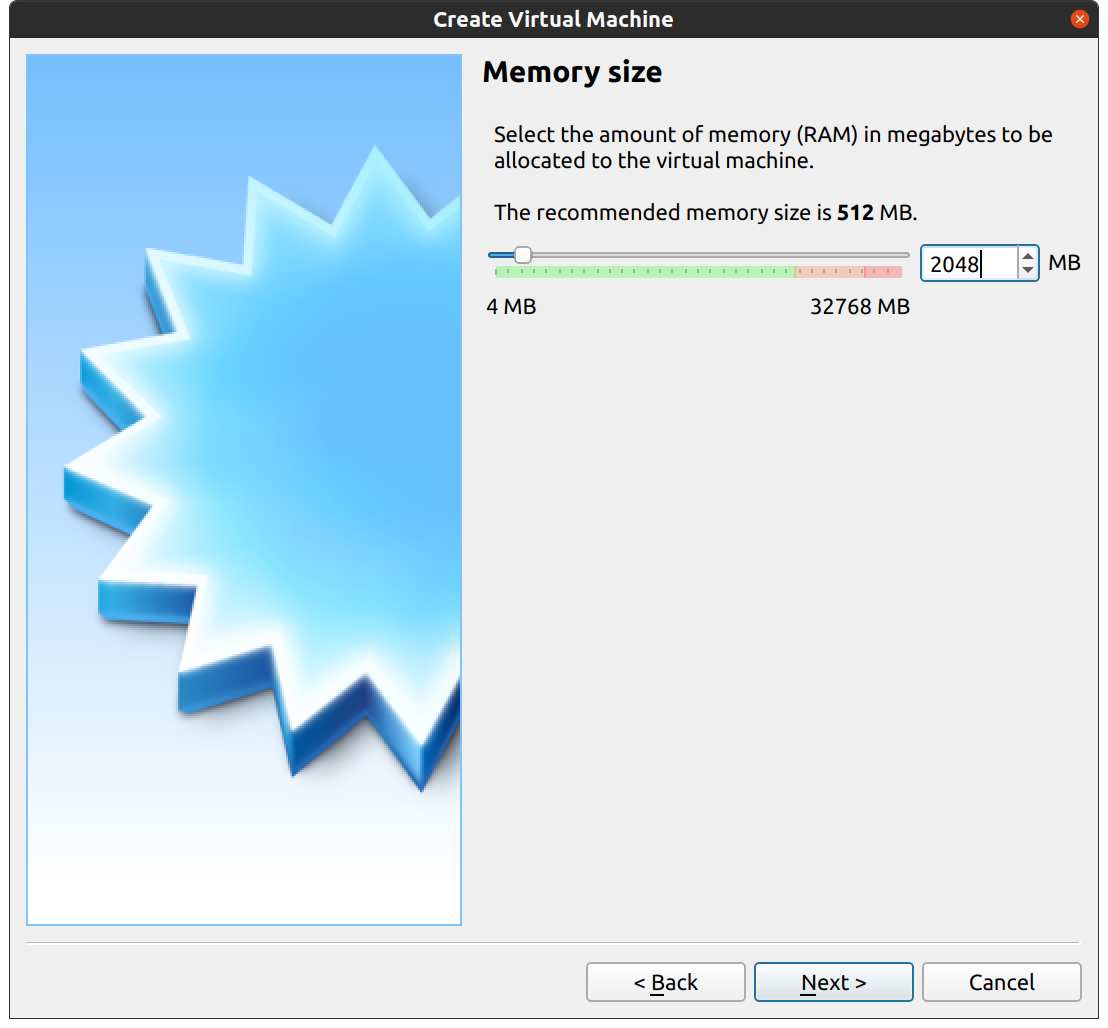
Verify that the RAM is set to at least 2GB:
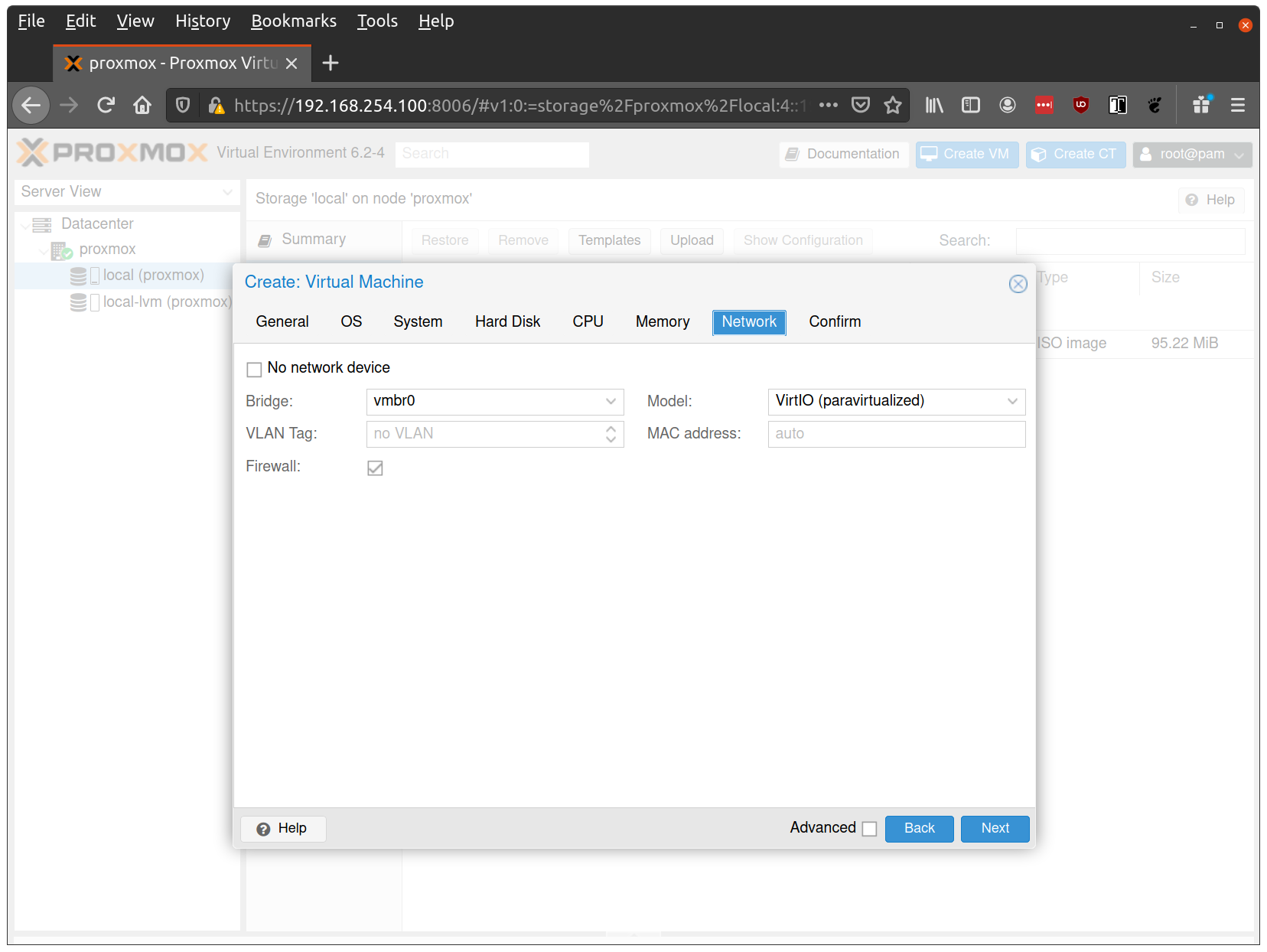
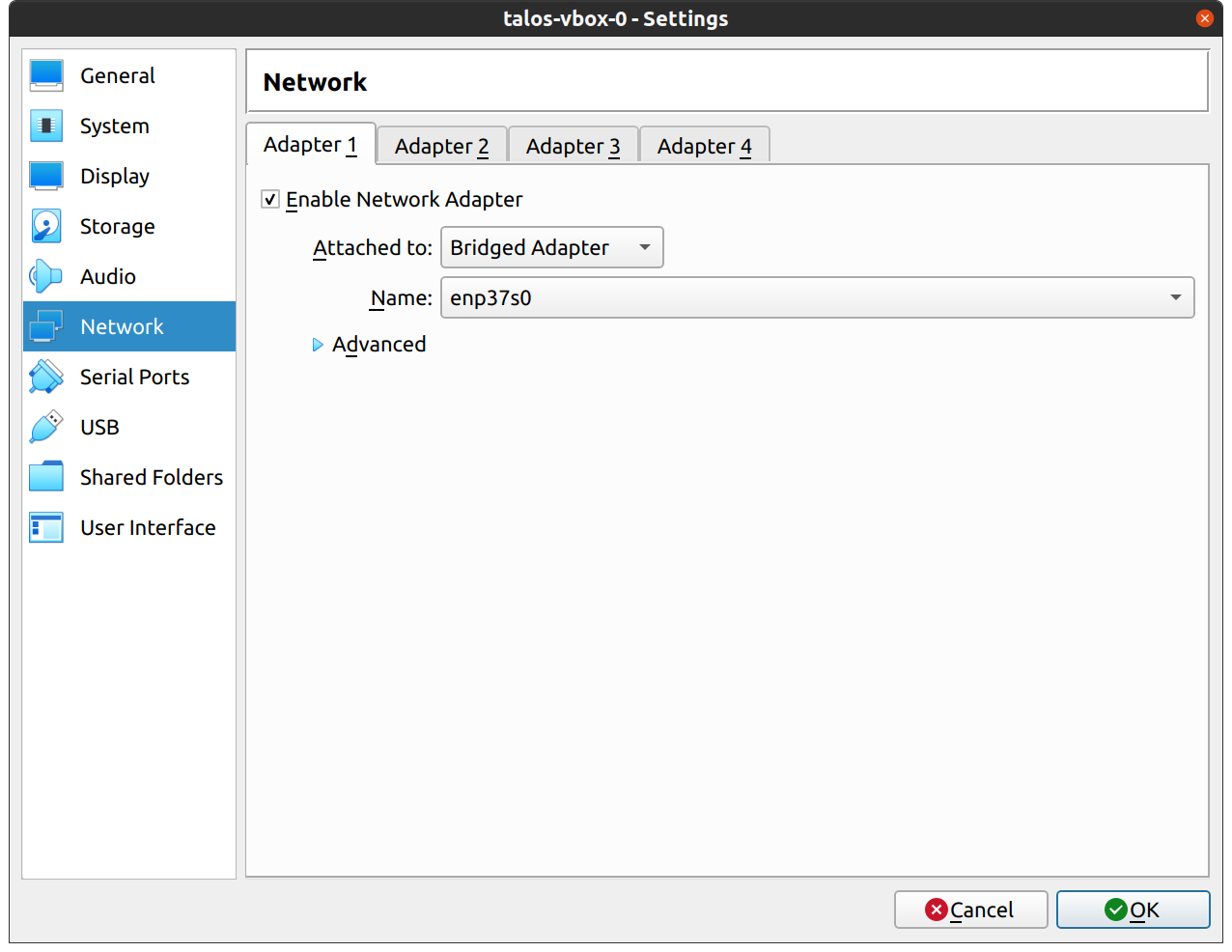
Keep the default values for networking, verifying that the VM is set to come up on the bridge interface:
Finish creating the VM by clicking through the “Confirm” tab and then “Finish”.
Repeat this process for a second VM to use as a worker node.
You can also repeat this for additional nodes desired.
Note: Talos doesn’t support memory hot plugging, if creating the VM programmatically don’t enable memory hotplug on your
Talos VM’s.
Doing so will cause Talos to be unable to see all available memory and have insufficient memory to complete
installation of the cluster.
Start Control Plane Node
Once the VMs have been created and updated, start the VM that will be the first control plane node.
This VM will boot the ISO image specified earlier and enter “maintenance mode”.
With DHCP server
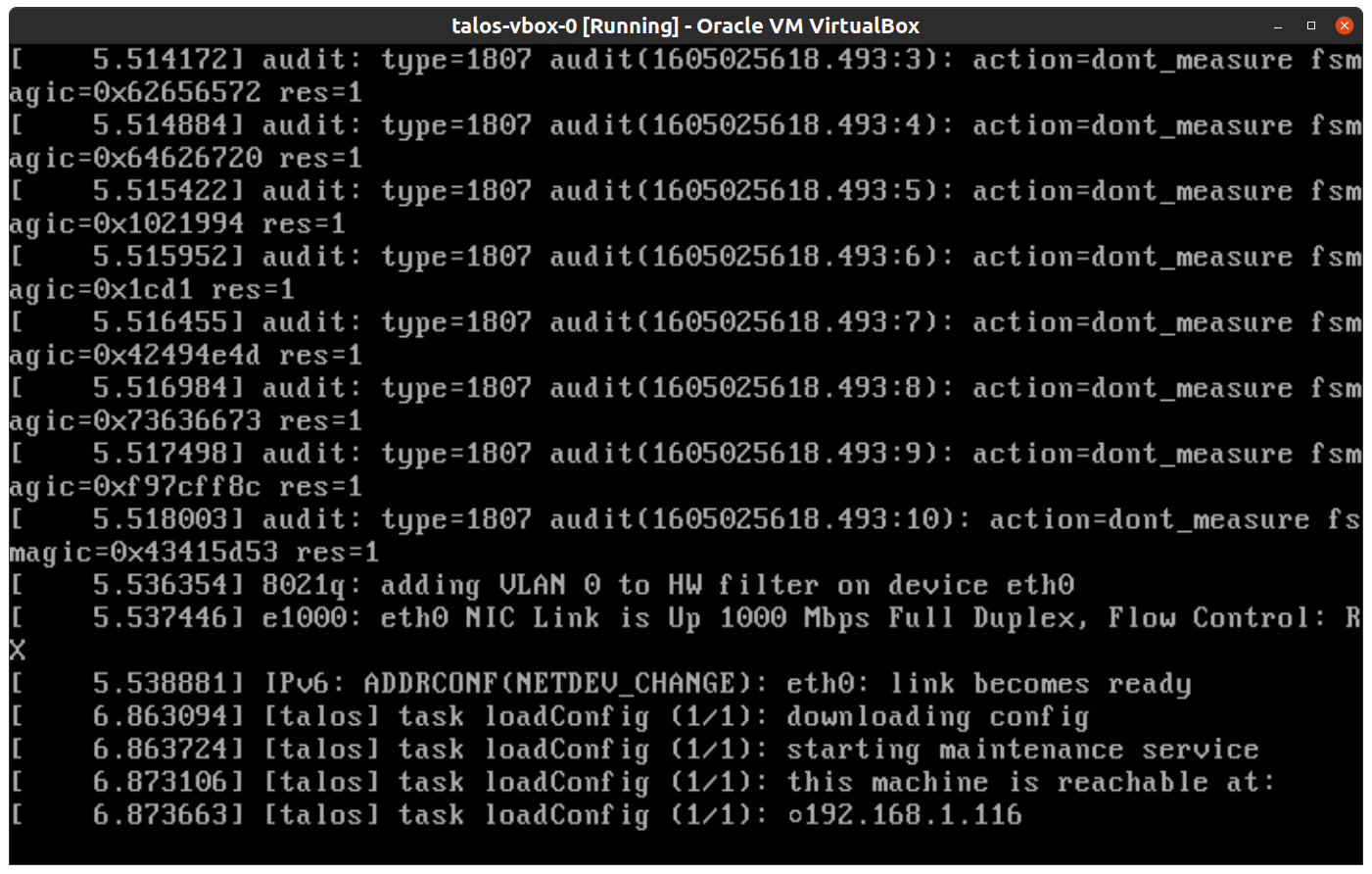
Once the machine has entered maintenance mode, there will be a console log that details the IP address that the node received.
Take note of this IP address, which will be referred to as $CONTROL_PLANE_IP for the rest of this guide.
If you wish to export this IP as a bash variable, simply issue a command like export CONTROL_PLANE_IP=1.2.3.4.
Without DHCP server
To apply the machine configurations in maintenance mode, VM has to have IP on the network.
So you can set it on boot time manually.
Press e on the boot time.
And set the IP parameters for the VM.
Format is:
With the IP address above, you can now generate the machine configurations to use for installing Talos and Kubernetes.
Issue the following command, updating the output directory, cluster name, and control plane IP as you see fit:
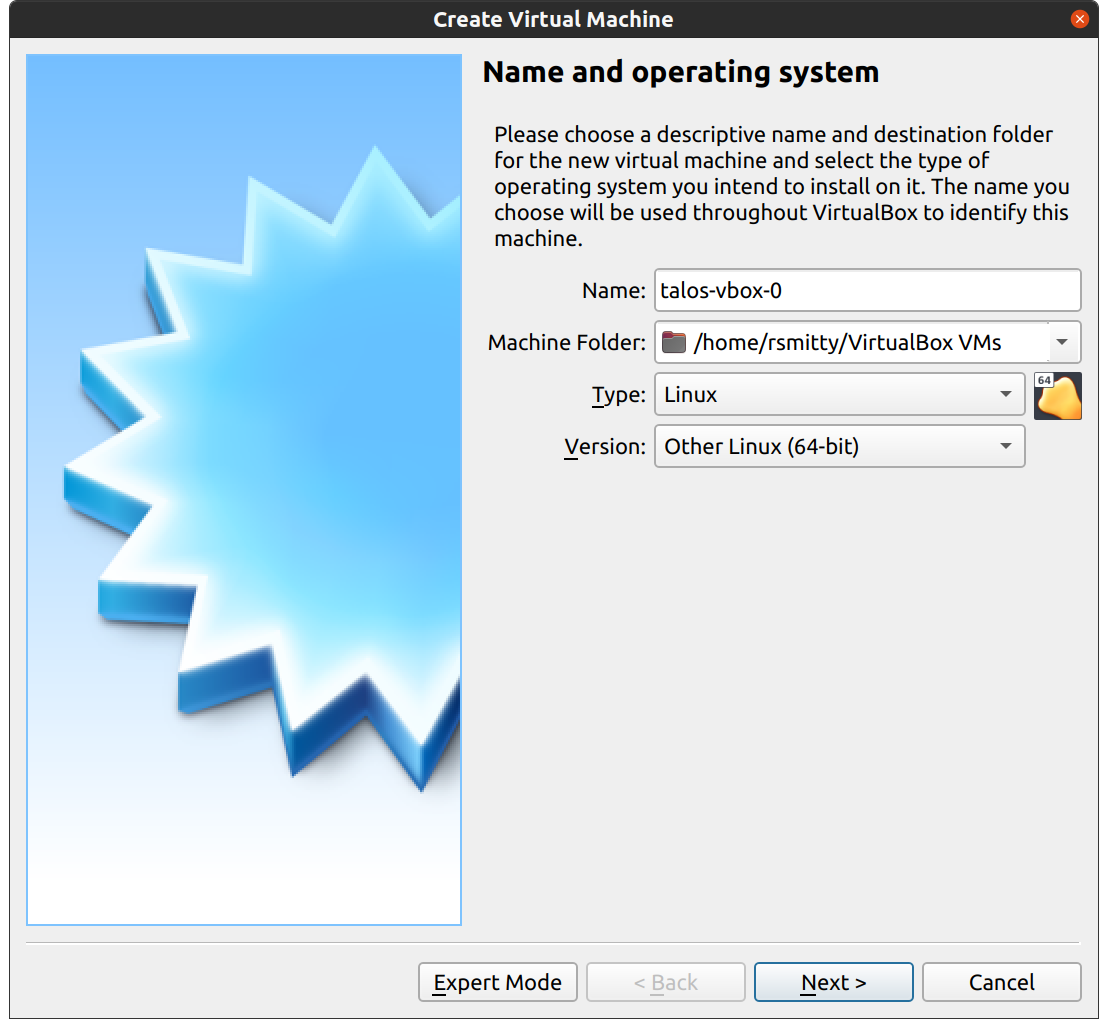
talosctl gen config talos-vbox-cluster https://$CONTROL_PLANE_IP:6443 --output-dir _out
This will create several files in the _out directory: controlplane.yaml, worker.yaml, and talosconfig.
Note: The Talos config by default will install to /dev/sda.
Depending on your setup the virtual disk may be mounted differently Eg: /dev/vda.
You can check for disks running the following command:
You should now see some action in the Proxmox console for this VM.
Talos will be installed to disk, the VM will reboot, and then Talos will configure the Kubernetes control plane on this VM.
Note: This process can be repeated multiple times to create an HA control plane.
Create Worker Node
Create at least a single worker node using a process similar to the control plane creation above.
Start the worker node VM and wait for it to enter “maintenance mode”.
Take note of the worker node’s IP address, which will be referred to as $WORKER_IP
Note: This process can be repeated multiple times to add additional workers.
Using the Cluster
Once the cluster is available, you can make use of talosctl and kubectl to interact with the cluster.
For example, to view current running containers, run talosctl containers for a list of containers in the system namespace, or talosctl containers -k for the k8s.io namespace.
To view the logs of a container, use talosctl logs <container> or talosctl logs -k <container>.
First, configure talosctl to talk to your control plane node by issuing the following, updating paths and IPs as necessary:
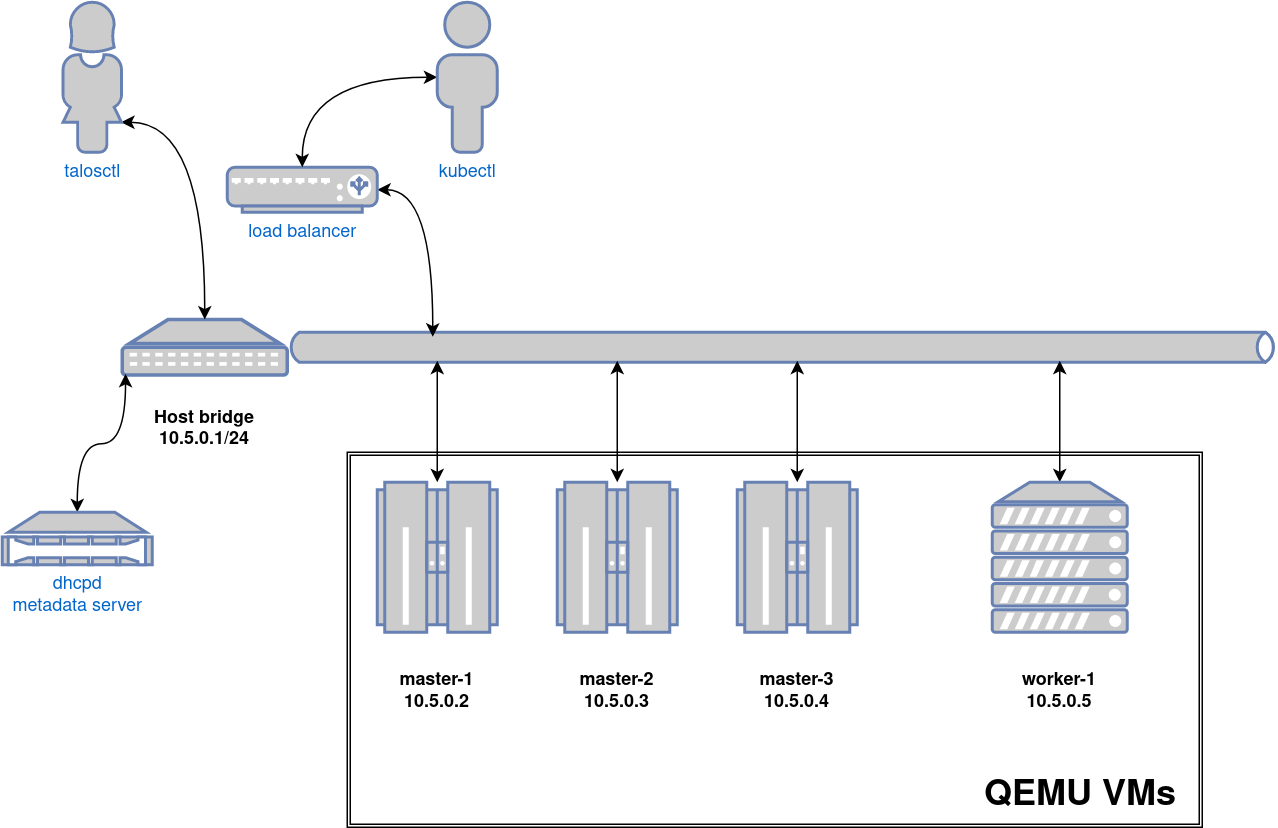
We will use Vagrant and its libvirt plugin to create a KVM-based cluster with 3 control plane nodes and 1 worker node.
For this, we will mount Talos ISO into the VMs using a virtual CD-ROM,
and configure the VMs to attempt to boot from the disk first with the fallback to the CD-ROM.
We will also configure a virtual IP address on Talos to achieve high-availability on kube-apiserver.
Preparing the environment
First, we download the latest talos-amd64.iso ISO from GitHub releases into the /tmp directory.
Current machine states:
control-plane-node-1 not created (libvirt)
control-plane-node-2 not created (libvirt)
control-plane-node-3 not created (libvirt)
worker-node-1 not created (libvirt)
Congratulations, you have a highly-available Talos cluster running!
Cleanup
You can destroy the vagrant environment by running:
vagrant destroy -f
And remove the ISO image you downloaded:
sudo rm -f /tmp/talos-amd64.iso
2.1.2.5 - VMware
Creating Talos Kubernetes cluster using VMware.
Creating a Cluster via the govc CLI
In this guide we will create an HA Kubernetes cluster with 2 worker nodes.
We will use the govc cli which can be downloaded here.
Prereqs/Assumptions
This guide will use the virtual IP (“VIP”) functionality that is built into Talos in order to provide a stable, known IP for the Kubernetes control plane.
This simply means the user should pick an IP on their “VM Network” to designate for this purpose and keep it handy for future steps.
Create the Machine Configuration Files
Generating Base Configurations
Using the VIP chosen in the prereq steps, we will now generate the base configuration files for the Talos machines.
This can be done with the talosctl gen config ... command.
Take note that we will also use a JSON6902 patch when creating the configs so that the control plane nodes get some special information about the VIP we chose earlier, as well as a daemonset to install vmware tools on talos nodes.
First, download cp.patch.yaml to your local machine and edit the VIP to match your chosen IP.
You can do this by issuing: curl -fsSLO https://raw.githubusercontent.com/siderolabs/talos/master/website/content/v1.4/talos-guides/install/virtualized-platforms/vmware/cp.patch.yaml.
It’s contents should look like the following:
With the patch in hand, generate machine configs with:
$ talosctl gen config vmware-test https://<VIP>:<port> --config-patch-control-plane @cp.patch.yaml
created controlplane.yaml
created worker.yaml
created talosconfig
At this point, you can modify the generated configs to your liking if needed.
Optionally, you can specify additional patches by adding to the cp.patch.yaml file downloaded earlier, or create your own patch files.
Validate the Configuration Files
$ talosctl validate --config controlplane.yaml --mode cloud
controlplane.yaml is valid for cloud mode
$ talosctl validate --config worker.yaml --mode cloud
worker.yaml is valid for cloud mode
Set Environment Variables
govc makes use of the following environment variables
As part of this guide, we have a more automated install script that handles some of the complexity of importing OVAs and creating VMs.
If you wish to use this script, we will detail that next.
If you wish to carry out the manual approach, simply skip ahead to the “Manual Approach” section.
Scripted Install
Download the vmware.sh script to your local machine.
You can do this by issuing curl -fsSLO "https://raw.githubusercontent.com/siderolabs/talos/master/website/content/v1.4/talos-guides/install/virtualized-platforms/vmware/vmware.sh".
This script has default variables for things like Talos version and cluster name that may be interesting to tweak before deploying.
Import OVA
To create a content library and import the Talos OVA corresponding to the mentioned Talos version, simply issue:
./vmware.sh upload_ova
Create Cluster
With the OVA uploaded to the content library, you can create a 5 node (by default) cluster with 3 control plane and 2 worker nodes:
./vmware.sh create
This step will create a VM from the OVA, edit the settings based on the env variables used for VM size/specs, then power on the VMs.
You may now skip past the “Manual Approach” section down to “Bootstrap Cluster”.
Manual Approach
Import the OVA into vCenter
A talos.ova asset is published with each release.
We will refer to the version of the release as $TALOS_VERSION below.
It can be easily exported with export TALOS_VERSION="v0.3.0-alpha.10" or similar.
Talos makes use of the guestinfo facility of VMware to provide the machine/cluster configuration.
This can be set using the govc vm.change command.
To facilitate persistent storage using the vSphere cloud provider integration with Kubernetes, disk.enableUUID=1 is used.
In the vSphere UI, open a console to one of the control plane nodes.
You should see some output stating that etcd should be bootstrapped.
This text should look like:
"etcd is waiting to join the cluster, if this node is the first node in the cluster, please run `talosctl bootstrap` against one of the following IPs:
The talos-vmtoolsd application was deployed as a daemonset as part of the cluster creation; however, we must now provide a talos credentials file for it to use.
Once configured, you should now see these daemonset pods go into “Running” state and in vCenter, you will now see IPs and info from the Talos nodes present in the UI.
2.1.2.6 - Xen
Talos is known to work on Xen.
We don’t yet have a documented guide specific to Xen; however, you can follow the General Getting Started Guide.
If you run into any issues, our community can probably help!
2.1.3 - Cloud Platforms
Installation of Talos Linux on many cloud platforms.
2.1.3.1 - AWS
Creating a cluster via the AWS CLI.
Creating a Cluster via the AWS CLI
In this guide we will create an HA Kubernetes cluster with 3 worker nodes.
We assume an existing VPC, and some familiarity with AWS.
If you need more information on AWS specifics, please see the official AWS documentation.
Set the needed info
Change to your desired region:
REGION="us-west-2"aws ec2 describe-vpcs --region $REGIONVPC="(the VpcId from the above command)"
Create the Subnet
Use a CIDR block that is present on the VPC specified above.
Replace amd64 in the line above with the desired architecture.
Note the AMI id that is returned is assigned to an environment variable: it will be used later when booting instances.
We now have an AMI we can use to create our cluster.
Save the AMI ID, as we will need it when we create EC2 instances.
AMI="(AMI ID of the register image command)"
Create a Security Group
aws ec2 create-security-group \
--region $REGION\
--group-name talos-aws-tutorial-sg \
--description "Security Group for EC2 instances to allow ports required by Talos"SECURITY_GROUP="(security group id that is returned)"
Using the security group from above, allow all internal traffic within the same security group:
Using the DNS name of the loadbalancer created earlier, generate the base configuration files for the Talos machines.
Note that the port used here is the externally accessible port configured on the load balancer - 443 - not the internal port of 6443:
$ talosctl gen config talos-k8s-aws-tutorial https://<load balancer DNS>:<port> --with-examples=false --with-docs=falsecreated controlplane.yaml
created worker.yaml
created talosconfig
Note that the generated configs are too long for AWS userdata field if the --with-examples and --with-docs flags are not passed.
At this point, you can modify the generated configs to your liking.
Optionally, you can specify --config-patch with RFC6902 jsonpatch which will be applied during the config generation.
Validate the Configuration Files
$ talosctl validate --config controlplane.yaml --mode cloud
controlplane.yaml is valid for cloud mode
$ talosctl validate --config worker.yaml --mode cloud
worker.yaml is valid for cloud mode
Create the EC2 Instances
change the instance type if desired.
Note: There is a known issue that prevents Talos from running on T2 instance types.
Please use T3 if you need burstable instance types.
Set the endpoints (the control plane node to which talosctl commands are sent) and nodes (the nodes that the command operates on):
talosctl --talosconfig talosconfig config endpoint <control plane 1 PUBLIC IP>
talosctl --talosconfig talosconfig config node <control plane 1 PUBLIC IP>
Bootstrap etcd:
talosctl --talosconfig talosconfig bootstrap
Retrieve the kubeconfig
At this point we can retrieve the admin kubeconfig by running:
talosctl --talosconfig talosconfig kubeconfig .
The different control plane nodes should sendi/receive traffic via the load balancer, notice that one of the control plane has intiated the etcd cluster, and the others should join.
You can now watch as your cluster bootstraps, by using
talosctl --talosconfig talosconfig health
You can also watch the performance of a node, via:
talosctl --talosconfig talosconfig dashboard
And use standard kubectl commands.
2.1.3.2 - Azure
Creating a cluster via the CLI on Azure.
Creating a Cluster via the CLI
In this guide we will create an HA Kubernetes cluster with 1 worker node.
We assume existing Blob Storage, and some familiarity with Azure.
If you need more information on Azure specifics, please see the official Azure documentation.
Environment Setup
We’ll make use of the following environment variables throughout the setup.
Edit the variables below with your correct information.
# Storage account to useexportSTORAGE_ACCOUNT="StorageAccountName"# Storage container to upload toexportSTORAGE_CONTAINER="StorageContainerName"# Resource group nameexportGROUP="ResourceGroupName"# LocationexportLOCATION="centralus"# Get storage account connection string based on info aboveexportCONNECTION=$(az storage account show-connection-string \
-n $STORAGE_ACCOUNT\
-g $GROUP\
-o tsv)
Create the Image
First, download the Azure image from a Talos release.
Once downloaded, untar with tar -xvf /path/to/azure-amd64.tar.gz
Upload the VHD
Once you have pulled down the image, you can upload it to blob storage with:
Now that the image is present in our blob storage, we’ll register it.
az image create \
--name talos \
--source https://$STORAGE_ACCOUNT.blob.core.windows.net/$STORAGE_CONTAINER/talos-azure.vhd \
--os-type linux \
-g $GROUP
Network Infrastructure
Virtual Networks and Security Groups
Once the image is prepared, we’ll want to work through setting up the network.
Issue the following to create a network security group and add rules to it.
In Azure, we have to pre-create the NICs for our control plane so that they can be associated with our load balancer.
for i in $( seq 012); do# Create public IP for each nic az network public-ip create \
--resource-group $GROUP\
--name talos-controlplane-public-ip-$i\
--allocation-method static
# Create nic az network nic create \
--resource-group $GROUP\
--name talos-controlplane-nic-$i\
--vnet-name talos-vnet \
--subnet talos-subnet \
--network-security-group talos-sg \
--public-ip-address talos-controlplane-public-ip-$i\
--lb-name talos-lb \
--lb-address-pools talos-be-pool
done# NOTES:# Talos can detect PublicIPs automatically if PublicIP SKU is Basic.# Use `--sku Basic` to set SKU to Basic.
Cluster Configuration
With our networking bits setup, we’ll fetch the IP for our load balancer and create our configuration files.
LB_PUBLIC_IP=$(az network public-ip show \
--resource-group $GROUP\
--name talos-public-ip \
--query [ipAddress]\
--output tsv)talosctl gen config talos-k8s-azure-tutorial https://${LB_PUBLIC_IP}:6443
Compute Creation
We are now ready to create our azure nodes.
Azure allows you to pass Talos machine configuration to the virtual machine at bootstrap time via
user-data or custom-data methods.
Talos supports only custom-data method, machine configuration is available to the VM only on the first boot.
# Create availability setaz vm availability-set create \
--name talos-controlplane-av-set \
-g $GROUP# Create the controlplane nodesfor i in $( seq 012); do az vm create \
--name talos-controlplane-$i\
--image talos \
--custom-data ./controlplane.yaml \
-g $GROUP\
--admin-username talos \
--generate-ssh-keys \
--verbose \
--boot-diagnostics-storage $STORAGE_ACCOUNT\
--os-disk-size-gb 20\
--nics talos-controlplane-nic-$i\
--availability-set talos-controlplane-av-set \
--no-wait
done# Create worker node az vm create \
--name talos-worker-0 \
--image talos \
--vnet-name talos-vnet \
--subnet talos-subnet \
--custom-data ./worker.yaml \
-g $GROUP\
--admin-username talos \
--generate-ssh-keys \
--verbose \
--boot-diagnostics-storage $STORAGE_ACCOUNT\
--nsg talos-sg \
--os-disk-size-gb 20\
--no-wait
# NOTES:# `--admin-username` and `--generate-ssh-keys` are required by the az cli,# but are not actually used by talos# `--os-disk-size-gb` is the backing disk for Kubernetes and any workload containers# `--boot-diagnostics-storage` is to enable console output which may be necessary# for troubleshooting
Bootstrap Etcd
You should now be able to interact with your cluster with talosctl.
We will need to discover the public IP for our first control plane node first.
At this point we can retrieve the admin kubeconfig by running:
talosctl --talosconfig talosconfig kubeconfig .
2.1.3.3 - DigitalOcean
Creating a cluster via the CLI on DigitalOcean.
Creating a Talos Linux Cluster on Digital Ocean via the CLI
In this guide we will create an HA Kubernetes cluster with 1 worker node, in the NYC region.
We assume an existing Space, and some familiarity with DigitalOcean.
If you need more information on DigitalOcean specifics, please see the official DigitalOcean documentation.
Create the Image
Download the DigitalOcean image digital-ocean-amd64.raw.gz from the latest Talos release.
Note: the minimum version of Talos required to support Digital Ocean is v1.3.3.
Using an upload method of your choice (doctl does not have Spaces support), upload the image to a space.
(It’s easy to drag the image file to the space using DigitalOcean’s web console.)
Note: Make sure you upload the file as public.
Now, create an image using the URL of the uploaded image:
We will need the IP of the load balancer.
Using the ID of the load balancer, run:
doctl compute load-balancer get --format IP <load balancer ID>
Note that it may take a few minutes before the load balancer is provisioned, so repeat this command until it returns with the IP address.
Create the Machine Configuration Files
Using the IP address (or DNS name, if you have created one) of the loadbalancer, generate the base configuration files for the Talos machines.
Also note that the load balancer forwards port 443 to port 6443 on the associated nodes, so we should use 443 as the port in the config definition:
$ talosctl gen config talos-k8s-digital-ocean-tutorial https://<load balancer IP or DNS>:443
created controlplane.yaml
created worker.yaml
created talosconfig
Create the Droplets
Create a dummy SSH key
Although SSH is not used by Talos, DigitalOcean requires that an SSH key be associated with a droplet during creation.
We will create a dummy key that can be used to satisfy this requirement.
At this point we can retrieve the admin kubeconfig by running:
talosctl --talosconfig talosconfig kubeconfig .
We can also watch the cluster bootstrap via:
talosctl --talosconfig talosconfig health
2.1.3.4 - Exoscale
Creating a cluster via the CLI using exoscale.com
Talos is known to work on exoscale.com; however, it is currently undocumented.
2.1.3.5 - GCP
Creating a cluster via the CLI on Google Cloud Platform.
Creating a Cluster via the CLI
In this guide, we will create an HA Kubernetes cluster in GCP with 1 worker node.
We will assume an existing Cloud Storage bucket, and some familiarity with Google Cloud.
If you need more information on Google Cloud specifics, please see the official Google documentation.
Once the image is prepared, we’ll want to work through setting up the network.
Issue the following to create a firewall, load balancer, and their required components.
Using GCP deployment manager automatically creates a Google Storage bucket and uploads the Talos image to it.
Once the deployment is complete the generated talosconfig and kubeconfig files are uploaded to the bucket.
By default this setup creates a three node control plane and a single worker in us-west1-b
First we need to create a folder to store our deployment manifests and perform all subsequent operations from that folder.
mkdir -p talos-gcp-deployment
cd talos-gcp-deployment
Getting the deployment manifests
We need to download two deployment manifests for the deployment from the Talos github repository.
curl -fsSLO "https://raw.githubusercontent.com/siderolabs/talos/master/website/content/v1.4/talos-guides/install/cloud-platforms/gcp/config.yaml"curl -fsSLO "https://raw.githubusercontent.com/siderolabs/talos/master/website/content/v1.4/talos-guides/install/cloud-platforms/gcp/talos-ha.jinja"# if using ccmcurl -fsSLO "https://raw.githubusercontent.com/siderolabs/talos/master/website/content/v1.4/talos-guides/install/cloud-platforms/gcp/gcp-ccm.yaml"
Updating the config
Now we need to update the local config.yaml file with any required changes such as changing the default zone, Talos version, machine sizes, nodes count etc.
Note: The externalCloudProvider property is set to false by default.
The manifest used for deploying the ccm (cloud controller manager) is currently using the GCP ccm provided by openshift since there are no public images for the ccm yet.
Since the routes controller is disabled while deploying the CCM, the CNI pods needs to be restarted after the CCM deployment is complete to remove the node.kubernetes.io/network-unavailable taint.
See Nodes network-unavailable taint not removed after installing ccm for more information
Use a custom built image for the ccm deployment if required.
Creating the deployment
Now we are ready to create the deployment.
Confirm with y for any prompts.
Run the following command to create the deployment:
# use a unique name for the deployment, resources are prefixed with the deployment nameexportDEPLOYMENT_NAME="<deployment name>"gcloud deployment-manager deployments create "${DEPLOYMENT_NAME}" --config config.yaml
Retrieving the outputs
First we need to get the deployment outputs.
# first get the outputsOUTPUTS=$(gcloud deployment-manager deployments describe "${DEPLOYMENT_NAME}" --format json | jq '.outputs[]')BUCKET_NAME=$(jq -r '. | select(.name == "bucketName").finalValue'<<<"${OUTPUTS}")# used when cloud controller is enabledSERVICE_ACCOUNT=$(jq -r '. | select(.name == "serviceAccount").finalValue'<<<"${OUTPUTS}")PROJECT=$(jq -r '. | select(.name == "project").finalValue'<<<"${OUTPUTS}")
Note: If cloud controller manager is enabled, the below command needs to be run to allow the controller custom role to access cloud resources
In addition to the talosconfig and kubeconfig files, the storage bucket contains the controlplane.yaml and worker.yaml files used to join additional nodes to the cluster.
kubectl \
--kubeconfig kubeconfig \
--namespace kube-system \
apply \
--filename gcp-ccm.yaml
# wait for the ccm to be upkubectl \
--kubeconfig kubeconfig \
--namespace kube-system \
rollout status \
daemonset cloud-controller-manager
If the cloud controller manager is enabled, we need to restart the CNI pods to remove the node.kubernetes.io/network-unavailable taint.
# restart the CNI pods, in this case flannelkubectl \
--kubeconfig kubeconfig \
--namespace kube-system \
rollout restart \
daemonset kube-flannel
# wait for the pods to be restartedkubectl \
--kubeconfig kubeconfig \
--namespace kube-system \
rollout status \
daemonset kube-flannel
Check cluster status
kubectl \
--kubeconfig kubeconfig \
get nodes
Cleanup deployment
Warning: This will delete the deployment and all resources associated with it.
# delete the objects in the bucket firstgsutil -m rm -r "gs://${BUCKET_NAME}"gcloud deployment-manager deployments delete "${DEPLOYMENT_NAME}" --quiet
2.1.3.6 - Hetzner
Creating a cluster via the CLI (hcloud) on Hetzner.
Upload image
Hetzner Cloud does not support uploading custom images.
You can email their support to get a Talos ISO uploaded by following issues:3599 or you can prepare image snapshot by yourself.
There are two options to upload your own.
Run an instance in rescue mode and replace the system OS with the Talos image
Create a new Server in the Hetzner console.
Enable the Hetzner Rescue System for this server and reboot.
Upon a reboot, the server will boot a special minimal Linux distribution designed for repair and reinstall.
Once running, login to the server using ssh to prepare the system disk by doing the following:
# Check that you in Rescue modedf
### Result is like:# udev 987432 0 987432 0% /dev# 213.133.99.101:/nfs 308577696 247015616 45817536 85% /root/.oldroot/nfs# overlay 995672 8340 987332 1% /# tmpfs 995672 0 995672 0% /dev/shm# tmpfs 398272 572 397700 1% /run# tmpfs 5120 0 5120 0% /run/lock# tmpfs 199132 0 199132 0% /run/user/0# Download the Talos imagecd /tmp
wget -O /tmp/talos.raw.xz https://github.com/siderolabs/talos/releases/download/v1.4.8/hcloud-amd64.raw.xz
# Replace systemxz -d -c /tmp/talos.raw.xz | dd of=/dev/sda && sync
# shutdown the instanceshutdown -h now
To make sure disk content is consistent, it is recommended to shut the server down before taking an image (snapshot).
Once shutdown, simply create an image (snapshot) from the console.
You can now use this snapshot to run Talos on the cloud.
Create a new image by issuing the commands shown below.
Note that to create a new API token for your Project, switch into the Hetzner Cloud Console choose a Project, go to Access → Security, and create a new token.
# First you need set API TokenexportHCLOUD_TOKEN=${TOKEN}# Upload imagepacker init .
packer build .
# Save the image IDexportIMAGE_ID=<image-id-in-packer-output>
After doing this, you can find the snapshot in the console interface.
Using the IP/DNS name of the loadbalancer created earlier, generate the base configuration files for the Talos machines by issuing:
$ talosctl gen config talos-k8s-hcloud-tutorial https://<load balancer IP or DNS>:6443
created controlplane.yaml
created worker.yaml
created talosconfig
At this point, you can modify the generated configs to your liking.
Optionally, you can specify --config-patch with RFC6902 jsonpatches which will be applied during the config generation.
Validate the Configuration Files
Validate any edited machine configs with:
$ talosctl validate --config controlplane.yaml --mode cloud
controlplane.yaml is valid for cloud mode
$ talosctl validate --config worker.yaml --mode cloud
worker.yaml is valid for cloud mode
Create the Servers
We can now create our servers.
Note that you can find IMAGE_ID in the snapshot section of the console: https://console.hetzner.cloud/projects/$PROJECT_ID/servers/snapshots.
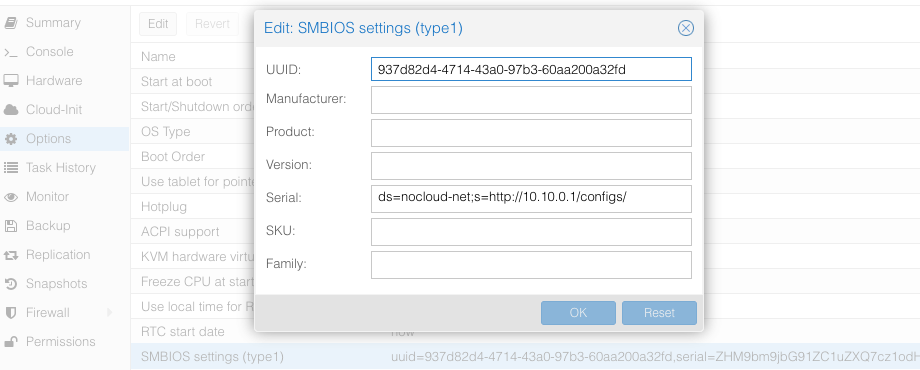
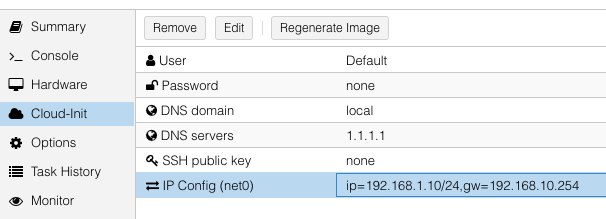
Proxmox can create cloud-init disk for you.
Edit the cloud-init config information in Proxmox as follows, substitute your own information as necessary:
and then update cicustom param at /etc/pve/qemu-server/$ID.conf.
cicustom: user=local:snippets/controlplane-1.yml
ipconfig0: ip=192.168.1.10/24,gw=192.168.10.254
nameserver: 1.1.1.1
searchdomain: local
Note: snippets/controlplane-1.yml is Talos machine config.
It is usually located at /var/lib/vz/snippets/controlplane-1.yml.
This file must be placed to this path manually, as Proxmox does not support snippet uploading via API/GUI.
Click on Regenerate Image button after the above changes are made.
2.1.3.8 - OpenStack
Creating a cluster via the CLI on OpenStack.
Creating a Cluster via the CLI
In this guide, we will create an HA Kubernetes cluster in OpenStack with 1 worker node.
We will assume an existing some familiarity with OpenStack.
If you need more information on OpenStack specifics, please see the official OpenStack documentation.
Environment Setup
You should have an existing openrc file.
This file will provide environment variables necessary to talk to your OpenStack cloud.
See here for instructions on fetching this file.
Create the Image
First, download the OpenStack image from a Talos release.
These images are called openstack-$ARCH.tar.gz.
Untar this file with tar -xvf openstack-$ARCH.tar.gz.
The resulting file will be called disk.raw.
Upload the Image
Once you have the image, you can upload to OpenStack with:
openstack image create --public --disk-format raw --file disk.raw talos
Network Infrastructure
Load Balancer and Network Ports
Once the image is prepared, you will need to work through setting up the network.
Issue the following to create a load balancer, the necessary network ports for each control plane node, and associations between the two.
Creating loadbalancer:
# Create load balancer, updating vip-subnet-id if necessaryopenstack loadbalancer create --name talos-control-plane --vip-subnet-id public
# Create listeneropenstack loadbalancer listener create --name talos-control-plane-listener --protocol TCP --protocol-port 6443 talos-control-plane
# Pool and health monitoringopenstack loadbalancer pool create --name talos-control-plane-pool --lb-algorithm ROUND_ROBIN --listener talos-control-plane-listener --protocol TCP
openstack loadbalancer healthmonitor create --delay 5 --max-retries 4 --timeout 10 --type TCP talos-control-plane-pool
Creating ports:
# Create ports for control plane nodes, updating network name if necessaryopenstack port create --network shared talos-control-plane-1
openstack port create --network shared talos-control-plane-2
openstack port create --network shared talos-control-plane-3
# Create floating IPs for the ports, so that you will have talosctl connectivity to each control planeopenstack floating ip create --port talos-control-plane-1 public
openstack floating ip create --port talos-control-plane-2 public
openstack floating ip create --port talos-control-plane-3 public
Note: Take notice of the private and public IPs associated with each of these ports, as they will be used in the next step.
Additionally, take node of the port ID, as it will be used in server creation.
Associate port’s private IPs to loadbalancer:
# Create members for each port IP, updating subnet-id and address as necessary.openstack loadbalancer member create --subnet-id shared-subnet --address <PRIVATE IP OF talos-control-plane-1 PORT> --protocol-port 6443 talos-control-plane-pool
openstack loadbalancer member create --subnet-id shared-subnet --address <PRIVATE IP OF talos-control-plane-2 PORT> --protocol-port 6443 talos-control-plane-pool
openstack loadbalancer member create --subnet-id shared-subnet --address <PRIVATE IP OF talos-control-plane-3 PORT> --protocol-port 6443 talos-control-plane-pool
Security Groups
This example uses the default security group in OpenStack.
Ports have been opened to ensure that connectivity from both inside and outside the group is possible.
You will want to allow, at a minimum, ports 6443 (Kubernetes API server) and 50000 (Talos API) from external sources.
It is also recommended to allow communication over all ports from within the subnet.
Cluster Configuration
With our networking bits setup, we’ll fetch the IP for our load balancer and create our configuration files.
LB_PUBLIC_IP=$(openstack loadbalancer show talos-control-plane -f json | jq -r .vip_address)talosctl gen config talos-k8s-openstack-tutorial https://${LB_PUBLIC_IP}:6443
Additionally, you can specify --config-patch with RFC6902 jsonpatch which will be applied during the config generation.
Compute Creation
We are now ready to create our OpenStack nodes.
Create control plane:
# Create control planes 2 and 3, substituting the same info.for i in $( seq 13); do openstack server create talos-control-plane-$i --flavor m1.small --nic port-id=talos-control-plane-$i --image talos --user-data /path/to/controlplane.yaml
done
Create worker:
# Update network name as necessary.openstack server create talos-worker-1 --flavor m1.small --network shared --image talos --user-data /path/to/worker.yaml
Note: This step can be repeated to add more workers.
Bootstrap Etcd
You should now be able to interact with your cluster with talosctl.
We will use one of the floating IPs we allocated earlier.
It does not matter which one.
Using the IP/DNS name of the loadbalancer created earlier, generate the base configuration files for the Talos machines by issuing:
$ talosctl gen config talos-k8s-oracle-tutorial https://<load balancer IP or DNS>:6443 --additional-sans <load balancer IP or DNS>
created controlplane.yaml
created worker.yaml
created talosconfig
At this point, you can modify the generated configs to your liking.
Optionally, you can specify --config-patch with RFC6902 jsonpatches which will be applied during the config generation.
Validate the Configuration Files
Validate any edited machine configs with:
$ talosctl validate --config controlplane.yaml --mode cloud
controlplane.yaml is valid for cloud mode
$ talosctl validate --config worker.yaml --mode cloud
worker.yaml is valid for cloud mode
Set the endpoints and nodes for your talosconfig with:
talosctl --talosconfig talosconfig config endpoint <load balancer IP or DNS>
talosctl --talosconfig talosconfig config node <control-plane-1-IP>
Bootstrap etcd on the first control plane node with:
talosctl --talosconfig talosconfig bootstrap
Retrieve the kubeconfig
At this point we can retrieve the admin kubeconfig by running:
talosctl --talosconfig talosconfig kubeconfig .
2.1.3.10 - Scaleway
Creating a cluster via the CLI (scw) on scaleway.com.
Talos is known to work on scaleway.com; however, it is currently undocumented.
2.1.3.11 - UpCloud
Creating a cluster via the CLI (upctl) on UpCloud.com.
In this guide we will create an HA Kubernetes cluster 3 control plane nodes and 1 worker node.
We assume some familiarity with UpCloud.
If you need more information on UpCloud specifics, please see the official UpCloud documentation.
Create the Image
The best way to create an image for UpCloud, is to build one using
Hashicorp packer, with the
upcloud-amd64.raw.xz image found on the Talos Releases.
Using the general ISO is also possible, but the UpCloud image has some UpCloud
specific features implemented, such as the fetching of metadata and user data to configure the nodes.
To create the cluster, you need a few things locally installed:
NOTE: Make sure your account allows API connections.
To do so, log into
UpCloud control panel and go to People
-> Account -> Permissions -> Allow API connections checkbox.
It is recommended
to create a separate subaccount for your API access and only set the API permission.
To use the UpCloud CLI, you need to create a config in $HOME/.config/upctl.yaml
To use the UpCloud packer plugin, you need to also export these credentials to your
environment variables, by e.g. putting the following in your .bashrc or .zshrc
Now create a new image by issuing the commands shown below.
packer init .
packer build .
After doing this, you can find the custom image in the console interface under storage.
Creating a Cluster via the CLI
Create an Endpoint
To communicate with the Talos cluster you will need a single endpoint that is used
to access the cluster.
This can either be a loadbalancer that will sit in front of
all your control plane nodes, a DNS name with one or more A or AAAA records pointing
to the control plane nodes, or directly the IP of a control plane node.
Which option is best for you will depend on your needs.
Endpoint selection has been further documented here.
After you decide on which endpoint to use, note down the domain name or IP, as
we will need it in the next step.
Create the Machine Configuration Files
Generating Base Configurations
Using the DNS name of the endpoint created earlier, generate the base
configuration files for the Talos machines:
$ talosctl gen config talos-upcloud-tutorial https://<load balancer IP or DNS>:<port> --install-disk /dev/vda
created controlplane.yaml
created worker.yaml
created talosconfig
At this point, you can modify the generated configs to your liking.
Depending on the Kubernetes version you want to run, you might need to select a different Talos version, as not all versions are compatible.
You can find the support matrix here.
Optionally, you can specify --config-patch with RFC6902 jsonpatch or yamlpatch
which will be applied during the config generation.
Validate the Configuration Files
$ talosctl validate --config controlplane.yaml --mode cloud
controlplane.yaml is valid for cloud mode
$ talosctl validate --config worker.yaml --mode cloud
worker.yaml is valid for cloud mode
Create the Servers
Create the Control Plane Nodes
Run the following to create three total control plane nodes:
for ID in $(seq 3); do upctl server create \
--zone us-nyc1 \
--title talos-us-nyc1-master-$ID\
--hostname talos-us-nyc1-master-$ID\
--plan 2xCPU-4GB \
--os "Talos (v1.4.8)"\
--user-data "$(cat controlplane.yaml)"\
--enable-metada
done
Note: modify the zone and OS depending on your preferences.
The OS should match the template name generated with packer in the previous step.
Note the IP address of the first control plane node, as we will need it later.
To configure talosctl we will need the first control plane node’s IP, as noted earlier.
We only add one node IP, as that is the entry into our cluster against which our commands will be run.
All requests to other nodes are proxied through the endpoint, and therefore not
all nodes need to be manually added to the config.
You don’t want to run your commands against all nodes, as this can destroy your
cluster if you are not careful (further documentation).
At this point we can retrieve the admin kubeconfig by running:
talosctl --talosconfig talosconfig kubeconfig
It will take a few minutes before Kubernetes has been fully bootstrapped, and is accessible.
You can check if the nodes are registered in Talos by running
talosctl --talosconfig talosconfig get members
To check if your nodes are ready, run
kubectl get nodes
2.1.3.12 - Vultr
Creating a cluster via the CLI (vultr-cli) on Vultr.com.
Creating a Cluster using the Vultr CLI
This guide will demonstrate how to create a highly-available Kubernetes cluster with one worker using the Vultr cloud provider.
Vultr have a very well documented REST API, and an open-source CLI tool to interact with the API which will be used in this guide.
Make sure to follow installation and authentication instructions for the vultr-cli tool.
Upload image
First step is to make the Talos ISO available to Vultr by uploading the latest release of the ISO to the Vultr ISO server.
vultr-cli iso create --url https://github.com/siderolabs/talos/releases/download/v1.4.8/talos-amd64.iso
Make a note of the ID in the output, it will be needed later when creating the instances.
Create a Load Balancer
A load balancer is needed to serve as the Kubernetes endpoint for the cluster.
Make a note of the ID of the load balancer from the output of the above command, it will be needed after the control plane instances are created.
vultr-cli load-balancer get $LOAD_BALANCER_ID | grep ^IP
Make a note of the IP address, it will be needed later when generating the configuration.
Create the Machine Configuration
Generate Base Configuration
Using the IP address (or DNS name if one was created) of the load balancer created above, generate the machine configuration files for the new cluster.
talosctl gen config talos-kubernetes-vultr https://$LOAD_BALANCER_ADDRESS
Once generated, the machine configuration can be modified as necessary for the new cluster, for instance updating disk installation, or adding SANs for the certificates.
First a control plane needs to be created, with the example below creating 3 instances in a loop.
The instance type (noted by the --plan vc2-2c-4gb argument) in the example is for a minimum-spec control plane node, and should be updated to suit the cluster being created.
for id in $(seq 3); do vultr-cli instance create \
--plan vc2-2c-4gb \
--region $REGION\
--iso $TALOS_ISO_ID\
--host talos-k8s-cp${id}\
--label "Talos Kubernetes Control Plane"\
--tags talos,kubernetes,control-plane
done
Make a note of the instance IDs, as they are needed to attach to the load balancer created earlier.
Now worker nodes can be created and configured in a similar way to the control plane nodes, the difference being mainly in the machine configuration file.
Note that like with the control plane nodes, the instance type (here set by --plan vc2-1-1gb) should be changed for the actual cluster requirements.
for id in $(seq 1); do vultr-cli instance create \
--plan vc2-1c-1gb \
--region $REGION\
--iso $TALOS_ISO_ID\
--host talos-k8s-worker${id}\
--label "Talos Kubernetes Worker"\
--tags talos,kubernetes,worker
done
Once the worker is booted and in maintenance mode, the machine configuration can be applied in the following manner.
Once all the cluster nodes are correctly configured, the cluster can be bootstrapped to become functional.
It is important that the talosctl bootstrap command be executed only once and against only a single control plane node.
Finally, with the cluster fully running, the administrative kubeconfig can be retrieved from the Talos API to be saved locally.
talosctl --talosconfig talosconfig kubeconfig .
Now the kubeconfig can be used by any of the usual Kubernetes tools to interact with the Talos-based Kubernetes cluster as normal.
2.1.4 - Local Platforms
Installation of Talos Linux on local platforms, helpful for testing and developing.
2.1.4.1 - Docker
Creating Talos Kubernetes cluster using Docker.
In this guide we will create a Kubernetes cluster in Docker, using a containerized version of Talos.
Running Talos in Docker is intended to be used in CI pipelines, and local testing when you need a quick and easy cluster.
Furthermore, if you are running Talos in production, it provides an excellent way for developers to develop against the same version of Talos.
Requirements
The follow are requirements for running Talos in Docker:
Due to the fact that Talos will be running in a container, certain APIs are not available.
For example upgrade, reset, and similar APIs don’t apply in container mode.
Further, when running on a Mac in docker, due to networking limitations, VIPs are not supported.
Create the Cluster
Creating a local cluster is as simple as:
talosctl cluster create --wait
Once the above finishes successfully, your talosconfig(~/.talos/config) will be configured to point to the new cluster.
Note: Startup times can take up to a minute or more before the cluster is available.
Finally, we just need to specify which nodes you want to communicate with using talosctl.
Talosctl can operate on one or all the nodes in the cluster – this makes cluster wide commands much easier.
talosctl config nodes 10.5.0.2 10.5.0.3
Using the Cluster
Once the cluster is available, you can make use of talosctl and kubectl to interact with the cluster.
For example, to view current running containers, run talosctl containers for a list of containers in the system namespace, or talosctl containers -k for the k8s.io namespace.
To view the logs of a container, use talosctl logs <container> or talosctl logs -k <container>.
In this guide we will create a Kubernetes cluster using QEMU.
Video Walkthrough
To see a live demo of this writeup, see the video below:
Requirements
Linux
a kernel with
KVM enabled (/dev/kvm must exist)
CONFIG_NET_SCH_NETEM enabled
CONFIG_NET_SCH_INGRESS enabled
at least CAP_SYS_ADMIN and CAP_NET_ADMIN capabilities
QEMU
bridge, static and firewall CNI plugins from the standard CNI plugins, and tc-redirect-tap CNI plugin from the awslabs tc-redirect-tap installed to /opt/cni/bin (installed automatically by talosctl)
iptables
/var/run/netns directory should exist
Installation
How to get QEMU
Install QEMU with your operating system package manager.
For example, on Ubuntu for x86:
apt install qemu-system-x86 qemu-kvm
Install talosctl
Download talosctl via
curl -sL https://talos.dev/install | sh
Install Talos kernel and initramfs
QEMU provisioner depends on Talos kernel (vmlinuz) and initramfs (initramfs.xz).
These files can be downloaded from the Talos release:
Before the first cluster is created, talosctl will download the CNI bundle for the VM provisioning and install it to ~/.talos/cni directory.
Once the above finishes successfully, your talosconfig (~/.talos/config) will be configured to point to the new cluster, and kubeconfig will be
downloaded and merged into default kubectl config location (~/.kube/config).
Once the cluster is available, you can make use of talosctl and kubectl to interact with the cluster.
For example, to view current running containers, run talosctl -n 10.5.0.2 containers for a list of containers in the system namespace, or talosctl -n 10.5.0.2 containers -k for the k8s.io namespace.
To view the logs of a container, use talosctl -n 10.5.0.2 logs <container> or talosctl -n 10.5.0.2 logs -k <container>.
A bridge interface will be created, and assigned the default IP 10.5.0.1.
Each node will be directly accessible on the subnet specified at cluster creation time.
A loadbalancer runs on 10.5.0.1 by default, which handles loadbalancing for the Kubernetes APIs.
You can see a summary of the cluster state by running:
$ talosctl cluster show --provisioner qemu
PROVISIONER qemu
NAME talos-default
NETWORK NAME talos-default
NETWORK CIDR 10.5.0.0/24
NETWORK GATEWAY 10.5.0.1
NETWORK MTU 1500NODES:
NAME TYPE IP CPU RAM DISK
talos-default-controlplane-1 ControlPlane 10.5.0.2 1.00 1.6 GB 4.3 GB
talos-default-controlplane-2 ControlPlane 10.5.0.3 1.00 1.6 GB 4.3 GB
talos-default-controlplane-3 ControlPlane 10.5.0.4 1.00 1.6 GB 4.3 GB
talos-default-worker-1 Worker 10.5.0.5 1.00 1.6 GB 4.3 GB
Note: In that case that the host machine is rebooted before destroying the cluster, you may need to manually remove ~/.talos/clusters/talos-default.
Manual Clean Up
The talosctl cluster destroy command depends heavily on the clusters state directory.
It contains all related information of the cluster.
The PIDs and network associated with the cluster nodes.
If you happened to have deleted the state folder by mistake or you would like to cleanup
the environment, here are the steps how to do it manually:
Remove VM Launchers
Find the process of talosctl qemu-launch:
ps -elf | grep 'talosctl qemu-launch'
To remove the VMs manually, execute:
sudo kill -s SIGTERM <PID>
Example output, where VMs are running with PIDs 157615 and 157617
This is more tricky part as if you have already deleted the state folder.
If you didn’t then it is written in the state.yaml in the
~/.talos/clusters/<cluster-name> directory.
Start by creating a new VM by clicking the “New” button in the VirtualBox UI:
Supply a name for this VM, and specify the Type and Version:
Edit the memory to supply at least 2GB of RAM for the VM:
Proceed through the disk settings, keeping the defaults.
You can increase the disk space if desired.
Once created, select the VM and hit “Settings”:
In the “System” section, supply at least 2 CPUs:
In the “Network” section, switch the network “Attached To” section to “Bridged Adapter”:
Finally, in the “Storage” section, select the optical drive and, on the right, select the ISO by browsing your filesystem:
Repeat this process for a second VM to use as a worker node.
You can also repeat this for additional nodes desired.
Start Control Plane Node
Once the VMs have been created and updated, start the VM that will be the first control plane node.
This VM will boot the ISO image specified earlier and enter “maintenance mode”.
Once the machine has entered maintenance mode, there will be a console log that details the IP address that the node received.
Take note of this IP address, which will be referred to as $CONTROL_PLANE_IP for the rest of this guide.
If you wish to export this IP as a bash variable, simply issue a command like export CONTROL_PLANE_IP=1.2.3.4.
Generate Machine Configurations
With the IP address above, you can now generate the machine configurations to use for installing Talos and Kubernetes.
Issue the following command, updating the output directory, cluster name, and control plane IP as you see fit:
talosctl gen config talos-vbox-cluster https://$CONTROL_PLANE_IP:6443 --output-dir _out
This will create several files in the _out directory: controlplane.yaml, worker.yaml, and talosconfig.
Create Control Plane Node
Using the controlplane.yaml generated above, you can now apply this config using talosctl.
Issue:
You should now see some action in the VirtualBox console for this VM.
Talos will be installed to disk, the VM will reboot, and then Talos will configure the Kubernetes control plane on this VM.
Note: This process can be repeated multiple times to create an HA control plane.
Create Worker Node
Create at least a single worker node using a process similar to the control plane creation above.
Start the worker node VM and wait for it to enter “maintenance mode”.
Take note of the worker node’s IP address, which will be referred to as $WORKER_IP
Note: This process can be repeated multiple times to add additional workers.
Using the Cluster
Once the cluster is available, you can make use of talosctl and kubectl to interact with the cluster.
For example, to view current running containers, run talosctl containers for a list of containers in the system namespace, or talosctl containers -k for the k8s.io namespace.
To view the logs of a container, use talosctl logs <container> or talosctl logs -k <container>.
First, configure talosctl to talk to your control plane node by issuing the following, updating paths and IPs as necessary:
Insert the SD card to your board, turn it on and wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
2.1.5.2 - Friendlyelec Nano PI R4S
Installing Talos on a Nano PI R4S SBC using raw disk image.
Insert the SD card to your board, turn it on and wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
2.1.5.3 - Jetson Nano
Installing Talos on Jetson Nano SBC using raw disk image.
We will use the R32.7.2 release for the Jetson Nano.
Most of the instructions is similar to this doc except that we’d be using a upstream version of u-boot with patches from NVIDIA u-boot so that USB boot also works.
Before flashing we need the following:
A USB-A to micro USB cable
A jumper wire to enable recovery mode
A HDMI monitor to view the logs if the USB serial adapter is not available
A USB to Serial adapter with 3.3V TTL (optional)
A 5V DC barrel jack
If you’re planning to use the serial console follow the documentation here
First start by downloading the Jetson Nano L4T release.
Next we will extract the L4T release and replace the u-boot binary with the patched version.
tar xf jetson-210_linux_r32.6.1_aarch64.tbz2
cd Linux_for_Tegra
crane --platform=linux/arm64 export ghcr.io/siderolabs/u-boot:v1.3.0-alpha.0-25-g0ac7773 - | tar xf - --strip-components=1 -C bootloader/t210ref/p3450-0000/ jetson_nano/u-boot.bin
Next we will flash the firmware to the Jetson Nano SPI flash.
In order to do that we need to put the Jetson Nano into Force Recovery Mode (FRC).
We will use the instructions from here
Ensure that the Jetson Nano is powered off.
There is no need for the SD card/USB storage/network cable to be connected
Connect the micro USB cable to the micro USB port on the Jetson Nano, don’t plug the other end to the PC yet
Enable Force Recovery Mode (FRC) by placing a jumper across the FRC pins on the Jetson Nano
For board revision A02, these are pins 3 and 4 of header J40
For board revision B01, these are pins 9 and 10 of header J50
Place another jumper across J48 to enable power from the DC jack and connect the Jetson Nano to the DC jack J25
Now connect the other end of the micro USB cable to the PC and remove the jumper wire from the FRC pins
Now the Jetson Nano is in Force Recovery Mode (FRC) and can be confirmed by running the following command
lsusb | grep -i "nvidia"
Now we can move on the flashing the firmware.
sudo ./flash p3448-0000-max-spi external
This will flash the firmware to the Jetson Nano SPI flash and you’ll see a lot of output.
If you’ve connected the serial console you’ll also see the progress there.
Once the flashing is done you can disconnect the USB cable and power off the Jetson Nano.
| Replace /dev/mmcblk0 with the name of your SD card/USB storage.
Bootstrapping the Node
Insert the SD card/USB storage to your board, turn it on and wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
2.1.5.4 - Libre Computer Board ALL-H3-CC
Installing Talos on Libre Computer Board ALL-H3-CC SBC using raw disk image.
Insert the SD card to your board, turn it on and wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
2.1.5.5 - Pine64
Installing Talos on a Pine64 SBC using raw disk image.
Insert the SD card to your board, turn it on and wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
2.1.5.6 - Pine64 Rock64
Installing Talos on Pine64 Rock64 SBC using raw disk image.
Insert the SD card to your board, turn it on and wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
2.1.5.7 - Radxa ROCK PI 4
Installing Talos on Radxa ROCK PI 4a/4b SBC using raw disk image.
Prerequisites
You will need
talosctl
an SD card or an eMMC or USB drive or an nVME drive
After these steps, Talos will boot from the nVME/USB and enter maintenance mode.
Proceed to bootstrapping the node.
Bootstrapping the Node
Wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
2.1.5.8 - Radxa ROCK PI 4C
Installing Talos on Radxa ROCK PI 4c SBC using raw disk image.
Prerequisites
You will need
talosctl
an SD card or an eMMC or USB drive or an nVME drive
After these steps, Talos will boot from the nVME/USB and enter maintenance mode.
Proceed to bootstrapping the node.
Bootstrapping the Node
Wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
2.1.5.9 - Raspberry Pi 4 Model B
Installing Talos on Rpi4 SBC using raw disk image.
The Raspberry Pi specific image is now deprecated and Talos will continue to use a generic image for the various Raspberry Pi models as supported by u-bootrpi_arm64_defconfig.
Refer to the generic docs available here
Video Walkthrough
To see a live demo of this writeup, see the video below:
At least version v2020.09.03-138a1 of the bootloader (rpi-eeprom) is required.
To update the bootloader we will need an SD card.
Insert the SD card into your computer and use Raspberry Pi Imager
to install the bootloader on it (select Operating System > Misc utility images > Bootloader > SD Card Boot).
Alternatively, you can use the console on Linux or macOS.
The path to your SD card can be found using fdisk on Linux or diskutil on macOS.
In this example, we will assume /dev/mmcblk0.
Remove the SD card from your local machine and insert it into the Raspberry Pi.
Power the Raspberry Pi on, and wait at least 10 seconds.
If successful, the green LED light will blink rapidly (forever), otherwise an error pattern will be displayed.
If an HDMI display is attached to the port closest to the power/USB-C port,
the screen will display green for success or red if a failure occurs.
Power off the Raspberry Pi and remove the SD card from it.
Note: Updating the bootloader only needs to be done once.
Insert the SD card to your board, turn it on and wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Note: if you have an HDMI display attached and it shows only a rainbow splash,
please use the other HDMI port, the one closest to the power/USB-C port.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
Troubleshooting
The following table can be used to troubleshoot booting issues:
Long Flashes
Short Flashes
Status
0
3
Generic failure to boot
0
4
start*.elf not found
0
7
Kernel image not found
0
8
SDRAM failure
0
9
Insufficient SDRAM
0
10
In HALT state
2
1
Partition not FAT
2
2
Failed to read from partition
2
3
Extended partition not FAT
2
4
File signature/hash mismatch - Pi 4
4
4
Unsupported board type
4
5
Fatal firmware error
4
6
Power failure type A
4
7
Power failure type B
2.1.5.10 - Raspberry Pi Series
Installing Talos on Raspberry Pi SBC’s using raw disk image.
Talos disk image for the Raspberry Pi generic should in theory work for the boards supported by u-bootrpi_arm64_defconfig.
This has only been officialy tested on the Raspberry Pi 4 and community tested on one variant of the Compute Module 4 using Super 6C boards.
If you have tested this on other Raspberry Pi boards, please let us know.
Video Walkthrough
To see a live demo of this writeup, see the video below:
Prerequisites
You will need
talosctl
an SD card
Download the latest talosctl.
curl -sL 'https://www.talos.dev/install' | bash
Updating the EEPROM
Use Raspberry Pi Imager to write an EEPROM update image to a spare SD card.
Select Misc utility images under the Operating System tab.
Remove the SD card from your local machine and insert it into the Raspberry Pi.
Power the Raspberry Pi on, and wait at least 10 seconds.
If successful, the green LED light will blink rapidly (forever), otherwise an error pattern will be displayed.
If an HDMI display is attached to the port closest to the power/USB-C port,
the screen will display green for success or red if a failure occurs.
Power off the Raspberry Pi and remove the SD card from it.
Note: Updating the bootloader only needs to be done once.
Insert the SD card to your board, turn it on and wait for the console to show you the instructions for bootstrapping the node.
Following the instructions in the console output to connect to the interactive installer:
talosctl apply-config --insecure --mode=interactive --nodes <node IP or DNS name>
Once the interactive installation is applied, the cluster will form and you can then use kubectl.
Note: if you have an HDMI display attached and it shows only a rainbow splash,
please use the other HDMI port, the one closest to the power/USB-C port.
Retrieve the kubeconfig
Retrieve the admin kubeconfig by running:
talosctl kubeconfig
Troubleshooting
The following table can be used to troubleshoot booting issues:
Long Flashes
Short Flashes
Status
0
3
Generic failure to boot
0
4
start*.elf not found
0
7
Kernel image not found
0
8
SDRAM failure
0
9
Insufficient SDRAM
0
10
In HALT state
2
1
Partition not FAT
2
2
Failed to read from partition
2
3
Extended partition not FAT
2
4
File signature/hash mismatch - Pi 4
4
4
Unsupported board type
4
5
Fatal firmware error
4
6
Power failure type A
4
7
Power failure type B
2.2 - Configuration
Guides on how to configure Talos Linux machines
2.2.1 - Configuration Patches
In this guide, we’ll patch the generated machine configuration.
Talos generates machine configuration for two types of machines: controlplane and worker machines.
Many configuration options can be adjusted using talosctl gen config but not all of them.
Configuration patching allows modifying machine configuration to fit it for the cluster or a specific machine.
Configuration Patch Formats
Talos supports two configuration patch formats:
strategic merge patches
RFC6902 (JSON patches)
Strategic merge patches are the easiest to use, but JSON patches allow more precise configuration adjustments.
Strategic Merge patches
Strategic merge patches look like incomplete machine configuration files:
machine:
network:
hostname: worker1
When applied to the machine configuration, the patch gets merged with the respective section of the machine configuration:
In general, machine configuration contents are merged with the contents of the strategic merge patch, with strategic merge patch
values overriding machine configuration values.
There are some special rules:
If the field value is a list, the patch value is appended to the list, with the following exceptions:
values of the fields cluster.network.podSubnets and cluster.network.serviceSubnets are overwritten on merge
network.interfaces section is merged with the value in the machine config if there is a match on interface: or deviceSelector: keys
network.interfaces.vlans section is merged with the value in the machine config if there is a match on the vlanId: key
RFC6902 (JSON Patches)
JSON patches can be written either in JSON or YAML format.
A proper JSON patch requires an op field that depends on the machine configuration contents: whether the path already exists or not.
For example, the strategic merge patch from the previous section can be written either as:
Several talosctl commands accept config patches as command-line flags.
Config patches might be passed either as an inline value or as a reference to a file with @file.patch syntax:
If multiple config patches are specified, they are applied in the order of appearance.
The format of the patch (JSON patch or strategic merge patch) is detected automatically.
Talos machine configuration can be patched at the moment of generation with talosctl gen config:
Once the server reboots, metrics are now available:
$ curl ${IP}:11234/v1/metrics
# HELP container_blkio_io_service_bytes_recursive_bytes The blkio io service bytes recursive# TYPE container_blkio_io_service_bytes_recursive_bytes gaugecontainer_blkio_io_service_bytes_recursive_bytes{container_id="0677d73196f5f4be1d408aab1c4125cf9e6c458a4bea39e590ac779709ffbe14",device="/dev/dm-0",major="253",minor="0",namespace="k8s.io",op="Async"}0container_blkio_io_service_bytes_recursive_bytes{container_id="0677d73196f5f4be1d408aab1c4125cf9e6c458a4bea39e590ac779709ffbe14",device="/dev/dm-0",major="253",minor="0",namespace="k8s.io",op="Discard"}0...
...
Pause Image
This change is often required for air-gapped environments, as containerd CRI plugin has a reference to the pause image which is used
to create pods, and it can’t be controlled with Kubernetes pod definitions.
It is possible to enable encryption for system disks at the OS level.
Currently, only STATE and EPHEMERAL partitions can be encrypted.
STATE contains the most sensitive node data: secrets and certs.
The EPHEMERAL partition may contain sensitive workload data.
Data is encrypted using LUKS2, which is provided by the Linux kernel modules and cryptsetup utility.
The operating system will run additional setup steps when encryption is enabled.
If the disk encryption is enabled for the STATE partition, the system will:
Save STATE encryption config as JSON in the META partition.
Before mounting the STATE partition, load encryption configs either from the machine config or from the META partition.
Note that the machine config is always preferred over the META one.
Before mounting the STATE partition, format and encrypt it.
This occurs only if the STATE partition is empty and has no filesystem.
If the disk encryption is enabled for the EPHEMERAL partition, the system will:
Get the encryption config from the machine config.
Before mounting the EPHEMERAL partition, encrypt and format it.
This occurs only if the EPHEMERAL partition is empty and has no filesystem.
Note: Talos Linux disk encryption is designed to guard against data being leaked or recovered from a drive that has been removed from a Talos Linux node.
It uses the hardware characteristics of the machine in order to decrypt the data, so drives that have been removed, or recycled from a cloud environment or attached to a different virtual machine, will maintain their protection and encryption.
It is not designed to protect against attacks where physical access to the machine, including the drive, is available.
Configuration
Disk encryption is disabled by default.
To enable disk encryption you should modify the machine configuration with the following options:
Note: What the LUKS2 docs call “keys” are, in reality, a passphrase.
When this passphrase is added, LUKS2 runs argon2 to create an actual key from that passphrase.
LUKS2 supports up to 32 encryption keys and it is possible to specify all of them in the machine configuration.
Talos always tries to sync the keys list defined in the machine config with the actual keys defined for the LUKS2 partition.
So if you update the keys list, keep at least one key that is not changed to be used for key management.
When you define a key you should specify the key kind and the slot:
Take a note that key order does not play any role on which key slot is used.
Every key must always have a slot defined.
Encryption Key Kinds
Talos supports two kinds of keys:
nodeID which is generated using the node UUID and the partition label (note that if the node UUID is not really random it will fail the entropy check).
static which you define right in the configuration.
Note: Use static keys only if your STATE partition is encrypted and only for the EPHEMERAL partition.
For the STATE partition it will be stored in the META partition, which is not encrypted.
Key Rotation
In order to completely rotate keys, it is necessary to do talosctl apply-config a couple of times, since there is a need to always maintain a single working key while changing the other keys around it.
That’s it!
After you run the last command, the partition will be wiped and the node will reboot.
During the next boot the system will encrypt the partition.
State Partition
Calling wipe against the STATE partition will make the node lose the config, so the previous flow is not going to work.
The flow should be to first wipe the STATE partition:
talosctl reset --system-labels-to-wipe STATE -n <node ip> --reboot=true
Node will enter into maintenance mode, then run apply-config with --insecure flag:
After installation is complete the node should encrypt the STATE partition.
2.2.5 - Editing Machine Configuration
How to edit and patch Talos machine configuration, with reboot, immediately, or stage update on reboot.
Talos node state is fully defined by machine configuration.
Initial configuration is delivered to the node at bootstrap time, but configuration can be updated while the node is running.
Note: Be sure that config is persisted so that configuration updates are not overwritten on reboots.
Configuration persistence was enabled by default since Talos 0.5 (persist: true in machine configuration).
There are three talosctl commands which facilitate machine configuration updates:
talosctl apply-config to apply configuration from the file
talosctl edit machineconfig to launch an editor with existing node configuration, make changes and apply configuration back
talosctl patch machineconfig to apply automated machine configuration via JSON patch
Each of these commands can operate in one of four modes:
apply change in automatic mode(default): reboot if the change can’t be applied without a reboot, otherwise apply the change immediately
apply change with a reboot (--mode=reboot): update configuration, reboot Talos node to apply configuration change
apply change immediately (--mode=no-reboot flag): change is applied immediately without a reboot, fails if the change contains any fields that can not be updated without a reboot
apply change on next reboot (--mode=staged): change is staged to be applied after a reboot, but node is not rebooted
apply change in the interactive mode (--mode=interactive; only for talosctl apply-config): launches TUI based interactive installer
Note: applying change on next reboot (--mode=staged) doesn’t modify current node configuration, so next call to
talosctl edit machineconfig --mode=staged will not see changes
Additionally, there is also talosctl get machineconfig, which retrieves the current node configuration API resource and contains the machine configuration in the .spec field.
It can be used to modify the configuration locally before being applied to the node.
The list of config changes allowed to be applied immediately in Talos v1.4.8:
.debug
.cluster
.machine.time
.machine.certCANs
.machine.install (configuration is only applied during install/upgrade)
.machine.network
.machine.nodeLabels
.machine.sysfs
.machine.sysctls
.machine.logging
.machine.controlplane
.machine.kubelet
.machine.pods
.machine.kernel
.machine.registries (CRI containerd plugin will not pick up the registry authentication settings without a reboot)
.machine.features.kubernetesTalosAPIAccess
talosctl apply-config
This command is traditionally used to submit initial machine configuration generated by talosctl gen config to the node.
It can also be used to apply configuration to running nodes.
The initial YAML for this is typically obtained using talosctl get machineconfig -o yaml | yq eval .spec >machs.yaml.
(We must use yq because for historical reasons, get returns the configuration as a full resource, while apply-config only accepts the raw machine config directly.)
Example:
talosctl -n <IP> apply-config -f config.yaml
Command apply-config can also be invoked as apply machineconfig:
Applying machine configuration immediately (without a reboot):
talosctl -n IP apply machineconfig -f config.yaml --mode=no-reboot
Starting the interactive installer:
talosctl -n IP apply machineconfig --mode=interactive
Note: when a Talos node is running in the maintenance mode it’s necessary to provide --insecure (-i) flag to connect to the API and apply the config.
taloctl edit machineconfig
Command talosctl edit loads current machine configuration from the node and launches configured editor to modify the config.
If config hasn’t been changed in the editor (or if updated config is empty), update is not applied.
Note: Talos uses environment variables TALOS_EDITOR, EDITOR to pick up the editor preference.
If environment variables are missing, vi editor is used by default.
Example:
talosctl -n <IP> edit machineconfig
Configuration can be edited for multiple nodes if multiple IP addresses are specified:
talosctl -n <IP1>,<IP2>,... edit machineconfig
Applying machine configuration change immediately (without a reboot):
Command talosctl patch works similar to talosctl edit command - it loads current machine configuration, but instead of launching configured editor it applies a set of JSON patches to the configuration and writes the result back to the node.
Example, updating kubelet version (in auto mode):
$ talosctl -n <IP> patch machineconfig -p '[{"op": "replace", "path": "/machine/kubelet/image", "value": "ghcr.io/siderolabs/kubelet:v1.27.4"}]'patched mc at the node <IP>
Updating kube-apiserver version in immediate mode (without a reboot):
$ talosctl -n <IP> patch machineconfig --mode=no-reboot -p '[{"op": "replace", "path": "/cluster/apiServer/image", "value": "registry.k8s.io/kube-apiserver:v1.27.4"}]'patched mc at the node <IP>
A patch might be applied to multiple nodes when multiple IPs are specified:
If a Talos node fails to boot because of wrong configuration (for example, control plane endpoint is incorrect), configuration can be updated to fix the issue.
2.2.6 - Logging
Dealing with Talos Linux logs.
Viewing logs
Kernel messages can be retrieved with talosctl dmesg command:
Service logs can be retrieved with talosctl logs command:
$ talosctl -n 172.20.1.2 services
NODE SERVICE STATE HEALTH LAST CHANGE LAST EVENT
172.20.1.2 apid Running OK 19m27s ago Health check successful
172.20.1.2 containerd Running OK 19m29s ago Health check successful
172.20.1.2 cri Running OK 19m27s ago Health check successful
172.20.1.2 etcd Running OK 19m22s ago Health check successful
172.20.1.2 kubelet Running OK 19m20s ago Health check successful
172.20.1.2 machined Running ? 19m30s ago Service started as goroutine
172.20.1.2 trustd Running OK 19m27s ago Health check successful
172.20.1.2 udevd Running OK 19m28s ago Health check successful
$ talosctl -n 172.20.1.2 logs machined
172.20.1.2: [talos] task setupLogger (1/1): done, 106.109µs
172.20.1.2: [talos] phase logger (1/7): done, 564.476µs
[...]
Container logs for Kubernetes pods can be retrieved with talosctl logs -k command:
Messages are newline-separated when sent over TCP.
Over UDP messages are sent with one message per packet.
msg, talos-level, talos-service, and talos-time fields are always present; there may be additional fields.
Kernel logs
Kernel log delivery can be enabled with the talos.logging.kernel kernel command line argument, which can be specified
in the .machine.installer.extraKernelArgs:
Kernel log destination is specified in the same way as service log endpoint.
The only supported format is json_lines.
Sample message:
{
"clock":6252819, // time relative to the kernel boot time
"facility":"user",
"msg":"[talos] task startAllServices (1/1): waiting for 6 services\n",
"priority":"warning",
"seq":711,
"talos-level":"warn", // Talos-translated `priority` into common logging level
"talos-time":"2021-11-26T16:53:21.3258698Z"// Talos-translated `clock` using current time
}
extraKernelArgs in the machine configuration are only applied on Talos upgrades, not just by applying the config.
(Upgrading to the same version is fine).
Filebeat example
To forward logs to other Log collection services, one way to do this is sending
them to a Filebeat running in the
cluster itself (in the host network), which takes care of forwarding it to
other endpoints (and the necessary transformations).
If Elastic Cloud on Kubernetes
is being used, the following Beat (custom resource) configuration might be
helpful:
The input configuration ensures that messages and timestamps are extracted properly.
Refer to the Filebeat documentation on how to forward logs to other outputs.
Also note the hostNetwork: true in the daemonSet configuration.
This ensures filebeat uses the host network, and listens on 127.0.0.1:12345
(UDP) on every machine, which can then be specified as a logging endpoint in
the machine configuration.
Fluent-bit example
First, we’ll create a value file for the fluentd-bit Helm chart.
# fluentd-bit.yamlpodAnnotations:
fluentbit.io/exclude: 'true'extraPorts:
- port: 12345containerPort: 12345protocol: TCP
name: talos
config:
service: | [SERVICE]
Flush 5
Daemon Off
Log_Level warn
Parsers_File custom_parsers.confinputs: | [INPUT]
Name tcp
Listen 0.0.0.0
Port 12345
Format json
Tag talos.*
[INPUT]
Name tail
Alias kubernetes
Path /var/log/containers/*.log
Parser containerd
Tag kubernetes.*
[INPUT]
Name tail
Alias audit
Path /var/log/audit/kube/*.log
Parser audit
Tag audit.*filters: | [FILTER]
Name kubernetes
Alias kubernetes
Match kubernetes.*
Kube_Tag_Prefix kubernetes.var.log.containers.
Use_Kubelet Off
Merge_Log On
Merge_Log_Trim On
Keep_Log Off
K8S-Logging.Parser Off
K8S-Logging.Exclude On
Annotations Off
Labels On
[FILTER]
Name modify
Match kubernetes.*
Add source kubernetes
Remove logtagcustomParsers: | [PARSER]
Name audit
Format json
Time_Key requestReceivedTimestamp
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
[PARSER]
Name containerd
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<log>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%zoutputs: | [OUTPUT]
Name stdout
Alias stdout
Match *
Format json_lines# If you wish to ship directly to Loki from Fluentbit,# Uncomment the following output, updating the Host with your Loki DNS/IP info as necessary.# [OUTPUT]# Name loki# Match *# Host loki.loki.svc# Port 3100# Labels job=fluentbit# Auto_Kubernetes_Labels ondaemonSetVolumes:
- name: varlog
hostPath:
path: /var/log
daemonSetVolumeMounts:
- name: varlog
mountPath: /var/log
tolerations:
- operator: Exists
effect: NoSchedule
Next, we will add the helm repo for FluentBit, and deploy it to the cluster.
$ kubectl -n kube-system get svc -l app.kubernetes.io/name=fluent-bit
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
fluent-bit ClusterIP 10.200.0.138 <none> 2020/TCP,5170/TCP 108m
Finally, we will change talos log destination with the command talosctl edit mc.
This example configuration was well tested with Cilium CNI, and it should work with iptables/ipvs based CNI plugins too.
Vector example
Vector is a lightweight observability pipeline ideal for a Kubernetes environment.
It can ingest (source) logs from multiple sources, perform remapping on the logs (transform), and forward the resulting pipeline to multiple destinations (sinks).
As it is an end to end platform, it can be run as a single-deployment ‘aggregator’ as well as a replicaSet of ‘Agents’ that run on each node.
As Talos can be set as above to send logs to a destination, we can run Vector as an Aggregator, and forward both kernel and service to a UDP socket in-cluster.
Below is an excerpt of a source/sink setup for Talos, with a ‘sink’ destination of an in-cluster Grafana Loki log aggregation service.
As Loki can create labels from the log input, we have set up the Loki sink to create labels based on the host IP, service and facility of the inbound logs.
Note that a method of exposing the Vector service will be required which may vary depending on your setup - a LoadBalancer is a good option.
If you have a valid (not expired) talosconfig with os:admin role,
a new client configuration file can be generated with talosctl config new against
any controlplane node:
talosctl -n CP1 config new talosconfig-reader --roles os:reader --crt-ttl 24h
A specific role and certificate lifetime can be specified.
Note: <cluster-name> and <cluster-endpoint> arguments don’t matter, as they are not used for talosconfig.
From Control Plane Machine Configuration
In order to create a new key pair for client configuration, you will need the root Talos API CA.
The base64 encoded CA can be found in the control plane node’s configuration file.
Save the CA public key, and CA private key as ca.crt, and ca.key respectively:
By default admin talosconfig certificate is valid for 365 days, while cluster CAs are valid for 10 years.
In order to prevent admin talosconfig from expiring, renew the client config before expiration using talosctl config new command described above.
If the talosconfig is expired or lost, you can still generate a new one using either the secrets.yaml
secrets bundle or the control plane node’s configuration file using methods described above.
2.2.8 - NVIDIA Fabric Manager
In this guide we’ll follow the procedure to enable NVIDIA Fabric Manager.
The published versions of the NVIDIA fabricmanager system extensions is available here
The nvidia-fabricmanager extension version has to match with the NVIDIA driver version in use.
Upgrading Talos and enabling the NVIDIA fabricmanager system extension
In addition to the patch defined in the NVIDIA drivers guide, we need to add the nvidia-fabricmanager system extension to the patch yaml gpu-worker-patch.yaml:
In this guide we’ll follow the procedure to support NVIDIA GPU using OSS drivers on Talos.
Enabling NVIDIA GPU support on Talos is bound by NVIDIA EULA.
The Talos published NVIDIA OSS drivers are bound to a specific Talos release.
The extensions versions also needs to be updated when upgrading Talos.
The published versions of the NVIDIA system extensions can be found here:
Update the driver version and Talos release in the above patch yaml from the published versions if there is a newer one available.
Make sure the driver version matches for both the nvidia-open-gpu-kernel-modules and nvidia-container-toolkit extensions.
The nvidia-open-gpu-kernel-modules extension is versioned as <nvidia-driver-version>-<talos-release-version> and the nvidia-container-toolkit extension is versioned as <nvidia-driver-version>-<nvidia-container-toolkit-version>.
Now apply the patch to all Talos nodes in the cluster having NVIDIA GPU’s installed:
talosctl patch mc --patch @gpu-worker-patch.yaml
Now we can proceed to upgrading Talos to the same version to enable the system extension:
Once the node reboots, the NVIDIA modules should be loaded and the system extension should be installed.
This can be confirmed by running:
talosctl read /proc/modules
which should produce an output similar to below:
nvidia_uvm 1146880 - - Live 0xffffffffc2733000 (PO)
nvidia_drm 69632 - - Live 0xffffffffc2721000 (PO)
nvidia_modeset 1142784 - - Live 0xffffffffc25ea000 (PO)
nvidia 39047168 - - Live 0xffffffffc00ac000 (PO)
talosctl get extensions
which should produce an output similar to below:
NODE NAMESPACE TYPE ID VERSION NAME VERSION
172.31.41.27 runtime ExtensionStatus 000.ghcr.io-siderolabs-nvidia-container-toolkit-515.65.01-v1.10.0 1 nvidia-container-toolkit 515.65.01-v1.10.0
172.31.41.27 runtime ExtensionStatus 000.ghcr.io-siderolabs-nvidia-open-gpu-kernel-modules-515.65.01-v1.2.0 1 nvidia-open-gpu-kernel-modules 515.65.01-v1.2.0
talosctl read /proc/driver/nvidia/version
which should produce an output similar to below:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 515.65.01 Wed Mar 16 11:24:05 UTC 2022
GCC version: gcc version 12.2.0 (GCC)
Deploying NVIDIA device plugin
First we need to create the RuntimeClass
Apply the following manifest to create a runtime class that uses the extension:
for v1.4.8 and later versions building a custom Talos installer image is not required anymore and the new, prefered way to enable NVIDIA support is via an extension.
Prerequisites
This guide assumes the user has access to a container registry with push permissions, docker installed on the build machine and the Talos host has pull access to the container registry.
Set the local registry, username and version environment variables:
Verifying the NVIDIA modules and the system extension
Once the node reboots, the NVIDIA modules should be loaded and the system extension should be installed.
This can be confirmed by running:
talosctl read /proc/modules
which should produce an output similar to below:
nvidia_uvm 1146880 - - Live 0xffffffffc2733000 (PO)
nvidia_drm 69632 - - Live 0xffffffffc2721000 (PO)
nvidia_modeset 1142784 - - Live 0xffffffffc25ea000 (PO)
nvidia 39047168 - - Live 0xffffffffc00ac000 (PO)
talosctl get extensions
which should produce an output similar to below:
NODE NAMESPACE TYPE ID VERSION NAME VERSION
172.31.41.27 runtime ExtensionStatus 000.ghcr.io-frezbo-nvidia-container-toolkit-510.60.02-v1.9.0 1 nvidia-container-toolkit 510.60.02-v1.9.0
talosctl read /proc/driver/nvidia/version
which should produce an output similar to below:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 510.60.02 Wed Mar 16 11:24:05 UTC 2022
GCC version: gcc version 11.2.0 (GCC)
Deploying NVIDIA device plugin
First we need to create the RuntimeClass
Apply the following manifest to create a runtime class that uses the extension:
Now run the following command to build and push custom Talos kernel image and the NVIDIA image with the NVIDIA kernel modules signed by the kernel built along with it.
make kernel nonfree-kmod-nvidia PLATFORM=linux/amd64 PUSH=true
Replace the platform with linux/arm64 if building for ARM64
Now we need to create a custom Talos installer image.
Start by creating a Dockerfile with the following content:
FROM scratch as customizationCOPY --from=ghcr.io/talos-user/nonfree-kmod-nvidia:v1.4.8-nvidia /lib/modules /lib/modules
FROM ghcr.io/siderolabs/installer:v1.4.8COPY --from=ghcr.io/talos-user/kernel:v1.4.8-nvidia /boot/vmlinuz /usr/install/${TARGETARCH}/vmlinuz
How to set up local transparent container images caches.
In this guide we will create a set of local caching Docker registry proxies to minimize local cluster startup time.
When running Talos locally, pulling images from container registries might take a significant amount of time.
We spin up local caching pass-through registries to cache images and configure a local Talos cluster to use those proxies.
A similar approach might be used to run Talos in production in air-gapped environments.
It can be also used to verify that all the images are available in local registries.
Video Walkthrough
To see a live demo of this writeup, see the video below:
Requirements
The follow are requirements for creating the set of caching proxies:
Docker 18.03 or greater
Local cluster requirements for either docker or QEMU.
Launch the Caching Docker Registry Proxies
Talos pulls from docker.io, registry.k8s.io, gcr.io, and ghcr.io by default.
If your configuration is different, you might need to modify the commands below:
Note: Proxies are started as docker containers, and they’re automatically configured to start with Docker daemon.
As a registry container can only handle a single upstream Docker registry, we launch a container per upstream, each on its own
host port (5000, 5001, 5002, 5003 and 5004).
Using Caching Registries with QEMU Local Cluster
With a QEMU local cluster, a bridge interface is created on the host.
As registry containers expose their ports on the host, we can use bridge IP to direct proxy requests.
The Talos local cluster should now start pulling via caching registries.
This can be verified via registry logs, e.g. docker logs -f registry-docker.io.
The first time cluster boots, images are pulled and cached, so next cluster boot should be much faster.
Note: 10.5.0.1 is a bridge IP with default network (10.5.0.0/24), if using custom --cidr, value should be adjusted accordingly.
Using Caching Registries with docker Local Cluster
With a docker local cluster we can use docker bridge IP, default value for that IP is 172.17.0.1.
On Linux, the docker bridge address can be inspected with ip addr show docker0.
Note: Removing docker registry containers also removes the image cache.
So if you plan to use caching registries, keep the containers running.
Using Harbor as a Caching Registry
Harbor is an open source container registry that can be used as a caching proxy.
Harbor supports configuring multiple upstream registries, so it can be used to cache multiple registries at once behind a single endpoint.
As Harbor puts a registry name in the pull image path, we need to set overridePath: true to prevent Talos and containerd from appending /v2 to the path.
Talos v0.11 introduced initial support for role-based access control (RBAC).
This guide will explain what that is and how to enable it without losing access to the cluster.
RBAC in Talos
Talos uses certificates to authorize users.
The certificate subject’s organization field is used to encode user roles.
There is a set of predefined roles that allow access to different API methods:
os:admin grants access to all methods;
os:operator grants everything os:reader role does, plus additional methods: rebooting, shutting down, etcd backup, etcd alarm management, and so on;
os:reader grants access to “safe” methods (for example, that includes the ability to list files, but does not include the ability to read files content);
Roles in the current talosconfig can be checked with the following command:
$ talosctl config info
[...]Roles: os:admin
[...]
RBAC is enabled by default in new clusters created with talosctl v0.11+ and disabled otherwise.
Enabling RBAC
First, both the Talos cluster and talosctl tool should be upgraded.
Then the talosctl config new command should be used to generate a new client configuration with the os:admin role.
Additional configurations and certificates for different roles can be generated by passing --roles flag:
talosctl config new --roles=os:reader reader
That command will create a new client configuration file reader with a new certificate with os:reader role.
After that, RBAC should be enabled in the machine configuration:
machine:
features:
rbac: true
2.2.13 - System Extensions
Customizing the Talos Linux immutable root file system.
System extensions allow extending the Talos root filesystem, which enables a variety of features, such as including custom
container runtimes, loading additional firmware, etc.
System extensions are only activated during the installation or upgrade of Talos Linux.
With system extensions installed, the Talos root filesystem is still immutable and read-only.
Configuration
System extensions are configured in the .machine.install section:
During the initial install (e.g. when PXE booting or booting from an ISO), Talos will pull down container images for system extensions,
validate them, and include them into the Talos initramfs image.
System extensions will be activated on boot and overlaid on top of the Talos root filesystem.
In order to update the system extensions for a running instance, update .machine.install.extensions and upgrade Talos.
(Note: upgrading to the same version of Talos is fine).
Building a Talos Image with System Extensions
System extensions can be installed into the Talos disk image (e.g. AWS AMI or VMWare OVF) by running the following command to generate the image
from the Talos source tree:
make image-metal IMAGER_SYSTEM_EXTENSIONS="ghcr.io/siderolabs/amd-ucode:20220411 ghcr.io/siderolabs/gvisor:20220405.0-v1.0.0-10-g82b41ad"
Authoring System Extensions
A Talos system extension is a container image with the specific folder structure.
System extensions can be built and managed using any tool that produces container images, e.g. docker build.
Use talosctl get extensions to get a list of system extensions:
$ talosctl get extensions
NODE NAMESPACE TYPE ID VERSION NAME VERSION
172.20.0.2 runtime ExtensionStatus 000.ghcr.io-talos-systems-gvisor-54b831d 1 gvisor 20220117.0-v1.0.0
172.20.0.2 runtime ExtensionStatus 001.ghcr.io-talos-systems-intel-ucode-54b831d 1 intel-ucode microcode-20210608-v1.0.0
Use YAML or JSON format to see additional details about the extension:
2.3.1 - How to enable workers on your control plane nodes
How to enable workers on your control plane nodes.
By default, Talos Linux taints control plane nodes so that workloads are not schedulable on them.
In order to allow workloads to run on the control plane nodes (useful for single node clusters, or non-production clusters), follow the procedure below.
Modify the MachineConfig for the controlplane nodes to add allowSchedulingOnControlPlanes: true:
cluster:
allowSchedulingOnControlPlanes: true
This may be done via editing the controlplane.yaml file before it is applied to the controlplane nodes, by talosctl edit machineconfig, or by patching the machine config.
Note: if you edit or patch the machine config on a running control plane node to set allowSchedulingOnControlPlanes: true, it will be applied immediately, but will not have any effect until the next reboot.
You may reboot the nodes via talosctl reboot.
You may also immediately make the control plane nodes schedulable by running the below:
Note that unless allowSchedulingOnControlPlanes: true is set in the machine config, the nodes will be tainted again on next reboot.
2.3.2 - How to scale down a Talos cluster
How to remove nodes from a Talos Linux cluster.
To remove nodes from a Talos Linux cluster:
talosctl -n <IP.of.node.to.remove> reset
kubectl delete node <nodename>
The command talosctl reset will cordon and drain the node, leaving etcd if required, and then erase its disks and power down the system.
This command will also remove the node from registration with the discovery service, so it will no longer show up in talosctl get members.
It is still necessary to remove the node from Kubernetes, as noted above.
2.3.3 - How to scale up a Talos cluster
How to add more nodes to a Talos Linux cluster.
To add more nodes to a Talos Linux cluster, follow the same procedure as when initially creating the cluster:
boot the new machines to install Talos Linux
apply the worker.yaml or controlplane.yaml configuration files to the new machines
You need the controlplane.yaml and worker.yaml that were created when you initially deployed your cluster.
These contain the certificates that enable new machines to join.
Once you have the IP address, you can then apply the correct configuration for each machine you are adding, either worker or controlplane.
The insecure flag is necessary because the PKI infrastructure has not yet been made available to the node.
You do not need to bootstrap the new node.
Regardless of whether you are adding a control plane or worker node, it will now join the cluster in its role.
2.4 - Network
Set up networking layers for Talos Linux
2.4.1 - Corporate Proxies
How to configure Talos Linux to use proxies in a corporate environment
Appending the Certificate Authority of MITM Proxies
Put into each machine the PEM encoded certificate:
In this example, the bond0 interface will be created and bonded using two devices with the specified hardware addresses.
Use Case
machine.network.interfaces.interface name is generated by the Linux kernel and can be changed after a reboot.
Device names can change when the system has several interfaces of the same kind, e.g: eth0, eth1.
In that case pinning it to hardwareAddress will make Talos reliably configure the device even when interface name changes.
2.4.3 - Virtual (shared) IP
Using Talos Linux to set up a floating virtual IP address for cluster access.
One of the pain points when building a high-availability controlplane
is giving clients a single IP or URL at which they can reach any of the controlplane nodes.
The most common approaches - reverse proxy, load
balancer, BGP, and DNS - all require external resources, and add complexity in setting up Kubernetes.
To simplify cluster creation, Talos Linux supports a “Virtual” IP (VIP) address to access the Kubernetes API server, providing high availability with no other resources required.
What happens is that the controlplane machines vie for control of the shared IP address using etcd elections.
There can be only one owner of the IP address at any given time.
If that owner disappears or becomes non-responsive, another owner will be chosen,
and it will take up the IP address.
Requirements
The controlplane nodes must share a layer 2 network, and the virtual IP must be assigned from that shared network subnet.
In practical terms, this means that they are all connected via a switch, with no router in between them.
Note that the virtual IP election depends on etcd being up, as Talos uses etcd for elections and leadership (control) of the IP address.
The virtual IP is not restricted by ports - you can access any port that the control plane nodes are listening on, on that IP address.
Thus it is possible to access the Talos API over the VIP, but it is not recommended, as you cannot access the VIP when etcd is down - and then you could not access the Talos API to recover etcd.
Video Walkthrough
To see a live demo of this writeup, see the video below:
Choose your Shared IP
The Virtual IP should be a reserved, unused IP address in the same subnet as
your controlplane nodes.
It should not be assigned or assignable by your DHCP server.
For our example, we will assume that the controlplane nodes have the following
IP addresses:
192.168.0.10
192.168.0.11
192.168.0.12
We then choose our shared IP to be:
192.168.0.15
Configure your Talos Machines
The shared IP setting is only valid for controlplane nodes.
For the example above, each of the controlplane nodes should have the following
Machine Config snippet:
For your own environment, the interface and the DHCP setting may differ, or you may
use static addressing (cidr) instead of DHCP.
Caveats
Since VIP functionality relies on etcd for elections, the shared IP will not come
alive until after you have bootstrapped Kubernetes.
This does mean that you cannot use the
shared IP when issuing the talosctl bootstrap command (although, as noted above, it is not recommended to access the Talos API via the VIP).
Instead, the bootstrap command will need to target one of the controlplane nodes
directly.
2.4.4 - Wireguard Network
A guide on how to set up Wireguard network using Kernel module.
Configuring Wireguard Network
Quick Start
The quickest way to try out Wireguard is to use talosctl cluster create command:
It will automatically generate Wireguard network configuration for each node with the following network topology:
Where all controlplane nodes will be used as Wireguard servers which listen on port 51111.
All controlplanes and workers will connect to all controlplanes.
It also sets PersistentKeepalive to 5 seconds to establish controlplanes to workers connection.
After the cluster is deployed it should be possible to verify Wireguard network connectivity.
It is possible to deploy a container with hostNetwork enabled, then do kubectl exec <container> /bin/bash and either do:
ping 10.1.0.2
Or install wireguard-tools package and run:
wg show
Wireguard show should output something like this:
interface: wg0
public key: OMhgEvNIaEN7zeCLijRh4c+0Hwh3erjknzdyvVlrkGM= private key: (hidden) listening port: 47946peer: 1EsxUygZo8/URWs18tqB5FW2cLVlaTA+lUisKIf8nh4= endpoint: 10.5.0.2:51111
allowed ips: 10.1.0.0/24
latest handshake: 1 minute, 55 seconds ago
transfer: 3.17 KiB received, 3.55 KiB sent
persistent keepalive: every 5 seconds
It is also possible to use generated configuration as a reference by pulling generated config files using:
All Wireguard configuration can be done by changing Talos machine config files.
As an example we will use this official Wireguard quick start tutorial.
Key Generation
This part is exactly the same:
wg genkey | tee privatekey | wg pubkey > publickey
Setting up Device
Inline comments show relations between configs and wg quickstart tutorial commands:
...
network:
interfaces:
...
# ip link add dev wg0 type wireguard - interface: wg0
mtu: 1500# ip address add dev wg0 192.168.2.1/24addresses:
- 192.168.2.1/24
# wg set wg0 listen-port 51820 private-key /path/to/private-key peer ABCDEF... allowed-ips 192.168.88.0/24 endpoint 209.202.254.14:8172wireguard:
privateKey: <privatekey file contents>
listenPort: 51820peers:
allowedIPs:
- 192.168.88.0/24
endpoint: 209.202.254.14.8172publicKey: ABCDEF...
...
When networkd gets this configuration it will create the device, configure it and will bring it up (equivalent to ip link set up dev wg0).
Talos Linux includes node-discovery capabilities that depend on a discovery registry.
This allows you to see the members of your cluster, and the associated IP addresses of the nodes.
talosctl get members
NODE NAMESPACE TYPE ID VERSION HOSTNAME MACHINE TYPE OS ADDRESSES
10.5.0.2 cluster Member talos-default-controlplane-1 1 talos-default-controlplane-1 controlplane Talos (v1.2.3)["10.5.0.2"]10.5.0.2 cluster Member talos-default-worker-1 1 talos-default-worker-1 worker Talos (v1.2.3)["10.5.0.3"]
There are currently two supported discovery services: a Kubernetes registry (which stores data in the cluster’s etcd service) and an external registry service.
Sidero Labs runs a public external registry service, which is enabled by default.
The Kubernetes registry service is disabled by default.
The advantage of the external registry service is that it is not dependent on etcd, and thus can inform you of cluster membership even when Kubernetes is down.
Video Walkthrough
To see a live demo of Cluster Discovery, see the video below:
Registries
Peers are aggregated from enabled registries.
By default, Talos will use the service registry, while the kubernetes registry is disabled.
To disable a registry, set disabled to true (this option is the same for all registries):
For example, to disable the service registry:
The Service registry by default uses a public external Discovery Service to exchange encrypted information about cluster members.
Discovery Service
Sidero Labs maintains a public discovery service at https://discovery.talos.dev/ whereby cluster members use a shared key that is globally unique to coordinate basic connection information (i.e. the set of possible “endpoints”, or IP:port pairs).
We call this data “affiliate data.”
Note: If KubeSpan is enabled the data has the addition of the WireGuard public key.
Data sent to the discovery service is encrypted with AES-GCM encryption and endpoint data is separately encrypted with AES in ECB mode so that endpoints coming from different sources can be deduplicated server-side.
Each node submits its own data, plus the endpoints it sees from other peers, to the discovery service.
The discovery service aggregates the data, deduplicates the endpoints, and sends updates to each connected peer.
Each peer receives information back from the discovery service, decrypts it and uses it to drive KubeSpan and cluster discovery.
Data is stored in memory only.
The cluster ID is used as a key to select the affiliates (so that different clusters see different affiliates).
To summarize, the discovery service knows the client version, cluster ID, the number of affiliates, some encrypted data for each affiliate, and a list of encrypted endpoints.
The discovery service doesn’t see actual node information – it only stores and updates encrypted blobs.
Discovery data is encrypted/decrypted by the clients – the cluster members.
The discovery service does not have the encryption key.
The discovery service may, with a commercial license, be operated by your organization and can be downloaded here.
In order for nodes to communicate to the discovery service, they must be able to connect to it on TCP port 443.
Resource Definitions
Talos provides seven resources that can be used to introspect the new discovery and KubeSpan features.
Discovery
Identities
The node’s unique identity (base62 encoded random 32 bytes) can be obtained with:
Note: Using base62 allows the ID to be URL encoded without having to use the ambiguous URL-encoding version of base64.
$ talosctl get identities -o yaml
...
spec:
nodeId: Utoh3O0ZneV0kT2IUBrh7TgdouRcUW2yzaaMl4VXnCd
Node identity is used as the unique Affiliate identifier.
Node identity resource is preserved in the STATE partition in node-identity.yaml file.
Node identity is preserved across reboots and upgrades, but it is regenerated if the node is reset (wiped).
Affiliates
An affiliate is a proposed member attributed to the fact that the node has the same cluster ID and secret.
$ talosctl get affiliates
ID VERSION HOSTNAME MACHINE TYPE ADDRESSES
2VfX3nu67ZtZPl57IdJrU87BMjVWkSBJiL9ulP9TCnF 2 talos-default-controlplane-2 controlplane ["172.20.0.3","fd83:b1f7:fcb5:2802:986b:7eff:fec5:889d"]6EVq8RHIne03LeZiJ60WsJcoQOtttw1ejvTS6SOBzhUA 2 talos-default-worker-1 worker ["172.20.0.5","fd83:b1f7:fcb5:2802:cc80:3dff:fece:d89d"]NVtfu1bT1QjhNq5xJFUZl8f8I8LOCnnpGrZfPpdN9WlB 2 talos-default-worker-2 worker ["172.20.0.6","fd83:b1f7:fcb5:2802:2805:fbff:fe80:5ed2"]Utoh3O0ZneV0kT2IUBrh7TgdouRcUW2yzaaMl4VXnCd 4 talos-default-controlplane-1 controlplane ["172.20.0.2","fd83:b1f7:fcb5:2802:8c13:71ff:feaf:7c94"]b3DebkPaCRLTLLWaeRF1ejGaR0lK3m79jRJcPn0mfA6C 2 talos-default-controlplane-3 controlplane ["172.20.0.4","fd83:b1f7:fcb5:2802:248f:1fff:fe5c:c3f"]
One of the Affiliates with the ID matching node identity is populated from the node data, other Affiliates are pulled from the registries.
Enabled discovery registries run in parallel and discovered data is merged to build the list presented above.
Details about data coming from each registry can be queried from the cluster-raw namespace:
Each Affiliate ID is prefixed with k8s/ for data coming from the Kubernetes registry and with service/ for data coming from the discovery service.
Members
A member is an affiliate that has been approved to join the cluster.
The members of the cluster can be obtained with:
$ talosctl get members
ID VERSION HOSTNAME MACHINE TYPE OS ADDRESSES
talos-default-controlplane-1 2 talos-default-controlplane-1 controlplane Talos (v1.4.8)["172.20.0.2","fd83:b1f7:fcb5:2802:8c13:71ff:feaf:7c94"]talos-default-controlplane-2 1 talos-default-controlplane-2 controlplane Talos (v1.4.8)["172.20.0.3","fd83:b1f7:fcb5:2802:986b:7eff:fec5:889d"]talos-default-controlplane-3 1 talos-default-controlplane-3 controlplane Talos (v1.4.8)["172.20.0.4","fd83:b1f7:fcb5:2802:248f:1fff:fe5c:c3f"]talos-default-worker-1 1 talos-default-worker-1 worker Talos (v1.4.8)["172.20.0.5","fd83:b1f7:fcb5:2802:cc80:3dff:fece:d89d"]talos-default-worker-2 1 talos-default-worker-2 worker Talos (v1.4.8)["172.20.0.6","fd83:b1f7:fcb5:2802:2805:fbff:fe80:5ed2"]
2.6 - Interactive Dashboard
A tool to inspect the running Talos machine state on the physical video console.
Interactive dashboard is enabled for all Talos platforms except for SBC images.
The dashboard can be disabled with kernel parameter talos.dashboard.disabled=1.
The dashboard runs only on the physical video console (not serial console) on the 2nd virtual TTY.
The first virtual TTY shows kernel logs same as in Talos <1.4.0.
The virtual TTYs can be switched with <Alt+F1> and <Alt+F2> keys.
Keys <F1> - <Fn> can be used to switch between different screens of the dashboard.
The dashboard is using either UEFI framebuffer or VGA/VESA framebuffer (for legacy BIOS boot).
For legacy BIOS boot screen resolution can be controlled with the vga= kernel parameter.
Summary Screen (F1)
Interactive Dashboard Summary Screen
The header shows brief information about the node:
hostname
Talos version
uptime
CPU and memory hardware information
CPU and memory load, number of processes
Table view presents summary information about the machine:
UUID (from SMBIOS data)
Cluster name (when the machine config is available)
the leftmost section provides a way to enter network configuration: hostname, DNS and NTP servers, configure the network interface either via DHCP or static IP address, etc.
the middle section shows the current network configuration.
the rightmost section shows the network configuration which will be applied after pressing “Save” button.
Once the platform network configuration is saved, it is immediately applied to the machine.
2.7 - Resetting a Machine
Steps on how to reset a Talos Linux machine to a clean state.
From time to time, it may be beneficial to reset a Talos machine to its “original” state.
Bear in mind that this is a destructive action for the given machine.
Doing this means removing the machine from Kubernetes, Etcd (if applicable), and clears any data on the machine that would normally persist a reboot.
CLI
WARNING: Running a talosctl reset on cloud VM’s might result in the VM being unable to boot as this wipes the entire disk.
It might be more useful to just wipe the STATE and EPHEMERAL partitions on a cloud VM if not booting via iPXE.
talosctl reset --system-labels-to-wipe STATE --system-labels-to-wipe EPHEMERAL
The API command for doing this is talosctl reset.
There are a couple of flags as part of this command:
Flags:
--graceful if true, attempt to cordon/drain node and leave etcd (if applicable)(default true) --reboot if true, reboot the node after resetting instead of shutting down
--system-labels-to-wipe strings if set, just wipe selected system disk partitions by label but keep other partitions intact keep other partitions intact
The graceful flag is especially important when considering HA vs. non-HA Talos clusters.
If the machine is part of an HA cluster, a normal, graceful reset should work just fine right out of the box as long as the cluster is in a good state.
However, if this is a single node cluster being used for testing purposes, a graceful reset is not an option since Etcd cannot be “left” if there is only a single member.
In this case, reset should be used with --graceful=false to skip performing checks that would normally block the reset.
Kernel Parameter
Another way to reset a machine is to specify talos.experimental.wipe=system kernel parameter.
If the machine got stuck in the boot loop and you access to the console you can use GRUB to specify this kernel argument.
Then when Talos boots for the next time it will reset system disk and reboot.
Next steps can be to install Talos either using PXE boot or by mounting an ISO.
2.8 - Upgrading Talos Linux
Guide to upgrading a Talos Linux machine.
OS upgrades are effected by an API call, which can be sent via the talosctl CLI utility.
The upgrade API call passes a node the installer image to use to perform the upgrade.
Each Talos version has a corresponding installer image, listed on the release page for the version, for example v1.4.8.
Upgrades use an A-B image scheme in order to facilitate rollbacks.
This scheme retains the previous Talos kernel and OS image following each upgrade.
If an upgrade fails to boot, Talos will roll back to the previous version.
Likewise, Talos may be manually rolled back via API (or talosctl rollback), which will update the boot reference and reboot.
Unless explicitly told to preserve data, an upgrade will cause the node to wipe the EPHEMERAL partition, remove itself from the etcd cluster (if it is a controlplane node), and make itself as pristine as is possible.
(This is the desired behavior except in specialised use cases such as single-node clusters.)
Note An upgrade of the Talos Linux OS will not (since v1.0) apply an upgrade to the Kubernetes version by default.
Kubernetes upgrades should be managed separately per upgrading kubernetes.
Supported Upgrade Paths
Because Talos Linux is image based, an upgrade is almost the same as installing Talos, with the difference that the system has already been initialized with a configuration.
The supported configuration may change between versions.
The upgrade process should handle such changes transparently, but this migration is only tested between adjacent minor releases.
Thus the recommended upgrade path is to always upgrade to the latest patch release of all intermediate minor releases.
For example, if upgrading from Talos 1.0 to Talos 1.2.4, the recommended upgrade path would be:
upgrade from 1.0 to latest patch of 1.0 - to v1.0.6
upgrade from v1.0.6 to latest patch of 1.1 - to v1.1.2
upgrade from v1.1.2 to v1.2.4
Before Upgrade to v1.4.8
There are no specific actions to be taken before an upgrade.
Video Walkthrough
To see a live demo of an upgrade of Talos Linux, see the video below:
After Upgrade to v1.4.8
There are no specific actions to be taken after an upgrade.
talosctl upgrade
To upgrade a Talos node, specify the node’s IP address and the
installer container image for the version of Talos to upgrade to.
For instance, if your Talos node has the IP address 10.20.30.40 and you want
to install the current version, you would enter a command such
as:
There is an option to this command: --preserve, which will explicitly tell Talos to keep ephemeral data intact.
In most cases, it is correct to let Talos perform its default action of erasing the ephemeral data.
However, for a single-node control-plane, make sure that --preserve=true.
Rarely, an upgrade command will fail due to a process holding a file open on disk.
In these cases, you can use the --stage flag.
This puts the upgrade artifacts on disk, and adds some metadata to a disk partition that gets checked very early in the boot process, then reboots the node.
On the reboot, Talos sees that it needs to apply an upgrade, and will do so immediately.
Because this occurs in a just rebooted system, there will be no conflict with any files being held open.
After the upgrade is applied, the node will reboot again, in order to boot into the new version.
Note that because Talos Linux reboots via the kexec syscall, the extra reboot adds very little time.
Machine Configuration Changes
.machine.network.interfaces.bond now supports network device selectors for picking up the devices to bond.
Upgrade Sequence
When a Talos node receives the upgrade command, it cordons
itself in Kubernetes, to avoid receiving any new workload.
It then starts to drain its existing workload.
NOTE: If any of your workloads are sensitive to being shut down ungracefully, be sure to use the lifecycle.preStop Pod spec.
Once all of the workload Pods are drained, Talos will start shutting down its
internal processes.
If it is a control node, this will include etcd.
If preserve is not enabled, Talos will leave etcd membership.
(Talos ensures the etcd cluster is healthy and will remain healthy after our node leaves the etcd cluster, before allowing a control plane node to be upgraded.)
Once all the processes are stopped and the services are shut down, the filesystems will be unmounted.
This allows Talos to produce a very clean upgrade, as close as possible to a pristine system.
We verify the disk and then perform the actual image upgrade.
We set the bootloader to boot once with the new kernel and OS image, then we reboot.
After the node comes back up and Talos verifies itself, it will make
the bootloader change permanent, rejoin the cluster, and finally uncordon itself to receive new workloads.
FAQs
Q. What happens if an upgrade fails?
A. Talos Linux attempts to safely handle upgrade failures.
The most common failure is an invalid installer image reference.
In this case, Talos will fail to download the upgraded image and will abort the upgrade.
Sometimes, Talos is unable to successfully kill off all of the disk access points, in which case it cannot safely unmount all filesystems to effect the upgrade.
In this case, it will abort the upgrade and reboot.
(upgrade --stage can ensure that upgrades can occur even when the filesytems cannot be unmounted.)
It is possible (especially with test builds) that the upgraded Talos system will fail to start.
In this case, the node will be rebooted, and the bootloader will automatically use the previous Talos kernel and image, thus effectively rolling back the upgrade.
Lastly, it is possible that Talos itself will upgrade successfully, start up, and rejoin the cluster but your workload will fail to run on it, for whatever reason.
This is when you would use the talosctl rollback command to revert back to the previous Talos version.
Q. Can upgrades be scheduled?
A. Because the upgrade sequence is API-driven, you can easily tie it in to your own business logic to schedule and coordinate your upgrades.
Q. Can the upgrade process be observed?
A. Yes, using the talosctl dmesg -f command.
You can also use talosctl upgrade --wait, and optionally talosctl upgrade --wait --debug to observe kernel logs
Q. Are worker node upgrades handled differently from control plane node upgrades?
A. Short answer: no.
Long answer: Both node types follow the same set procedure.
From the user’s standpoint, however, the processes are identical.
However, since control plane nodes run additional services, such as etcd, there are some extra steps and checks performed on them.
For instance, Talos will refuse to upgrade a control plane node if that upgrade would cause a loss of quorum for etcd.
If multiple control plane nodes are asked to upgrade at the same time, Talos will protect the Kubernetes cluster by ensuring only one control plane node actively upgrades at any time, via checking etcd quorum.
If running a single-node cluster, and you want to force an upgrade despite the loss of quorum, you can set preserve to true.
Q. Can I break my cluster by upgrading everything at once?
A. Possibly - it’s not recommended.
Nothing prevents the user from sending near-simultaneous upgrades to each node of the cluster - and while Talos Linux and Kubernetes can generally deal with this situation, other components of the cluster may not be able to recover from more than one node rebooting at a time.
(e.g. any software that maintains a quorum or state across nodes, such as Rook/Ceph)
3 - Kubernetes Guides
Management of a Kubernetes Cluster hosted by Talos Linux
3.1 - Configuration
How to configure components of the Kubernetes cluster itself.
3.1.1 - Azure Cloud Controller Manager and CSI driver for storage
Guide on how to install the Azure Cloud Controller Manager and Container Storage Interface driver in Kubernetes
This is a guide for installing the Azure Cloud Provider and Azure CSI.
The cloud-provider-azure module is used for interacting with Azure cloud resources through Kubernetes and this guide will also walk through setting up the CSI storage component to set up a StorageClass for workloads to use on the cluster.
The steps in this guide could be used for any Kubernetes cluster with the addition of the patch applied to a Talos cluster.
Pre -requisites
This guide assumes a Talos cluster is already available and the user has an Azure account set up.
There is an option in the Talos machine config to tell the control-plane to use an external controller manager.
This will apply an uninitialized label to a node when it registers to make it impossible to schedule workloads until the CCM has discovered that there is a new node in the cluster.
The Azure Cloud Controller Manager requires a configuration file to gain permissions on the cluster which will require gathering a few values from the Azure Portal and creating an app registration to give the CCM the permissions it needs.
This file is usually placed on the filesystem, but this guide will cover creating a secret to store this configuration instead.
App Registration
The App Registration is what we will use to authenticate to Azure for uploading blobs and creating resources.
For more information not in this guide or to see changes made to the app registration process, Azure’s documentation can be found here:
Select App registrations, then select New registration.
Name the application, for example “example-app”.
Select a supported account type, which determines who can use the application.
Under Redirect URI, select Web for the type of application and enter the URI where the access token is sent to.
Select Register.
Collect the following values from Azure, as they will be needed for the Azure CCM configuration file.
Tenant ID
Subscription ID
Client ID
Client Secret
Add permissions for App Registration
The App registration only needs permissions to the Compute Gallery and the Storage Account.
Select the Resource Group the Talos cluster is deployed in
Select Access control (IAM)
Select Add role assignment
Select the role needed for the account.
NOTE: This will vary depending on what the CCM is being used for, but Virtual Machine Contributor is enough for the purposes if this installation guide.
Collect additional information
In the Azure Portal, collected the following values to be used in the configuration file, specific to the cluster the CCM is being installed on:
Resource Group
Location
Virtual Network name
Route Table name
Create the configuration file
Create a configuration file named azure.cfg
vim cloud.conf
Add the following to the azure.cfg file, but replace the values with the values gathered at the beginning of this guide.
To use the latest release add the following helm repo:
NOTE: To use a release specific to the Kubernetes version other than the latest version, replace master with the branch name specified in the version matrix above.
Persistent Volume Claims can now be created for workloads in the cluster using the StorageClass created.
3.1.2 - Ceph Storage cluster with Rook
Guide on how to create a simple Ceph storage cluster with Rook for Kubernetes
Preparation
Talos Linux reserves an entire disk for the OS installation, so machines with multiple available disks are needed for a reliable Ceph cluster with Rook and Talos Linux.
Rook requires that the block devices or partitions used by Ceph have no partitions or formatted filesystems before use.
Rook also requires a minimum Kubernetes version of v1.16 and Helm v3.0 for installation of charts.
It is highly recommended that the Rook Ceph overview is read and understood before deploying a Ceph cluster with Rook.
Installation
Creating a Ceph cluster with Rook requires two steps; first the Rook Operator needs to be installed which can be done with a Helm Chart.
The example below installs the Rook Operator into the rook-ceph namespace, which is the default for a Ceph cluster with Rook.
$ helm repo add rook-release https://charts.rook.io/release
"rook-release" has been added to your repositories
$ helm install --create-namespace --namespace rook-ceph rook-ceph rook-release/rook-ceph
W0327 17:52:44.277830 54987 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0327 17:52:44.612243 54987 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: rook-ceph
LAST DEPLOYED: Sun Mar 27 17:52:42 2022NAMESPACE: rook-ceph
STATUS: deployed
REVISION: 1TEST SUITE: None
NOTES:
The Rook Operator has been installed. Check its status by running:
kubectl --namespace rook-ceph get pods -l "app=rook-ceph-operator"Visit https://rook.io/docs/rook/latest for instructions on how to create and configure Rook clusters
Important Notes:
- You must customize the 'CephCluster' resource in the sample manifests for your cluster.
- Each CephCluster must be deployed to its own namespace, the samples use `rook-ceph`for the namespace.
- The sample manifests assume you also installed the rook-ceph operator in the `rook-ceph` namespace.
- The helm chart includes all the RBAC required to create a CephCluster CRD in the same namespace.
- Any disk devices you add to the cluster in the 'CephCluster' must be empty (no filesystem and no partitions).
Once that is complete, the Ceph cluster can be installed with the official Helm Chart.
The Chart can be installed with default values, which will attempt to use all nodes in the Kubernetes cluster, and all unused disks on each node for Ceph storage, and make available block storage, object storage, as well as a shared filesystem.
Generally more specific node/device/cluster configuration is used, and the Rook documentation explains all the available options in detail.
For this example the defaults will be adequate.
$ helm install --create-namespace --namespace rook-ceph rook-ceph-cluster --set operatorNamespace=rook-ceph rook-release/rook-ceph-cluster
NAME: rook-ceph-cluster
LAST DEPLOYED: Sun Mar 27 18:12:46 2022NAMESPACE: rook-ceph
STATUS: deployed
REVISION: 1TEST SUITE: None
NOTES:
The Ceph Cluster has been installed. Check its status by running:
kubectl --namespace rook-ceph get cephcluster
Visit https://rook.github.io/docs/rook/latest/ceph-cluster-crd.html for more information about the Ceph CRD.
Important Notes:
- You can only deploy a single cluster per namespace
- If you wish to delete this cluster and start fresh, you will also have to wipe the OSD disks using `sfdisk`
Now the Ceph cluster configuration has been created, the Rook operator needs time to install the Ceph cluster and bring all the components online.
The progression of the Ceph cluster state can be followed with the following command.
$ watch kubectl --namespace rook-ceph get cephcluster rook-ceph
Every 2.0s: kubectl --namespace rook-ceph get cephcluster rook-ceph
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL
rook-ceph /var/lib/rook 3 57s Progressing Configuring Ceph Mons
Depending on the size of the Ceph cluster and the availability of resources the Ceph cluster should become available, and with it the storage classes that can be used with Kubernetes Physical Volumes.
$ kubectl --namespace rook-ceph get cephcluster rook-ceph
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL
rook-ceph /var/lib/rook 3 40m Ready Cluster created successfully HEALTH_OK
$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
ceph-block (default) rook-ceph.rbd.csi.ceph.com Delete Immediate true 77m
ceph-bucket rook-ceph.ceph.rook.io/bucket Delete Immediate false 77m
ceph-filesystem rook-ceph.cephfs.csi.ceph.com Delete Immediate true 77m
Talos Linux Considerations
It is important to note that a Rook Ceph cluster saves cluster information directly onto the node (by default dataDirHostPath is set to /var/lib/rook).
If running only a single mon instance, cluster management is little bit more involved, as any time a Talos Linux node is reconfigured or upgraded, the partition that stores the /varfile system is wiped, but the --preserve option of talosctl upgrade will ensure that doesn’t happen.
By default, Rook configues Ceph to have 3 mon instances, in which case the data stored in dataDirHostPath can be regenerated from the other mon instances.
So when performing maintenance on a Talos Linux node with a Rook Ceph cluster (e.g. upgrading the Talos Linux version), it is imperative that care be taken to maintain the health of the Ceph cluster.
Before upgrading, you should always check the health status of the Ceph cluster to ensure that it is healthy.
$ kubectl --namespace rook-ceph get cephclusters.ceph.rook.io rook-ceph
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL
rook-ceph /var/lib/rook 3 98m Ready Cluster created successfully HEALTH_OK
If it is, you can begin the upgrade process for the Talos Linux node, during which time the Ceph cluster will become unhealthy as the node is reconfigured.
Before performing any other action on the Talos Linux nodes, the Ceph cluster must return to a healthy status.
$ talosctl upgrade --nodes 172.20.15.5 --image ghcr.io/talos-systems/installer:v0.14.3
NODE ACK STARTED
172.20.15.5 Upgrade request received 2022-03-27 20:29:55.292432887 +0200 CEST m=+10.050399758
$ kubectl --namespace rook-ceph get cephclusters.ceph.rook.io
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL
rook-ceph /var/lib/rook 3 99m Progressing Configuring Ceph Mgr(s) HEALTH_WARN
$ kubectl --namespace rook-ceph wait --timeout=1800s --for=jsonpath='{.status.ceph.health}=HEALTH_OK' rook-ceph
cephcluster.ceph.rook.io/rook-ceph condition met
The above steps need to be performed for each Talos Linux node undergoing maintenance, one at a time.
Cleaning Up
Rook Ceph Cluster Removal
Removing a Rook Ceph cluster requires a few steps, starting with signalling to Rook that the Ceph cluster is really being destroyed.
Then all Persistent Volumes (and Claims) backed by the Ceph cluster must be deleted, followed by the Storage Classes and the Ceph storage types.
If the Rook Operator is cleanly removed following the above process, the node metadata and disks should be clean and ready to be re-used.
In the case of an unclean cluster removal, there may be still a few instances of metadata stored on the system disk, as well as the partition information on the storage disks.
First the node metadata needs to be removed, make sure to update the nodeName with the actual name of a storage node that needs cleaning, and path with the Rook configuration dataDirHostPath set when installing the chart.
The following will need to be repeated for each node used in the Rook Ceph cluster.
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: disk-clean
spec:
restartPolicy: Never
nodeName: <storage-node-name>
volumes:
- name: rook-data-dir
hostPath:
path: <dataDirHostPath>
containers:
- name: disk-clean
image: busybox
securityContext:
privileged: true
volumeMounts:
- name: rook-data-dir
mountPath: /node/rook-data
command: ["/bin/sh", "-c", "rm -rf /node/rook-data/*"]
EOFpod/disk-clean created
$ kubectl wait --timeout=900s --for=jsonpath='{.status.phase}=Succeeded' pod disk-clean
pod/disk-clean condition met
$ kubectl delete pod disk-clean
pod "disk-clean" deleted
Lastly, the disks themselves need the partition and filesystem data wiped before they can be reused.
Again, the following as to be repeated for each node and disk used in the Rook Ceph cluster, updating nodeName and of= in the command as needed.
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: disk-wipe
spec:
restartPolicy: Never
nodeName: <storage-node-name>
containers:
- name: disk-wipe
image: busybox
securityContext:
privileged: true
command: ["/bin/sh", "-c", "dd if=/dev/zero bs=1M count=100 oflag=direct of=<device>"]
EOFpod/disk-wipe created
$ kubectl wait --timeout=900s --for=jsonpath='{.status.phase}=Succeeded' pod disk-wipe
pod/disk-wipe condition met
$ kubectl delete pod disk-clean
pod "disk-wipe" deleted
3.1.3 - Cluster Endpoint
How to explicitly set up an endpoint for the cluster API
In this section, we will step through the configuration of a Talos based Kubernetes cluster.
There are three major components we will configure:
apid and talosctl
the controlplane nodes
the worker nodes
Talos enforces a high level of security by using mutual TLS for authentication and authorization.
We recommend that the configuration of Talos be performed by a cluster owner.
A cluster owner should be a person of authority within an organization, perhaps a director, manager, or senior member of a team.
They are responsible for storing the root CA, and distributing the PKI for authorized cluster administrators.
Recommended settings
Talos runs great out of the box, but if you tweak some minor settings it will make your life
a lot easier in the future.
This is not a requirement, but rather a document to explain some key settings.
Endpoint
To configure the talosctl endpoint, it is recommended you use a resolvable DNS name.
This way, if you decide to upgrade to a multi-controlplane cluster you only have to add the ip address to the hostname configuration.
The configuration can either be done on a Loadbalancer, or simply trough DNS.
For example:
This is in the config file for the cluster e.g. controlplane.yaml and worker.yaml.
for more details, please see: v1alpha1 endpoint configuration
If you have a DNS name as the endpoint, you can upgrade your talos cluster with multiple controlplanes in the future (if you don’t have a multi-controlplane setup from the start)
Using a DNS name generates the corresponding Certificates (Kubernetes and Talos) for the correct hostname.
3.1.4 - Deploying Metrics Server
In this guide you will learn how to set up metrics-server.
Metrics Server enables use of the Horizontal Pod Autoscaler and Vertical Pod Autoscaler.
It does this by gathering metrics data from the kubelets in a cluster.
By default, the certificates in use by the kubelets will not be recognized by metrics-server.
This can be solved by either configuring metrics-server to do no validation of the TLS certificates, or by modifying the kubelet configuration to rotate its certificates and use ones that will be recognized by metrics-server.
Node Configuration
To enable kubelet certificate rotation, all nodes should have the following Machine Config snippet:
We will want to ensure that new certificates for the kubelets are approved automatically.
This can easily be done with the Kubelet Serving Certificate Approver, which will automatically approve the Certificate Signing Requests generated by the kubelets.
We can have Kubelet Serving Certificate Approver and metrics-server installed on the cluster automatically during bootstrap by adding the following snippet to the Cluster Config of the node that will be handling the bootstrap process:
If you choose not to use extraManifests to install Kubelet Serving Certificate Approver and metrics-server during bootstrap, you can install them once the cluster is online using kubectl:
Automatically provision iSCSI volumes on a Synology NAS with the synology-csi driver.
Background
Synology is a company that specializes in Network Attached Storage (NAS) devices.
They provide a number of features within a simple web OS, including an LDAP server, Docker support, and (perhaps most relevant to this guide) function as an iSCSI host.
The focus of this guide is to allow a Kubernetes cluster running on Talos to provision Kubernetes storage (both dynamic or static) on a Synology NAS using a direct integration, rather than relying on an intermediary layer like Rook/Ceph or Maystor.
This guide assumes a very basic familiarity with iSCSI terminology (LUN, iSCSI target, etc.).
Prerequisites
Synology NAS running DSM 7.0 or above
Provisioned Talos cluster running Kubernetes v1.20 or above
The synology-csi controller interacts with your NAS in two different ways: via the API and via the iSCSI protocol.
Actions such as creating a new iSCSI target or deleting an old one are accomplished via the Synology API, and require administrator access.
On the other hand, mounting the disk to a pod and reading from / writing to it will utilize iSCSI.
Because you can only authenticate with one account per DSM configured, that account needs to have admin privileges.
In order to minimize access in the case of these credentials being compromised, you should configure the account with the lease possible amount of access – explicitly specify “No Access” on all volumes when configuring the user permissions.
Setting up the Synology CSI
Note: this guide is paraphrased from the Synology CSI readme.
Please consult the readme for more in-depth instructions and explanations.
While Synology provides some automated scripts to deploy the CSI driver, they can be finicky especially when making changes to the source code.
We will be configuring and deploying things manually in this guide.
The relevant files we will be touching are in the following locations:
Use config/client-info-template.yml as an example to configure the connection information for DSM.
You can specify one or more storage systems on which the CSI volumes will be created.
See below for an example:
---
clients:
- host: 192.168.1.1# ipv4 address or domain of the DSMport: 5000# port for connecting to the DSMhttps: false# set this true to use https. you need to specify the port to DSM HTTPS port as wellusername: username # usernamepassword: password # password
Create a Kubernetes secret using the client information config file.
Note that if you rename the secret to something other than client-info-secret, make sure you update the corresponding references in the deployment manifests as well.
Build the Talos-compatible image
Modify the Makefile so that the image is built and tagged under your GitHub Container Registry username:
REGISTRY_NAME=ghcr.io/<username>
When you run make docker-build or make docker-build-multiarch, it will push the resulting image to ghcr.io/<username>/synology-csi:v1.1.0.
Ensure that you find and change any reference to synology/synology-csi:v1.1.0 to point to your newly-pushed image within the deployment manifests.
Configure the CSI driver
By default, the deployment manifests include one storage class and one volume snapshot class.
See below for examples:
It can be useful to configure multiple different StorageClasses.
For example, a popular strategy is to create two nearly identical StorageClasses, with one configured with reclaimPolicy: Retain and the other with reclaimPolicy: Delete.
Alternately, a workload may require a specific filesystem, such as ext4.
If a Synology NAS is going to be the most common way to configure storage on your cluster, it can be convenient to add the storageclass.kubernetes.io/is-default-class: "true" annotation to one of your StorageClasses.
The following table details the configurable parameters for the Synology StorageClass.
Name
Type
Description
Default
Supported protocols
dsm
string
The IPv4 address of your DSM, which must be included in the client-info.yml for the CSI driver to log in to DSM
-
iSCSI, SMB
location
string
The location (/volume1, /volume2, …) on DSM where the LUN for PersistentVolume will be created
-
iSCSI, SMB
fsType
string
The formatting file system of the PersistentVolumes when you mount them on the pods. This parameter only works with iSCSI. For SMB, the fsType is always ‘cifs‘.
ext4
iSCSI
protocol
string
The backing storage protocol. Enter ‘iscsi’ to create LUNs or ‘smb‘ to create shared folders on DSM.
iscsi
iSCSI, SMB
csi.storage.k8s.io/node-stage-secret-name
string
The name of node-stage-secret. Required if DSM shared folder is accessed via SMB.
-
SMB
csi.storage.k8s.io/node-stage-secret-namespace
string
The namespace of node-stage-secret. Required if DSM shared folder is accessed via SMB.
-
SMB
The VolumeSnapshotClass can be similarly configured with the following parameters:
Name
Type
Description
Default
Supported protocols
description
string
The description of the snapshot on DSM
-
iSCSI
is_locked
string
Whether you want to lock the snapshot on DSM
false
iSCSI, SMB
Apply YAML manifests
Once you have created the desired StorageClass(es) and VolumeSnapshotClass(es), the final step is to apply the Kubernetes manifests against the cluster.
The easiest way to apply them all at once is to create a kustomization.yaml file in the same directory as the manifests and use Kustomize to apply:
kubectl apply -k path/to/manifest/directory
Alternately, you can apply each manifest one-by-one:
kubectl apply -f <file>
Run performance tests
In order to test the provisioning, mounting, and performance of using a Synology NAS as Kubernetes persistent storage, use the following command:
If these two jobs complete successfully, use the following commands to get the results of the speed tests:
# Pod logs for read test:kubectl logs -l app=speedtest,job=read# Pod logs for write test:kubectl logs -l app=speedtest,job=write
When you’re satisfied with the results of the test, delete the artifacts created from the speedtest:
kubectl delete -f speedtest.yaml
3.1.6 - Local Storage
Using local storage with OpenEBS Jiva
If you want to use replicated storage leveraging disk space from a local disk with Talos Linux installed, OpenEBS Jiva is a great option.
This requires installing the iscsi-toolssystem extension.
Since OpenEBS Jiva is a replicated storage, it’s recommended to have at least three nodes where sufficient local disk space is available.
The documentation will follow installing OpenEBS Jiva via the offical Helm chart.
Since Talos is different from standard Operating Systems, the OpenEBS components need a little tweaking after the Helm installation.
Refer to the OpenEBS Jiva documentation if you need further customization.
NB: Also note that the Talos nodes need to be upgraded with --preserve set while running OpenEBS Jiva, otherwise you risk losing data.
Even though it’s possible to recover data from other replicas if the node is wiped during an upgrade, this can require extra operational knowledge to recover, so it’s highly recommended to use --preserve to avoid data loss.
Preparing the nodes
Create a machine config patch with the contents below and save as patch.yaml
To install the system extension, the node needs to be upgraded.
If there is no new release of Talos, the node can be upgraded to the same version as the existing Talos version.
Run the following command on each nodes subsequently:
You should see that the ext-tgtd and the ext-iscsid services are running.
NODE SERVICE STATE HEALTH LAST CHANGE LAST EVENT
192.168.20.51 apid Running OK 64h57m15s ago Health check successful
192.168.20.51 containerd Running OK 64h57m23s ago Health check successful
192.168.20.51 cri Running OK 64h57m20s ago Health check successful
192.168.20.51 etcd Running OK 64h55m29s ago Health check successful
192.168.20.51 ext-iscsid Running ? 64h57m19s ago Started task ext-iscsid (PID 4040) for container ext-iscsid
192.168.20.51 ext-tgtd Running ? 64h57m19s ago Started task ext-tgtd (PID 3999) for container ext-tgtd
192.168.20.51 kubelet Running OK 38h14m10s ago Health check successful
192.168.20.51 machined Running ? 64h57m29s ago Service started as goroutine
192.168.20.51 trustd Running OK 64h57m19s ago Health check successful
192.168.20.51 udevd Running OK 64h57m21s ago Health check successful
This will create a storage class named openebs-jiva-csi-default which can be used for workloads.
The storage class named openebs-hostpath is used by jiva to create persistent volumes backed by local storage and then used for replicated storage by the jiva controller.
Patching the Namespace
when using the default Pod Security Admissions created by Talos you need the following labels on your namespace:
By Default Jiva uses 3 replicas if your cluster consists of lesser nodes consider setting defaultPolicy.replicas to the number of nodes in your cluster e.g. 2.
Patching the jiva installation
Since Jiva assumes iscisd to be running natively on the host and not as a Talos extension service, we need to modify the CSI node daemonset to enable it to find the PID of the iscsid service.
The default config map used by Jiva also needs to be modified so that it can execute iscsiadm commands inside the PID namespace of the iscsid service.
Start by creating a configmap definition named config.yaml as below:
Enabling Pod Security Admission plugin to configure Pod Security Standards.
Kubernetes deprecated Pod Security Policy as of v1.21, and it is
going to be removed in v1.25.
Pod Security Policy was replaced with Pod Security Admission.
Pod Security Admission is alpha in v1.22 (requires a feature gate) and beta in v1.23 (enabled by default).
In this guide we are going to enable and configure Pod Security Admission in Talos.
Configuration
Talos provides default Pod Security Admission in the machine configuration:
more strict restricted profile is not enforced, but API server warns about found issues
This default policy can be modified by updating the generated machine configuration before the cluster is created or on the fly by using the talosctl CLI utility.
Verify current admission plugin configuration with:
Create a deployment that satisfies the baseline policy but gives warnings on restricted policy:
$ kubectl create deployment nginx --image=nginx
Warning: would violate PodSecurity "restricted:latest": allowPrivilegeEscalation !=false(container "nginx" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "nginx" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot !=true(pod or container "nginx" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "nginx" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")deployment.apps/nginx created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-85b98978db-j68l8 1/1 Running 0 2m3s
Create a daemonset which fails to meet requirements of the baseline policy:
$ kubectl apply -f debug.yaml
Warning: would violate PodSecurity "restricted:latest": host namespaces (hostNetwork=true, hostPID=true, hostIPC=true), privileged (container "debug-container" must not set securityContext.privileged=true), allowPrivilegeEscalation !=false(container "debug-container" must set securityContext.allowPrivilegeEscalation=false), unrestricted capabilities (container "debug-container" must set securityContext.capabilities.drop=["ALL"]), runAsNonRoot !=true(pod or container "debug-container" must set securityContext.runAsNonRoot=true), seccompProfile (pod or container "debug-container" must set securityContext.seccompProfile.type to "RuntimeDefault" or "Localhost")daemonset.apps/debug-container created
Daemonset debug-container gets created, but no pods are scheduled:
$ kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
debug-container 00000 <none> 34s
Pod Security Admission plugin errors are in the daemonset events:
$ kubectl describe ds debug-container
...
Warning FailedCreate 92s daemonset-controller Error creating: pods "debug-container-kwzdj" is forbidden: violates PodSecurity "baseline:latest": host namespaces (hostNetwork=true, hostPID=true, hostIPC=true), privileged (container "debug-container" must not set securityContext.privileged=true)
Pod Security Admission configuration can also be overridden on a namespace level:
$ kubectl label ns default pod-security.kubernetes.io/enforce=privileged
namespace/default labeled
$ kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
debug-container 22020 <none> 4s
As enforce policy was updated to the privileged for the default namespace, debug-container is now successfully running.
3.1.8 - Seccomp Profiles
Using custom Seccomp Profiles with Kubernetes workloads.
Seccomp stands for secure computing mode and has been a feature of the Linux kernel since version 2.6.12.
It can be used to sandbox the privileges of a process, restricting the calls it is able to make from userspace into the kernel.
You can clean up the test resources by running the following command:
kubectl delete pod audit-pod
3.1.9 - Storage
Setting up storage for a Kubernetes cluster
In Kubernetes, using storage in the right way is well-facilitated by the API.
However, unless you are running in a major public cloud, that API may not be hooked up to anything.
This frequently sends users down a rabbit hole of researching all the various options for storage backends for their platform, for Kubernetes, and for their workloads.
There are a lot of options out there, and it can be fairly bewildering.
For Talos, we try to limit the options somewhat to make the decision-making easier.
Public Cloud
If you are running on a major public cloud, use their block storage.
It is easy and automatic.
Storage Clusters
Sidero Labs recommends having separate disks (apart from the Talos install disk) to be used for storage.
Redundancy, scaling capabilities, reliability, speed, maintenance load, and ease of use are all factors you must consider when managing your own storage.
Running a storage cluster can be a very good choice when managing your own storage, and there are two projects we recommend, depending on your situation.
If you need vast amounts of storage composed of more than a dozen or so disks, we recommend you use Rook to manage Ceph.
Also, if you need both mount-once and mount-many capabilities, Ceph is your answer.
Ceph also bundles in an S3-compatible object store.
The down side of Ceph is that there are a lot of moving parts.
Please note that most people should never use mount-many semantics.
NFS is pervasive because it is old and easy, not because it is a good idea.
While it may seem like a convenience at first, there are all manner of locking, performance, change control, and reliability concerns inherent in any mount-many situation, so we strongly recommend you avoid this method.
If your storage needs are small enough to not need Ceph, use Mayastor.
Rook/Ceph
Ceph is the grandfather of open source storage clusters.
It is big, has a lot of pieces, and will do just about anything.
It scales better than almost any other system out there, open source or proprietary, being able to easily add and remove storage over time with no downtime, safely and easily.
It comes bundled with RadosGW, an S3-compatible object store; CephFS, a NFS-like clustered filesystem; and RBD, a block storage system.
With the help of Rook, the vast majority of the complexity of Ceph is hidden away by a very robust operator, allowing you to control almost everything about your Ceph cluster from fairly simple Kubernetes CRDs.
So if Ceph is so great, why not use it for everything?
Ceph can be rather slow for small clusters.
It relies heavily on CPUs and massive parallelisation to provide good cluster performance, so if you don’t have much of those dedicated to Ceph, it is not going to be well-optimised for you.
Also, if your cluster is small, just running Ceph may eat up a significant amount of the resources you have available.
Troubleshooting Ceph can be difficult if you do not understand its architecture.
There are lots of acronyms and the documentation assumes a fair level of knowledge.
There are very good tools for inspection and debugging, but this is still frequently seen as a concern.
Mayastor
Mayastor is an OpenEBS project built in Rust utilising the modern NVMEoF system.
(Despite the name, Mayastor does not require you to have NVME drives.)
It is fast and lean but still cluster-oriented and cloud native.
Unlike most of the other OpenEBS project, it is not built on the ancient iSCSI system.
Unlike Ceph, Mayastor is just a block store.
It focuses on block storage and does it well.
It is much less complicated to set up than Ceph, but you probably wouldn’t want to use it for more than a few dozen disks.
Mayastor is new, maybe too new.
If you’re looking for something well-tested and battle-hardened, this is not it.
However, if you’re looking for something lean, future-oriented, and simpler than Ceph, it might be a great choice.
Video Walkthrough
To see a live demo of this section, see the video below:
Prep Nodes
Either during initial cluster creation or on running worker nodes, several machine config values should be edited.
(This information is gathered from the Mayastor documentation.)
We need to set the vm.nr_hugepages sysctl and add openebs.io/engine=mayastor labels to the nodes which are meant to be storage nodes.
This can be done with talosctl patch machineconfig or via config patches during talosctl gen config.
Some examples are shown below: modify as needed.
First create a config patch file named mayastor-patch.yaml with the following contents:
Note: If you are adding/updating the vm.nr_hugepages on a node which already had the openebs.io/engine=mayastor label set, you’d need to restart kubelet so that it picks up the new value, by issuing the following command
talosctl -n <node ip> service kubelet restart
Deploy Mayastor
Continue setting up Mayastor using the official documentation.
# Create device pool on a blank (no partitation table!) disk on node01kubectl linstor physical-storage create-device-pool --pool-name nvme_lvm_pool LVM node01 /dev/nvme0n1 --storage-pool nvme_pool
NFS is an old pack animal long past its prime.
NFS is slow, has all kinds of bottlenecks involving contention, distributed locking, single points of service, and more.
However, it is supported by a wide variety of systems.
You don’t want to use it unless you have to, but unfortunately, that “have to” is too frequent.
The NFS client is part of the kubelet image maintained by the Talos team.
This means that the version installed in your running kubelet is the version of NFS supported by Talos.
You can reduce some of the contention problems by parceling Persistent Volumes from separate underlying directories.
Object storage
Ceph comes with an S3-compatible object store, but there are other options, as
well.
These can often be built on top of other storage backends.
For instance, you may have your block storage running with Mayastor but assign a
Pod a large Persistent Volume to serve your object store.
One of the most popular open source add-on object stores is MinIO.
Others (iSCSI)
The most common remaining systems involve iSCSI in one form or another.
These include the original OpenEBS, Rancher’s Longhorn, and many proprietary systems.
iSCSI in Linux is facilitated by open-iscsi.
This system was designed long before containers caught on, and it is not well
suited to the task, especially when coupled with a read-only host operating
system.
iSCSI support in Talos is now supported via the iscsi-toolssystem extension installed.
The extension enables compatibility with OpenEBS Jiva - refer to the local storage installation guide for more information.
3.2 - Network
Managing the Kubernetes cluster networking
3.2.1 - Deploying Cilium CNI
In this guide you will learn how to set up Cilium CNI on Talos.
Cilium can be installed either via the cilium cli or using helm.
This documentation will outline installing Cilium CNI v1.13.0 on Talos in six different ways.
Adhering to Talos principles we’ll deploy Cilium with IPAM mode set to Kubernetes, and using the cgroupv2 mount that talos already provides.
As Talos does not allow loading kernel modules by Kubernetes workloads, SYS_MODULE capability needs to be dropped from the Cilium default set of values, this override can be seen in the helm/cilium cli install commands.
Each method can either install Cilium using kube proxy (default) or without: Kubernetes Without kube-proxy
Machine config preparation
When generating the machine config for a node set the CNI to none.
For example using a config patch:
Create a patch.yaml file with the following contents:
cluster:
network:
cni:
name: none
talosctl gen config \
my-cluster https://mycluster.local:6443 \
--config-patch @patch.yaml
Or if you want to deploy Cilium in strict mode without kube-proxy, you also need to disable kube proxy:
Create a patch.yaml file with the following contents:
talosctl gen config \
my-cluster https://mycluster.local:6443 \
--config-patch @patch.yaml
Installation using Cilium CLI
Note: It is recommended to template the cilium manifest using helm and use it as part of Talos machine config, but if you want to install Cilium using the Cilium CLI, you can follow the steps below.
After applying the machine config and bootstrapping Talos will appear to hang on phase 18/19 with the message: retrying error: node not ready.
This happens because nodes in Kubernetes are only marked as ready once the CNI is up.
As there is no CNI defined, the boot process is pending and will reboot the node to retry after 10 minutes, this is expected behavior.
During this window you can install Cilium manually by running the following:
exportKUBERNETES_API_SERVER_ADDRESS=<replace with api server endpoint here> # e.g. 10.96.0.1exportKUBERNETES_API_SERVER_PORT=6443helm template \
cilium \
cilium/cilium \
--version 1.13.0 \
--namespace kube-system \
--set ipam.mode=kubernetes \
--set=kubeProxyReplacement=strict \
--set=securityContext.capabilities.ciliumAgent="{CHOWN,KILL,NET_ADMIN,NET_RAW,IPC_LOCK,SYS_ADMIN,SYS_RESOURCE,DAC_OVERRIDE,FOWNER,SETGID,SETUID}"\
--set=securityContext.capabilities.cleanCiliumState="{NET_ADMIN,SYS_ADMIN,SYS_RESOURCE}"\
--set=cgroup.autoMount.enabled=false\
--set=cgroup.hostRoot=/sys/fs/cgroup \
--set=k8sServiceHost="${KUBERNETES_API_SERVER_ADDRESS}"\
--set=k8sServicePort="${KUBERNETES_API_SERVER_PORT}" > cilium.yaml
kubectl apply -f cilium.yaml
Method 3: Helm manifests hosted install
After generating cilium.yaml using helm template, instead of applying this manifest directly during the Talos boot window (before the reboot timeout).
You can also host this file somewhere and patch the machine config to apply this manifest automatically during bootstrap.
To do this patch your machine configuration to include this config instead of the above:
Create a patch.yaml file with the following contents:
talosctl gen config \
my-cluster https://mycluster.local:6443 \
--config-patch @patch.yaml
However, beware of the fact that the helm generated Cilium manifest contains sensitive key material.
As such you should definitely not host this somewhere publicly accessible.
Method 4: Helm manifests inline install
A more secure option would be to include the helm template output manifest inside the machine configuration.
The machine config should be generated with CNI set to none
Create a patch.yaml file with the following contents:
cluster:
network:
cni:
name: none
talosctl gen config \
my-cluster https://mycluster.local:6443 \
--config-patch @patch.yaml
if deploying Cilium with kube-proxy disabled, you can also include the following:
Create a patch.yaml file with the following contents:
This will install the Cilium manifests at just the right time during bootstrap.
Beware though:
Changing the namespace when templating with Helm does not generate a manifest containing the yaml to create that namespace.
As the inline manifest is processed from top to bottom make sure to manually put the namespace yaml at the start of the inline manifest.
Only add the Cilium inline manifest to the control plane nodes machine configuration.
Make sure all control plane nodes have an identical configuration.
If you delete any of the generated resources they will be restored whenever a control plane node reboots.
As a safety measure, Talos only creates missing resources from inline manifests, it never deletes or updates anything.
If you need to update a manifest make sure to first edit all control plane machine configurations and then run talosctl upgrade-k8s as it will take care of updating inline manifests.
Learn to use KubeSpan to connect Talos Linux machines securely across networks.
KubeSpan is a feature of Talos that automates the setup and maintenance of a full mesh WireGuard network for your cluster, giving you the ability to operate hybrid Kubernetes clusters that can span the edge, datacenter, and cloud.
Management of keys and discovery of peers can be completely automated for a zero-touch experience that makes it simple and easy to create hybrid clusters.
KubeSpan consists of client code in Talos Linux, as well as a discovery service that enables clients to securely find each other.
Sidero Labs operates a free Discovery Service, but the discovery service may be operated by your organization and can be downloaded here.
Video Walkthrough
To learn more about KubeSpan, see the video below:
To see a live demo of KubeSpan, see one the videos below:
Enabling
Creating a New Cluster
To generate configuration files for a new cluster, we can use the --with-kubespan flag in talosctl gen config.
This will enable peer discovery and KubeSpan.
machine:
network:
kubespan:
enabled: true# Enable the KubeSpan feature.cluster:
discovery:
enabled: true# Configure registries used for cluster member discovery.registries:
kubernetes: # Kubernetes registry is problematic with KubeSpan, if the control plane endpoint is routeable itself via KubeSpan.disabled: trueservice: {}
The default discovery service is an external service hosted for free by Sidero Labs.
The default value is https://discovery.talos.dev/.
Contact Sidero Labs if you need to run this service privately.
Enabling for an Existing Cluster
In order to enable KubeSpan for an existing cluster, enable kubespan and discovery settings in the machine config for each machine in the cluster (discovery is enabled by default):
The setting advertiseKubernetesNetworks controls whether the node will advertise Kubernetes service and pod networks to other nodes in the cluster over KubeSpan.
It defaults to being disabled, which means KubeSpan only controls the node-to-node traffic, while pod-to-pod traffic is routed and encapsulated by CNI.
This setting should not be enabled with Calico and Cilium CNI plugins, as they do their own pod IP allocation which is not visible to KubeSpan.
The setting allowDownPeerBypass controls whether the node will allow traffic to bypass WireGuard if the destination is not connected over KubeSpan.
If enabled, there is a risk that traffic will be routed unencrypted if the destination is not connected over KubeSpan, but it allows a workaround
for the case where a node is not connected to the KubeSpan network, but still needs to access the cluster.
The mtu setting configures the Wireguard MTU, which defaults to 1420.
This default value of 1420 is safe to use when the underlying network MTU is 1500, but if the underlying network MTU is smaller, the KubeSpanMTU should be adjusted accordingly:
KubeSpanMTU = UnderlyingMTU - 80.
The filters setting allows to hide some endpoints from being advertised over KubeSpan.
This is useful when some endpoints are known to be unreachable between the nodes, so that KubeSpan doesn’t try to establish a connection to them.
Another use-case is hiding some endpoints if nodes can connect on multiple networks, and some of the networks are more preferable than others.
Resource Definitions
KubeSpanIdentities
A node’s WireGuard identities can be obtained with:
Talos automatically configures unique IPv6 address for each node in the cluster-specific IPv6 ULA prefix.
Wireguard private key is generated for the node, private key never leaves the node while public key is published through the cluster discovery.
KubeSpanIdentity is persisted across reboots and upgrades in STATE partition in the file kubespan-identity.yaml.
KubeSpanPeerSpecs
A node’s WireGuard peers can be obtained with:
$ talosctl get kubespanpeerspecs
ID VERSION LABEL ENDPOINTS
06D9QQOydzKrOL7oeLiqHy9OWE8KtmJzZII2A5/FLFI=2 talos-default-controlplane-2 ["172.20.0.3:51820"]THtfKtfNnzJs1nMQKs5IXqK0DFXmM//0WMY+NnaZrhU=2 talos-default-controlplane-3 ["172.20.0.4:51820"]nVHu7l13uZyk0AaI1WuzL2/48iG8af4WRv+LWmAax1M=2 talos-default-worker-2 ["172.20.0.6:51820"]zXP0QeqRo+CBgDH1uOBiQ8tA+AKEQP9hWkqmkE/oDlc=2 talos-default-worker-1 ["172.20.0.5:51820"]
The peer ID is the Wireguard public key.
KubeSpanPeerSpecs are built from the cluster discovery data.
KubeSpanPeerStatuses
The status of a node’s WireGuard peers can be obtained with:
$ talosctl get kubespanpeerstatuses
ID VERSION LABEL ENDPOINT STATE RX TX
06D9QQOydzKrOL7oeLiqHy9OWE8KtmJzZII2A5/FLFI=63 talos-default-controlplane-2 172.20.0.3:51820 up 1504322017869488THtfKtfNnzJs1nMQKs5IXqK0DFXmM//0WMY+NnaZrhU=62 talos-default-controlplane-3 172.20.0.4:51820 up 1457320818157680nVHu7l13uZyk0AaI1WuzL2/48iG8af4WRv+LWmAax1M=60 talos-default-worker-2 172.20.0.6:51820 up 13007246888zXP0QeqRo+CBgDH1uOBiQ8tA+AKEQP9hWkqmkE/oDlc=60 talos-default-worker-1 172.20.0.5:51820 up 13004446556
KubeSpan peer status includes following information:
the actual endpoint used for peer communication
link state:
unknown: the endpoint was just changed, link state is not known yet
up: there is a recent handshake from the peer
down: there is no handshake from the peer
number of bytes sent/received over the Wireguard link with the peer
If the connection state goes down, Talos will be cycling through the available endpoints until it finds the one which works.
Peer status information is updated every 30 seconds.
KubeSpanEndpoints
A node’s WireGuard endpoints (peer addresses) can be obtained with:
$ talosctl get kubespanendpoints
ID VERSION ENDPOINT AFFILIATE ID
06D9QQOydzKrOL7oeLiqHy9OWE8KtmJzZII2A5/FLFI=1 172.20.0.3:51820 2VfX3nu67ZtZPl57IdJrU87BMjVWkSBJiL9ulP9TCnF
THtfKtfNnzJs1nMQKs5IXqK0DFXmM//0WMY+NnaZrhU=1 172.20.0.4:51820 b3DebkPaCRLTLLWaeRF1ejGaR0lK3m79jRJcPn0mfA6C
nVHu7l13uZyk0AaI1WuzL2/48iG8af4WRv+LWmAax1M=1 172.20.0.6:51820 NVtfu1bT1QjhNq5xJFUZl8f8I8LOCnnpGrZfPpdN9WlB
zXP0QeqRo+CBgDH1uOBiQ8tA+AKEQP9hWkqmkE/oDlc=1 172.20.0.5:51820 6EVq8RHIne03LeZiJ60WsJcoQOtttw1ejvTS6SOBzhUA
The endpoint ID is the base64 encoded WireGuard public key.
The observed endpoints are submitted back to the discovery service (if enabled) so that other peers can try additional endpoints to establish the connection.
3.3 - Upgrading Kubernetes
Guide on how to upgrade the Kubernetes cluster from Talos Linux.
This guide covers upgrading Kubernetes on Talos Linux clusters.
For a list of Kubernetes versions compatible with each Talos release, see the Support Matrix.
For upgrading the Talos Linux operating system, see Upgrading Talos
Video Walkthrough
To see a demo of this process, watch this video:
Automated Kubernetes Upgrade
The recommended method to upgrade Kubernetes is to use the talosctl upgrade-k8s command.
This will automatically update the components needed to upgrade Kubernetes safely.
Upgrading Kubernetes is non-disruptive to the cluster workloads.
To trigger a Kubernetes upgrade, issue a command specifiying the version of Kubernetes to ugprade to, such as:
Note that the --nodes parameter specifies the control plane node to send the API call to, but all members of the cluster will be upgraded.
To check what will be upgraded you can run talosctl upgrade-k8s with the --dry-run flag:
$ talosctl --nodes <controlplane node> upgrade-k8s --to 1.27.4 --dry-run
WARNING: found resources which are going to be deprecated/migrated in the version 1.27.4
RESOURCE COUNT
validatingwebhookconfigurations.v1beta1.admissionregistration.k8s.io 4mutatingwebhookconfigurations.v1beta1.admissionregistration.k8s.io 3customresourcedefinitions.v1beta1.apiextensions.k8s.io 25apiservices.v1beta1.apiregistration.k8s.io 54leases.v1beta1.coordination.k8s.io 4automatically detected the lowest Kubernetes version 1.26.3
checking for resource APIs to be deprecated in version 1.27.4
discovered controlplane nodes ["172.20.0.2""172.20.0.3""172.20.0.4"]discovered worker nodes ["172.20.0.5""172.20.0.6"]updating "kube-apiserver" to version "1.27.4" > "172.20.0.2": starting update
> update kube-apiserver: v1.26.3 -> 1.27.4
> skipped in dry-run
> "172.20.0.3": starting update
> update kube-apiserver: v1.26.3 -> 1.27.4
> skipped in dry-run
> "172.20.0.4": starting update
> update kube-apiserver: v1.26.3 -> 1.27.4
> skipped in dry-run
updating "kube-controller-manager" to version "1.27.4" > "172.20.0.2": starting update
> update kube-controller-manager: v1.26.3 -> 1.27.4
> skipped in dry-run
> "172.20.0.3": starting update
<snip>
updating manifests
> apply manifest Secret bootstrap-token-3lb63t
> apply skipped in dry run
> apply manifest ClusterRoleBinding system-bootstrap-approve-node-client-csr
> apply skipped in dry run
<snip>
To upgrade Kubernetes from v1.26.3 to v1.27.4 run:
$ talosctl --nodes <controlplane node> upgrade-k8s --to 1.27.4
automatically detected the lowest Kubernetes version 1.26.3
checking for resource APIs to be deprecated in version 1.27.4
discovered controlplane nodes ["172.20.0.2""172.20.0.3""172.20.0.4"]discovered worker nodes ["172.20.0.5""172.20.0.6"]updating "kube-apiserver" to version "1.27.4" > "172.20.0.2": starting update
> update kube-apiserver: v1.26.3 -> 1.27.4
> "172.20.0.2": machine configuration patched
> "172.20.0.2": waiting for API server state pod update
< "172.20.0.2": successfully updated
> "172.20.0.3": starting update
> update kube-apiserver: v1.26.3 -> 1.27.4
<snip>
This command runs in several phases:
Every control plane node machine configuration is patched with the new image version for each control plane component.
Talos renders new static pod definitions on the configuration update which is picked up by the kubelet.
The command waits for the change to propagate to the API server state.
The command updates the kube-proxy daemonset with the new image version.
On every node in the cluster, the kubelet version is updated.
The command then waits for the kubelet service to be restarted and become healthy.
The update is verified by checking the Node resource state.
Kubernetes bootstrap manifests are re-applied to the cluster.
Updated bootstrap manifests might come with a new Talos version (e.g. CoreDNS version update), or might be the result of machine configuration change.
Note: The upgrade-k8s command never deletes any resources from the cluster: they should be deleted manually.
If the command fails for any reason, it can be safely restarted to continue the upgrade process from the moment of the failure.
Manual Kubernetes Upgrade
Kubernetes can be upgraded manually by following the steps outlined below.
They are equivalent to the steps performed by the talosctl upgrade-k8s command.
Kubeconfig
In order to edit the control plane, you need a working kubectl config.
If you don’t already have one, you can get one by running:
talosctl --nodes <controlplane node> kubeconfig
API Server
Patch machine configuration using talosctl patch command:
$ talosctl -n <CONTROL_PLANE_IP_1> patch mc --mode=no-reboot -p '[{"op": "replace", "path": "/cluster/apiServer/image", "value": "registry.k8s.io/kube-apiserver:v1.27.4"}]'patched mc at the node 172.20.0.2
The JSON patch might need to be adjusted if current machine configuration is missing .cluster.apiServer.image key.
Also the machine configuration can be edited manually with talosctl -n <IP> edit mc --mode=no-reboot.
Capture the new version of kube-apiserver config with:
In this example, the new version is 5.
Wait for the new pod definition to propagate to the API server state (replace talos-default-controlplane-1 with the node name):
$ kubectl get pod -n kube-system -l k8s-app=kube-apiserver --field-selector spec.nodeName=talos-default-controlplane-1 -o jsonpath='{.items[0].metadata.annotations.talos\.dev/config\-version}'5
Check that the pod is running:
$ kubectl get pod -n kube-system -l k8s-app=kube-apiserver --field-selector spec.nodeName=talos-default-controlplane-1
NAME READY STATUS RESTARTS AGE
kube-apiserver-talos-default-controlplane-1 1/1 Running 0 16m
Repeat this process for every control plane node, verifying that state got propagated successfully between each node update.
Controller Manager
Patch machine configuration using talosctl patch command:
$ talosctl -n <CONTROL_PLANE_IP_1> patch mc --mode=no-reboot -p '[{"op": "replace", "path": "/cluster/controllerManager/image", "value": "registry.k8s.io/kube-controller-manager:v1.27.4"}]'patched mc at the node 172.20.0.2
The JSON patch might need be adjusted if current machine configuration is missing .cluster.controllerManager.image key.
Capture new version of kube-controller-manager config with:
In this example, new version is 3.
Wait for the new pod definition to propagate to the API server state (replace talos-default-controlplane-1 with the node name):
$ kubectl get pod -n kube-system -l k8s-app=kube-controller-manager --field-selector spec.nodeName=talos-default-controlplane-1 -o jsonpath='{.items[0].metadata.annotations.talos\.dev/config\-version}'3
Check that the pod is running:
$ kubectl get pod -n kube-system -l k8s-app=kube-controller-manager --field-selector spec.nodeName=talos-default-controlplane-1
NAME READY STATUS RESTARTS AGE
kube-controller-manager-talos-default-controlplane-1 1/1 Running 0 35m
Repeat this process for every control plane node, verifying that state propagated successfully between each node update.
Scheduler
Patch machine configuration using talosctl patch command:
$ talosctl -n <CONTROL_PLANE_IP_1> patch mc --mode=no-reboot -p '[{"op": "replace", "path": "/cluster/scheduler/image", "value": "registry.k8s.io/kube-scheduler:v1.27.4"}]'patched mc at the node 172.20.0.2
JSON patch might need be adjusted if current machine configuration is missing .cluster.scheduler.image key.
Capture new version of kube-scheduler config with:
In this example, new version is 3.
Wait for the new pod definition to propagate to the API server state (replace talos-default-controlplane-1 with the node name):
$ kubectl get pod -n kube-system -l k8s-app=kube-scheduler --field-selector spec.nodeName=talos-default-controlplane-1 -o jsonpath='{.items[0].metadata.annotations.talos\.dev/config\-version}'3
Check that the pod is running:
$ kubectl get pod -n kube-system -l k8s-app=kube-scheduler --field-selector spec.nodeName=talos-default-controlplane-1
NAME READY STATUS RESTARTS AGE
kube-scheduler-talos-default-controlplane-1 1/1 Running 0 39m
Repeat this process for every control plane node, verifying that state got propagated successfully between each node update.
Note: if some bootstrap resources were removed, they have to be removed from the cluster manually.
kubelet
For every node, patch machine configuration with new kubelet version, wait for the kubelet to restart with new version:
$ talosctl -n <IP> patch mc --mode=no-reboot -p '[{"op": "replace", "path": "/machine/kubelet/image", "value": "ghcr.io/siderolabs/kubelet:v1.27.4"}]'patched mc at the node 172.20.0.2
Once kubelet restarts with the new configuration, confirm upgrade with kubectl get nodes <name>:
$ kubectl get nodes talos-default-controlplane-1
NAME STATUS ROLES AGE VERSION
talos-default-controlplane-1 Ready control-plane 123m v1.27.4
4 - Advanced Guides
4.1 - Advanced Networking
How to configure advanced networking options on Talos Linux.
Static Addressing
Static addressing is comprised of specifying addresses, routes ( remember to add your default gateway ), and interface.
Most likely you’ll also want to define the nameservers so you have properly functioning DNS.
In some environments you may need to set additional addresses on an interface.
In the following example, we set two additional addresses on the loopback interface.
Setting up Talos Linux to work in environments with no internet access.
In this guide we will create a Talos cluster running in an air-gapped environment with all the required images being pulled from an internal registry.
We will use the QEMU provisioner available in talosctl to create a local cluster, but the same approach could be used to deploy Talos in bigger air-gapped networks.
In air-gapped environments, access to the public Internet is restricted, so Talos can’t pull images from public Docker registries (docker.io, ghcr.io, etc.)
We need to identify the images required to install and run Talos.
The same strategy can be used for images required by custom workloads running on the cluster.
The talosctl images command provides a list of default images used by the Talos cluster (with default configuration
settings).
To print the list of images, run:
talosctl images
This list contains images required by a default deployment of Talos.
There might be additional images required for the workloads running on this cluster, and those should be added to this list.
Preparing the Internal Registry
As access to the public registries is restricted, we have to run an internal Docker registry.
In this guide, we will launch the registry on the same machine using Docker:
This registry will be accepting connections on port 6000 on the host IPs.
The registry is empty by default, so we have fill it with the images required by Talos.
First, we pull all the images to our local Docker daemon:
$ for image in `talosctl images`; do docker pull $image; donev0.15.1: Pulling from coreos/flannel
Digest: sha256:9a296fbb67790659adc3701e287adde3c59803b7fcefe354f1fc482840cdb3d9
...
All images are now stored in the Docker daemon store:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
gcr.io/etcd-development/etcd v3.5.3 604d4f022632 6 days ago 181MB
ghcr.io/siderolabs/install-cni v1.0.0-2-gc5d3ab0 4729e54f794d 6 days ago 76MB
...
Now we need to re-tag them so that we can push them to our local registry.
We are going to replace the first component of the image name (before the first slash) with our registry endpoint 127.0.0.1:6000:
$ for image in `talosctl images`; do\
docker tag $image`echo$image | sed -E 's#^[^/]+/#127.0.0.1:6000/#'`; \
done
As the next step, we push images to the internal registry:
$ for image in `talosctl images`; do\
docker push `echo$image | sed -E 's#^[^/]+/#127.0.0.1:6000/#'`; \
done
We can now verify that the images are pushed to the registry:
Note: images in the registry don’t have the registry endpoint prefix anymore.
Launching Talos in an Air-gapped Environment
For Talos to use the internal registry, we use the registry mirror feature to redirect all image pull requests to the internal registry.
This means that the registry endpoint (as the first component of the image reference) gets ignored, and all pull requests are sent directly to the specified endpoint.
We are going to use a QEMU-based Talos cluster for this guide, but the same approach works with Docker-based clusters as well.
As QEMU-based clusters go through the Talos install process, they can be used better to model a real air-gapped environment.
Identify all registry prefixes from talosctl images, for example:
docker.io
gcr.io
ghcr.io
registry.k8s.io
The talosctl cluster create command provides conveniences for common configuration options.
The only required flag for this guide is --registry-mirror <endpoint>=http://10.5.0.1:6000 which redirects every pull request to the internal registry, this flag
needs to be repeated for each of the identified registry prefixes above.
The endpoint being used is 10.5.0.1, as this is the default bridge interface address which will be routable from the QEMU VMs (127.0.0.1 IP will be pointing to the VM itself).
$ sudo --preserve-env=HOME talosctl cluster create --provisioner=qemu --install-image=ghcr.io/siderolabs/installer:v1.4.8 \
--registry-mirror docker.io=http://10.5.0.1:6000 \
--registry-mirror gcr.io=http://10.5.0.1:6000 \
--registry-mirror ghcr.io=http://10.5.0.1:6000 \
--registry-mirror registry.k8s.io=http://10.5.0.1:6000 \
validating CIDR and reserving IPs
generating PKI and tokens
creating state directory in "/home/user/.talos/clusters/talos-default"creating network talos-default
creating load balancer
creating dhcpd
creating master nodes
creating worker nodes
waiting for API
...
Note: --install-image should match the image which was copied into the internal registry in the previous step.
You can be verify that the cluster is air-gapped by inspecting the registry logs: docker logs -f registry-airgapped.
Closing Notes
Running in an air-gapped environment might require additional configuration changes, for example using custom settings for DNS and NTP servers.
When scaling this guide to the bare-metal environment, following Talos config snippet could be used as an equivalent of the --registry-mirror flag above:
Other implementations of Docker registry can be used in place of the Docker registry image used above to run the registry.
If required, auth can be configured for the internal registry (and custom TLS certificates if needed).
If building for a specific release, checkout the corresponding tag:
git checkout v1.4.8
Set up the Build Environment
See Developing Talos for details on setting up the buildkit builder.
Architectures
By default, Talos builds for linux/amd64, but you can customize that by passing PLATFORM variable to make:
make <target> PLATFORM=linux/arm64 # build for arm64 onlymake <target> PLATFORM=linux/arm64,linux/amd64 # build for arm64 and amd64, container images will be multi-arch
Customizations
Some of the build parameters can be customized by passing environment variables to make, e.g. GOAMD64=v1 can be used to build
Talos images compatible with old AMD64 CPUs:
make <target> GOAMD64=v1
Building Kernel and Initramfs
The most basic boot assets can be built with:
make kernel initramfs
Build result will be stored as _out/vmlinuz-<arch> and _out/initramfs-<arch>.xz.
Building Container Images
Talos container images should be pushed to the registry as the result of the build process.
The default settings are:
IMAGE_REGISTRY is set to ghcr.io
USERNAME is set to the siderolabs (or value of environment variable USERNAME if it is set)
The image can be pushed to any registry you have access to, but the access credentials should be stored in ~/.docker/config.json file (e.g. with docker login).
The ISO image is built with the help of imager container image, by default ghcr.io/siderolabs/imager will be used with the matching tag:
make iso
The ISO image will be stored as _out/talos-<arch>.iso.
If ISO image should be built with the custom imager image, it can be specified with IMAGE_REGISTRY/USERNAME variables:
make iso IMAGE_REGISTRY=docker.io USERNAME=<username>
Building Disk Images
The disk image is built with the help of imager container image, by default ghcr.io/siderolabs/imager will be used with the matching tag:
make image-metal
Available disk images are encoded in the image-% target, e.g. make image-aws.
Same as with ISO image, the custom imager image can be specified with IMAGE_REGISTRY/USERNAME variables.
4.4 - Customizing the Kernel
Guide on how to customize the kernel used by Talos Linux.
The installer image contains ONBUILD instructions that handle the following:
the decompression, and unpacking of the initramfs.xz
the unsquashing of the rootfs
the copying of new rootfs files
the squashing of the new rootfs
and the packing, and compression of the new initramfs.xz
When used as a base image, the installer will perform the above steps automatically with the requirement that a customization stage be defined in the Dockerfile.
Build and push your own kernel:
git clone https://github.com/talos-systems/pkgs.git
cd pkgs
make kernel-menuconfig USERNAME=_your_github_user_name_
docker login ghcr.io --username _your_github_user_name_
make kernel USERNAME=_your_github_user_name_ PUSH=true
Using a multi-stage Dockerfile we can define the customization stage and build FROM the installer image:
FROM scratch AS customizationCOPY --from=<custom kernel image> /lib/modules /lib/modules
FROM ghcr.io/siderolabs/installer:latestCOPY --from=<custom kernel image> /boot/vmlinuz /usr/install/${TARGETARCH}/vmlinuz
When building the image, the customization stage will automatically be copied into the rootfs.
The customization stage is not limited to a single COPY instruction.
In fact, you can do whatever you would like in this stage, but keep in mind that everything in / will be copied into the rootfs.
Note: buildkit has a bug #816, to disable it use DOCKER_BUILDKIT=0
Now that we have a custom installer we can build Talos for the specific platform we wish to deploy to.
4.5 - Customizing the Root Filesystem
How to add your own content to the immutable root file system of Talos Linux.
The installer image contains ONBUILD instructions that handle the following:
the decompression, and unpacking of the initramfs.xz
the unsquashing of the rootfs
the copying of new rootfs files
the squashing of the new rootfs
and the packing, and compression of the new initramfs.xz
When used as a base image, the installer will perform the above steps automatically with the requirement that a customization stage be defined in the Dockerfile.
For example, say we have an image that contains the contents of a library we wish to add to the Talos rootfs.
We need to define a stage with the name customization:
FROM scratch AS customizationCOPY --from=<name|index> <src> <dest>
Using a multi-stage Dockerfile we can define the customization stage and build FROM the installer image:
FROM scratch AS customizationCOPY --from=<name|index> <src> <dest>
FROM ghcr.io/siderolabs/installer:latest
When building the image, the customization stage will automatically be copied into the rootfs.
The customization stage is not limited to a single COPY instruction.
In fact, you can do whatever you would like in this stage, but keep in mind that everything in / will be copied into the rootfs.
Note: <dest> is the path relative to the rootfs that you wish to place the contents of <src>.
This will perform a rm -rf on the specified paths relative to the rootfs.
Note: RM must be a whitespace delimited list.
The resulting image can be used to:
generate an image for any of the supported providers
perform bare-metall installs
perform upgrades
We will step through common customizations in the remainder of this section.
4.6 - Developing Talos
Learn how to set up a development environment for local testing and hacking on Talos itself!
This guide outlines steps and tricks to develop Talos operating systems and related components.
The guide assumes Linux operating system on the development host.
Some steps might work under Mac OS X, but using Linux is highly advised.
Note: network=host allows buildx builder to access host network, so that it can push to a local container registry (see below).
Make sure the following steps work:
make talosctl
make initramfs kernel
Set up a local docker registry:
docker run -d -p 5005:5000 \
--restart always \
--name local registry:2
Try to build and push to local registry an installer image:
make installer IMAGE_REGISTRY=127.0.0.1:5005 PUSH=true
Record the image name output in the step above.
Note: it is also possible to force a stable image tag by using TAG variable: make installer IMAGE_REGISTRY=127.0.0.1:5005 TAG=v1.0.0-alpha.1 PUSH=true.
Running Talos cluster
Set up local caching docker registries (this speeds up Talos cluster boot a lot), script is in the Talos repo:
custom --cidr to make QEMU cluster use different network than default Docker setup (optional)
--registry-mirror uses the caching proxies set up above to speed up boot time a lot, last one adds your local registry (installer image was pushed to it)
--install-image is the image you built with make installer above
--controlplanes & --workers configure cluster size, choose to match your resources; 3 controlplanes give you HA control plane; 1 controlplane is enough, never do 2 controlplanes
--with-bootloader=false disables boot from disk (Talos will always boot from _out/vmlinuz-amd64 and _out/initramfs-amd64.xz).
This speeds up development cycle a lot - no need to rebuild installer and perform install, rebooting is enough to get new code.
Note: as boot loader is not used, it’s not necessary to rebuild installer each time (old image is fine), but sometimes it’s needed (when configuration changes are done and old installer doesn’t validate the config).
talosctl cluster create derives Talos machine configuration version from the install image tag, so sometimes early in the development cycle (when new minor tag is not released yet), machine config version can be overridden with --talos-version=v1.4.
If the --with-bootloader=false flag is not enabled, for Talos cluster to pick up new changes to the code (in initramfs), it will require a Talos upgrade (so new installer should be built).
With --with-bootloader=false flag, Talos always boots from initramfs in _out/ directory, so simple reboot is enough to pick up new code changes.
If the installation flow needs to be tested, --with-bootloader=false shouldn’t be used.
Once talosctl cluster create finishes successfully, talosconfig and kubeconfig will be set up automatically to point to your cluster.
Start playing with talosctl:
talosctl -n 172.20.0.2 version
talosctl -n 172.20.0.3,172.20.0.4 dashboard
talosctl -n 172.20.0.4 get members
Same with kubectl:
kubectl get nodes -o wide
You can deploy some Kubernetes workloads to the cluster.
You can edit machine config on the fly with talosctl edit mc --immediate, config patches can be applied via --config-patch flags, also many features have specific flags in talosctl cluster create.
Quick Reboot
To reboot whole cluster quickly (e.g. to pick up a change made in the code):
for socket in ~/.talos/clusters/talos-default/talos-default-*.monitor; doecho"q" | sudo socat - unix-connect:$socket; done
Sending q to a single socket allows to reboot a single node.
Note: This command performs immediate reboot (as if the machine was powered down and immediately powered back up), for normal Talos reboot use talosctl reboot.
Development Cycle
Fast development cycle:
bring up a cluster
make code changes
rebuild initramfs with make initramfs
reboot a node to pick new initramfs
verify code changes
more code changes…
Some aspects of Talos development require to enable bootloader (when working on installer itself), in that case quick development cycle is no longer possible, and cluster should be destroyed and recreated each time.
Running Integration Tests
If integration tests were changed (or when running them for the first time), first rebuild the integration test binary:
rm -f _out/integration-test-linux-amd64; make _out/integration-test-linux-amd64
Running short tests against QEMU provisioned cluster:
This command stops QEMU and helper processes, tears down bridged network on the host, and cleans up
cluster state in ~/.talos/clusters.
Note: if the host machine is rebooted, QEMU instances and helpers processes won’t be started back.
In that case it’s required to clean up files in ~/.talos/clusters/<cluster-name> directory manually.
Optional
Set up cross-build environment with:
docker run --rm --privileged multiarch/qemu-user-static --reset -p yes
Note: the static qemu binaries which come with Ubuntu 21.10 seem to be broken.
Unit tests
Unit tests can be run in buildx with make unit-tests, on Ubuntu systems some tests using loop devices will fail because Ubuntu uses low-index loop devices for snaps.
Most of the unit-tests can be run standalone as well, with regular go test, or using IDE integration:
go test -v ./internal/pkg/circular/
This provides much faster feedback loop, but some tests require either elevated privileges (running as root) or additional binaries available only in Talos rootfs (containerd tests).
Running tests as root can be done with -exec flag to go test, but this is risky, as test code has root access and can potentially make undesired changes:
go test -exec sudo -v ./internal/app/machined/pkg/controllers/network/...
Go Profiling
Build initramfs with debug enabled: make initramfs WITH_DEBUG=1.
Launch Talos cluster with bootloader disabled, and use go tool pprof to capture the profile and show the output in your browser:
go tool pprof http://172.20.0.2:9982/debug/pprof/heap
The IP address 172.20.0.2 is the address of the Talos node, and port :9982 depends on the Go application to profile:
9981: apid
9982: machined
9983: trustd
Testing Air-gapped Environments
There is a hidden talosctl debug air-gapped command which launches two components:
HTTP proxy capable of proxying HTTP and HTTPS requests
HTTPS server with a self-signed certificate
The command also writes down Talos machine configuration patch to enable the HTTP proxy and add a self-signed certificate
to the list of trusted certificates:
$ talosctl debug air-gapped --advertised-address 172.20.0.1
2022/08/04 16:43:14 writing config patch to air-gapped-patch.yaml
2022/08/04 16:43:14 starting HTTP proxy on :8002
2022/08/04 16:43:14 starting HTTPS server with self-signed cert on :8001
The --advertised-address should match the bridge IP of the Talos node.
The first section appends a self-signed certificate of the HTTPS server to the list of trusted certificates,
followed by the HTTP proxy setup (in-cluster traffic is excluded from the proxy).
The last section adds an extra Kubernetes manifest hosted on the HTTPS server.
The machine configuration patch can now be used to launch a test Talos cluster:
The following lines should appear in the output of the talosctl debug air-gapped command:
CONNECT discovery.talos.dev:443: the HTTP proxy is used to talk to the discovery service
http: TLS handshake error from 172.20.0.2:53512: remote error: tls: bad certificate: an expected error on Talos side, as self-signed cert is not written yet to the file
GET /debug.yaml: Talos successfully fetches the extra manifest successfully
There might be more output depending on the registry caches being used or not.
4.7 - Disaster Recovery
Procedure for snapshotting etcd database and recovering from catastrophic control plane failure.
etcd database backs Kubernetes control plane state, so if the etcd service is unavailable,
the Kubernetes control plane goes down, and the cluster is not recoverable until etcd is recovered.
etcd builds around the consensus protocol Raft, so highly-available control plane clusters can tolerate the loss of nodes so long as more than half of the members are running and reachable.
For a three control plane node Talos cluster, this means that the cluster tolerates a failure of any single node,
but losing more than one node at the same time leads to complete loss of service.
Because of that, it is important to take routine backups of etcd state to have a snapshot to recover the cluster from
in case of catastrophic failure.
Backup
Snapshotting etcd Database
Create a consistent snapshot of etcd database with talosctl etcd snapshot command:
$ talosctl -n <IP> etcd snapshot db.snapshot
etcd snapshot saved to "db.snapshot"(2015264 bytes)snapshot info: hash c25fd181, revision 4193, total keys 1287, total size 3035136
Note: filename db.snapshot is arbitrary.
This database snapshot can be taken on any healthy control plane node (with IP address <IP> in the example above),
as all etcd instances contain exactly same data.
It is recommended to configure etcd snapshots to be created on some schedule to allow point-in-time recovery using the latest snapshot.
Disaster Database Snapshot
If the etcd cluster is not healthy (for example, if quorum has already been lost), the talosctl etcd snapshot command might fail.
In that case, copy the database snapshot directly from the control plane node:
This snapshot might not be fully consistent (if the etcd process is running), but it allows
for disaster recovery when latest regular snapshot is not available.
Machine Configuration
Machine configuration might be required to recover the node after hardware failure.
Backup Talos node machine configuration with the command:
talosctl -n IP get mc v1alpha1 -o yaml | yq eval'.spec' -
Recovery
Before starting a disaster recovery procedure, make sure that etcd cluster can’t be recovered:
get etcd cluster member list on all healthy control plane nodes with talosctl -n IP etcd members command and compare across all members.
query etcd health across control plane nodes with talosctl -n IP service etcd.
If the quorum can be restored, restoring quorum might be a better strategy than performing full disaster recovery
procedure.
Latest Etcd Snapshot
Get hold of the latest etcd database snapshot.
If a snapshot is not fresh enough, create a database snapshot (see above), even if the etcd cluster is unhealthy.
Init Node
Make sure that there are no control plane nodes with machine type init:
$ talosctl -n <IP1>,<IP2>,... get machinetype
NODE NAMESPACE TYPE ID VERSION TYPE
172.20.0.2 config MachineType machine-type 2 controlplane
172.20.0.4 config MachineType machine-type 2 controlplane
172.20.0.3 config MachineType machine-type 2 controlplane
Init node type is deprecated, and are incompatible with etcd recovery procedure.
init node can be converted to controlplane type with talosctl edit mc --mode=staged command followed
by node reboot with talosctl reboot command.
Preparing Control Plane Nodes
If some control plane nodes experienced hardware failure, replace them with new nodes.
Use machine configuration backup to re-create the nodes with the same secret material and control plane settings
to allow workers to join the recovered control plane.
If a control plane node is up but etcd isn’t, wipe the node’s EPHEMERAL partition to remove the etcd
data directory (make sure a database snapshot is taken before doing this):
At this point, all control plane nodes should boot up, and etcd service should be in the Preparing state.
The Kubernetes control plane endpoint should be pointed to the new control plane nodes if there were
changes to the node addresses.
Recovering from the Backup
Make sure all etcd service instances are in Preparing state:
$ talosctl -n <IP> service etcd
NODE 172.20.0.2
ID etcd
STATE Preparing
HEALTH ?
EVENTS [Preparing]: Running pre state (17s ago)[Waiting]: Waiting for service "cri" to be "up", time sync (18s ago)[Waiting]: Waiting for service "cri" to be "up", service "networkd" to be "up", time sync (20s ago)
Execute the bootstrap command against any control plane node passing the path to the etcd database snapshot:
$ talosctl -n <IP> bootstrap --recover-from=./db.snapshot
recovering from snapshot "./db.snapshot": hash c25fd181, revision 4193, total keys 1287, total size 3035136
Note: if database snapshot was copied out directly from the etcd data directory using talosctl cp,
add flag --recover-skip-hash-check to skip integrity check on restore.
Talos node should print matching information in the kernel log:
recovering etcd from snapshot: hash c25fd181, revision 4193, total keys 1287, total size 3035136
{"level":"info","msg":"restoring snapshot","path":"/var/lib/etcd.snapshot","wal-dir":"/var/lib/etcd/member/wal","data-dir":"/var/lib/etcd","snap-dir":"/var/li}
{"level":"info","msg":"restored last compact revision","meta-bucket-name":"meta","meta-bucket-name-key":"finishedCompactRev","restored-compact-revision":3360}
{"level":"info","msg":"added member","cluster-id":"a3390e43eb5274e2","local-member-id":"0","added-peer-id":"eb4f6f534361855e","added-peer-peer-urls":["https:/}
{"level":"info","msg":"restored snapshot","path":"/var/lib/etcd.snapshot","wal-dir":"/var/lib/etcd/member/wal","data-dir":"/var/lib/etcd","snap-dir":"/var/lib/etcd/member/snap"}
Now etcd service should become healthy on the bootstrap node, Kubernetes control plane components
should start and control plane endpoint should become available.
Remaining control plane nodes join etcd cluster once control plane endpoint is up.
Single Control Plane Node Cluster
This guide applies to the single control plane clusters as well.
In fact, it is much more important to take regular snapshots of the etcd database in single control plane node
case, as loss of the control plane node might render the whole cluster irrecoverable without a backup.
4.8 - etcd Maintenance
Operational instructions for etcd database.
etcd database backs Kubernetes control plane state, so etcd health is critical for Kubernetes availability.
Space Quota
etcd default database space quota is set to 2 GiB by default.
If the database size exceeds the quota, etcd will stop operations until the issue is resolved.
This condition can be checked with talosctl etcd alarm list command:
$ talosctl -n <IP> etcd alarm list
NODE MEMBER ALARM
172.20.0.2 a49c021e76e707db NOSPACE
If the Kubernetes database contains lots of resources, space quota can be increased to match the actual usage.
The recommended maximum size is 8 GiB.
To increase the space quota, edit the etcd section in the machine configuration:
Once the node is rebooted with the new configuration, use talosctl etcd alarm disarm to clear the NOSPACE alarm.
Defragmentation
etcd database can become fragmented over time if there are lots of writes and deletes.
Kubernetes API server performs automatic compaction of the etcd database, which marks deleted space as free and ready to be reused.
However, the space is not actually freed until the database is defragmented.
If the database is heavily fragmented (in use/db size ratio is less than 0.5), defragmentation might increase the performance.
If the database runs over the space quota (see above), but the actual in use database size is small, defragmentation is required to bring the on-disk database size below the limit.
Current database size can be checked with talosctl etcd status command:
$ talosctl -n <CP1>,<CP2>,<CP3> etcd status
NODE MEMBER DB SIZE IN USE LEADER RAFT INDEX RAFT TERM RAFT APPLIED INDEX LEARNER ERRORS
172.20.0.3 ecebb05b59a776f1 21 MB 6.0 MB (29.08%) ecebb05b59a776f1 53391453391false172.20.0.2 a49c021e76e707db 17 MB 4.5 MB (26.10%) ecebb05b59a776f1 53391453391false172.20.0.4 eb47fb33e59bf0e2 20 MB 5.9 MB (28.96%) ecebb05b59a776f1 53391453391false
If any of the nodes are over database size quota, alarms will be printed in the ERRORS column.
To defragment the database, run talosctl etcd defrag command:
talosctl -n <CP1> etcd defrag
Note: defragmentation is a resource-intensive operation, so it is recommended to run it on a single node at a time.
Defragmentation to a live member blocks the system from reading and writing data while rebuilding its state.
Once the defragmentation is complete, the database size will match closely to the in use size:
$ talosctl -n <CP1> etcd status
NODE MEMBER DB SIZE IN USE LEADER RAFT INDEX RAFT TERM RAFT APPLIED INDEX LEARNER ERRORS
172.20.0.2 a49c021e76e707db 4.5 MB 4.5 MB (100.00%) ecebb05b59a776f1 56065456065false
Snapshotting
Regular backups of etcd database should be performed to ensure that the cluster can be restored in case of a failure.
This procedure is described in the disaster recovery guide.
4.9 - Extension Services
Use extension services in Talos Linux.
Talos provides a way to run additional system services early in the Talos boot process.
Extension services should be included into the Talos root filesystem (e.g. using system extensions).
Extension services run as privileged containers with ephemeral root filesystem located in the Talos root filesystem.
Extension services can be used to use extend core features of Talos in a way that is not possible via static pods or
Kubernetes DaemonSets.
Potential extension services use-cases:
storage: Open iSCSI, software RAID, etc.
networking: BGP FRR, etc.
platform integration: VMWare open VM tools, etc.
Configuration
Talos on boot scans directory /usr/local/etc/containers for *.yaml files describing the extension services to run.
Format of the extension service config:
Field name sets the service name, valid names are [a-z0-9-_]+.
The service container root filesystem path is derived from the name: /usr/local/lib/containers/<name>.
The extension service will be registered as a Talos service under an ext-<name> identifier.
container
entrypoint defines the container entrypoint relative to the container root filesystem (/usr/local/lib/containers/<name>)
environment defines the container environment variables
args defines the additional arguments to pass to the entrypoint
mounts defines the volumes to be mounted into the container root
All requested directories will be mounted into the extension service container mount namespace.
If the source directory doesn’t exist in the host filesystem, it will be created (only for writable paths in the Talos root filesystem).
Talos starts the container for the extension service with container root filesystem at /usr/local/lib/containers/hello-world:
/
├── hello
└── config.ini
Extension service is registered as ext-hello-world in talosctl services:
$ talosctl service ext-hello-world
NODE 172.20.0.5
ID ext-hello-world
STATE Running
HEALTH ?
EVENTS [Running]: Started task ext-hello-world (PID 1100)for container ext-hello-world (2m47s ago)[Preparing]: Creating service runner (2m47s ago)[Preparing]: Running pre state (2m47s ago)[Waiting]: Waiting for service "containerd" to be "up"(2m48s ago)[Waiting]: Waiting for service "containerd" to be "up", network (2m49s ago)
An extension service can be started, restarted and stopped using talosctl service ext-hello-world start|restart|stop.
Use talosctl logs ext-hello-world to get the logs of the service.
Complete example of the extension service can be found in the extensions repository.
4.10 - Metal Network Configuration
How to use META-based network configuration on Talos metal platform.
Note: This is an advanced feature which requires deep understanding of Talos and Linux network configuration.
Talos Linux when running on a cloud platform (e.g. AWS or Azure), uses the platform-provided metadata server to provide initial network configuration to the node.
When running on bare-metal, there is no metadata server, so there are several options to provide initial network configuration (before machine configuration is acquired):
use automatic network configuration via DHCP (Talos default)
use automatic network configuration via DHCP just enough to fetch machine configuration and then use machine configuration to set desired advanced configuration.
If DHCP option is available, it is by far the easiest way to configure networking.
The initial boot kernel command line parameters are not very flexible, and they are not persisted after initial Talos installation.
Talos starting with version 1.4.0 offers a new option to configure networking on bare-metal: META-based network configuration.
Note: META-based network configuration is only available on Talos Linux metal platform.
Talos dashboard provides a way to configure META-based network configuration for a machine using the console, but
it doesn’t support all kinds of network configuration.
Network Configuration Format
Talos META-based network configuration is a YAML file with the following format:
Every section is optional, so you can configure only the parts you need.
The format of each section matches the respective network *Spec resource.spec part, e.g the addresses:
section matches the .spec of AddressSpec resource:
So one way to prepare the network configuration file is to boot Talos Linux, apply necessary network configuration using Talos machine configuration, and grab the resulting
resources from the running Talos instance.
In this guide we will briefly cover the most common examples of the network configuration.
Addresses
The addresses configured are usually routable IP addresses assigned to the machine, so
the scope: should be set to global and flags: to permanent.
Additionally, family: should be set to either inet4 or init6 depending on the address family.
The linkName: property should match the name of the link the address is assigned to, it might be a physical link,
e.g. en9sp0, or the name of a logical link, e.g. bond0, created in the links: section.
If the timeServers: is not set, Talos will use default NTP servers.
Supplying META Network Configuration
Once the network configuration YAML document is ready, it can be supplied to Talos in one of the following ways:
for a running Talos machine, using Talos API (requires already established network connectivity)
for Talos disk images, it can be embedded into the image
for ISO/PXE boot methods, it can be supplied via kernel command line parameters as an environment variable
The metal network configuration is stored in Talos META partition under the key 0xa (decimal 10).
In this guide we will assume that the prepared network configuration is stored in the file network.yaml.
Note: as JSON is a subset of YAML, the network configuration can be also supplied as a JSON document.
Supplying Network Configuration to a Running Talos Machine
Use the talosctl to write a network configuration to a running Talos machine:
talosctl meta write 0xa "$(cat network.yaml)"
Supplying Network Configuration to a Talos Disk Image
Create a disk image passing the network configuration as a --meta flag:
docker run --rm -t -v $PWD/_out:/out -v /dev:/dev --privileged ghcr.io/siderolabs/imager:v1.4.8 metal --meta "0xa=$(cat network.yaml)"
Supplying Network Configuration to a Talos ISO/PXE Boot
As there is no META partition created yet before Talos Linux is installed, META values can be set as an environment variable INSTALLER_META_BASE64 passed to the initial boot of Talos.
The supplied value will be used immediately, and also it will be written to the META partition once Talos is installed.
When using imager to create the ISO, the INSTALLER_META_BASE64 environment variable will be automatically generated from the --meta flag:
$ docker run --rm -t -v $PWD/_out:/out ghcr.io/siderolabs/imager:v1.4.8 iso --meta "0xa=$(cat network.yaml)"...
kernel command line: ... talos.environment=INSTALLER_META_BASE64=MHhhPWZvbw==
When PXE booting, the value of INSTALLER_META_BASE64 should be set manually:
echo -n "0xa=$(cat network.yaml)" | base64
The resulting base64 string should be passed as an environment variable INSTALLER_META_BASE64 to the initial boot of Talos: talos.environment=INSTALLER_META_BASE64=<base64-encoded value>.
Getting Current META Network Configuration
Talos exports META keys as resources:
# talosctl get meta 0x0a -o yaml...
spec:
value: '{"addresses": ...}'
4.11 - Migrating from Kubeadm
Migrating Kubeadm-based clusters to Talos.
It is possible to migrate Talos from a cluster that is created using
kubeadm to Talos.
High-level steps are the following:
Collect CA certificates and a bootstrap token from a control plane node.
Create a Talos machine config with the CA certificates with the ones you collected.
Update control plane endpoint in the machine config to point to the existing control plane (i.e. your load balancer address).
Boot a new Talos machine and apply the machine config.
Verify that the new control plane node is ready.
Remove one of the old control plane nodes.
Repeat the same steps for all control plane nodes.
Verify that all control plane nodes are ready.
Repeat the same steps for all worker nodes, using the machine config generated for the workers.
Remarks on kube-apiserver load balancer
While migrating to Talos, you need to make sure that your kube-apiserver load balancer is in place
and keeps pointing to the correct set of control plane nodes.
This process depends on your load balancer setup.
If you are using an LB that is external to the control plane nodes (e.g. cloud provider LB, F5 BIG-IP, etc.),
you need to make sure that you update the backend IPs of the load balancer to point to the control plane nodes as
you add Talos nodes and remove kubeadm-based ones.
If your load balancing is done on the control plane nodes (e.g. keepalived + haproxy on the control plane nodes),
you can do the following:
Add Talos nodes and remove kubeadm-based ones while updating the haproxy backends
to point to the newly added nodes except the last kubeadm-based control plane node.
Turn off keepalived to drop the virtual IP used by the kubeadm-based nodes (introduces kube-apiserver downtime).
Set up a virtual-IP based new load balancer on the new set of Talos control plane nodes.
Use the previous LB IP as the LB virtual IP.
Verify apiserver connectivity over the Talos-managed virtual IP.
Migrate the last control-plane node.
Prerequisites
Admin access to the kubeadm-based cluster
Access to the /etc/kubernetes/pki directory (e.g. SSH & root permissions)
on the control plane nodes of the kubeadm-based cluster
Access to kube-apiserver load-balancer configuration
Step-by-step guide
Download /etc/kubernetes/pki directory from a control plane node of the kubeadm-based cluster.
Create a new join token for the new control plane nodes:
# inside a control plane nodekubeadm token create
Create Talos secrets from the PKI directory you downloaded on step 1 and the token you generated on step 2:
talosctl gen secrets --kubernetes-bootstrap-token <TOKEN> --from-kubernetes-pki <PKI_DIR>
Create a new Talos config from the secrets:
talosctl gen config --with-secrets secrets.yaml <CLUSTER_NAME> https://<EXISTING_CLUSTER_LB_IP>
Collect the information about the kubeadm-based cluster from the kubeadm configmap:
kubectl get configmap -n kube-system kubeadm-config -oyaml
Take note of the following information in the ClusterConfiguration:
.controlPlaneEndpoint
.networking.dnsDomain
.networking.podSubnet
.networking.serviceSubnet
Replace the following information in the generated controlplane.yaml:
.cluster.network.cni.name with none
.cluster.network.podSubnets[0] with the value of the networking.podSubnet from the previous step
.cluster.network.serviceSubnets[0] with the value of the networking.serviceSubnet from the previous step
.cluster.network.dnsDomain with the value of the networking.dnsDomain from the previous step
Go through the rest of controlplane.yaml and worker.yaml to customize them according to your needs.
Bring up a Talos node to be the initial Talos control plane node.
Apply the generated controlplane.yaml to the Talos control plane node:
Clone the Linux kernel and check out the revision that pkgs uses (this can be found in kernel/kernel-prepare/pkg.yaml and it will be something like the following: https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-x.xx.x.tar.xz)
git clone https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git &&cd linux
git checkout v5.15
Your module will need to be converted to be in-tree.
The steps for this are different depending on the complexity of the module to port, but generally it would involve moving the module source code into the drivers tree and creating a new Makefile and Kconfig.
Stage your changes in Git with git add -A.
Run git diff --cached --no-prefix > foobar.patch to generate a patch from your changes.
Copy this patch to kernel/kernel/patches in the pkgs repo.
Add a patch line in the prepare segment of kernel/kernel/pkg.yaml:
patch -p0 < /pkg/patches/foobar.patch
Build the kernel image.
Make sure you are logged in to ghcr.io before running this command, and you can change or omit PLATFORM depending on what you want to target.
make kernel PLATFORM=linux/amd64 USERNAME=your-username PUSH=true
Make a note of the image name the make command outputs.
Building the installer image
Copy the following into a new Dockerfile:
FROM scratch AS customizationCOPY --from=ghcr.io/your-username/kernel:<kernel version> /lib/modules /lib/modules
FROM ghcr.io/siderolabs/installer:<talos version>COPY --from=ghcr.io/your-username/kernel:<kernel version> /boot/vmlinuz /usr/install/${TARGETARCH}/vmlinuz
Using Talos Linux to set up static pods in Kubernetes.
Static Pods
Static pods are run directly by the kubelet bypassing the Kubernetes API server checks and validations.
Most of the time DaemonSet is a better alternative to static pods, but some workloads need to run
before the Kubernetes API server is available or might need to bypass security restrictions imposed by the API server.
Talos renders static pod definitions to the kubelet manifest directory (/etc/kubernetes/manifests), kubelet picks up the definition and launches the pod.
Talos accepts changes to the static pod configuration without a reboot.
Usage
Kubelet mirrors pod definition to the API server state, so static pods can be inspected with kubectl get pods, logs can be retrieved with kubectl logs, etc.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-talos-default-controlplane-2 1/1 Running 0 17s
If the API server is not available, status of the static pod can also be inspected with talosctl containers --kubernetes:
Logs of static pods can be retrieved with talosctl logs --kubernetes:
$ talosctl logs --kubernetes default/nginx-talos-default-controlplane-2:nginx:4183a7d7a771
172.20.0.3: 2022-02-10T15:26:01.289208227Z stderr F 2022/02/10 15:26:01 [notice] 1#1: using the "epoll" event method
172.20.0.3: 2022-02-10T15:26:01.2892466Z stderr F 2022/02/10 15:26:01 [notice] 1#1: nginx/1.21.6
172.20.0.3: 2022-02-10T15:26:01.28925723Z stderr F 2022/02/10 15:26:01 [notice] 1#1: built by gcc 10.2.1 20210110(Debian 10.2.1-6)
Troubleshooting
Talos doesn’t perform any validation on the static pod definitions.
If the pod isn’t running, use kubelet logs (talosctl logs kubelet) to find the problem:
$ talosctl logs kubelet
172.20.0.2: {"ts":1644505520281.427,"caller":"config/file.go:187","msg":"Could not process manifest file","path":"/etc/kubernetes/manifests/talos-default-nginx-gvisor.yaml","err":"invalid pod: [spec.containers: Required value]"}
Resource Definitions
Static pod definitions are available as StaticPod resources combined with Talos-generated control plane static pods:
$ talosctl get staticpods
NODE NAMESPACE TYPE ID VERSION
172.20.0.3 k8s StaticPod default-nginx 1172.20.0.3 k8s StaticPod kube-apiserver 1172.20.0.3 k8s StaticPod kube-controller-manager 1172.20.0.3 k8s StaticPod kube-scheduler 1
Talos assigns ID <namespace>-<name> to the static pods specified in the machine configuration.
On control plane nodes status of the running static pods is available in the StaticPodStatus resource:
$ talosctl get staticpodstatus
NODE NAMESPACE TYPE ID VERSION READY
172.20.0.3 k8s StaticPodStatus default/nginx-talos-default-controlplane-2 2 True
172.20.0.3 k8s StaticPodStatus kube-system/kube-apiserver-talos-default-controlplane-2 2 True
172.20.0.3 k8s StaticPodStatus kube-system/kube-controller-manager-talos-default-controlplane-2 3 True
172.20.0.3 k8s StaticPodStatus kube-system/kube-scheduler-talos-default-controlplane-2 3 True
4.14 - Talos API access from Kubernetes
How to access Talos API from within Kubernetes.
In this guide, we will enable the Talos feature to access the Talos API from within Kubernetes.
Enabling the Feature
Edit the machine configuration to enable the feature, specifying the Kubernetes namespaces from which Talos API
can be accessed and the allowed Talos API roles.
talosctl -n 172.20.0.2 edit machineconfig
Configure the kubernetesTalosAPIAccess like the following:
This means that the pod can talk to Talos API of node 172.20.0.2 successfully.
4.15 - Troubleshooting Control Plane
Troubleshoot control plane failures for running cluster and bootstrap process.
In this guide we assume that Talos client config is available and Talos API access is available.
Kubernetes client configuration can be pulled from control plane nodes with talosctl -n <IP> kubeconfig
(this command works before Kubernetes is fully booted).
What is the control plane endpoint?
The Kubernetes control plane endpoint is the single canonical URL by which the
Kubernetes API is accessed.
Especially with high-availability (HA) control planes, this endpoint may point to a load balancer or a DNS name which may
have multiple A and AAAA records.
Like Talos’ own API, the Kubernetes API uses mutual TLS, client
certs, and a common Certificate Authority (CA).
Unlike general-purpose websites, there is no need for an upstream CA, so tools
such as cert-manager, Let’s Encrypt, or products such
as validated TLS certificates are not required.
Encryption, however, is, and hence the URL scheme will always be https://.
By default, the Kubernetes API server in Talos runs on port 6443.
As such, the control plane endpoint URLs for Talos will almost always be of the form
https://endpoint:6443.
(The port, since it is not the https default of 443 is required.)
The endpoint above may be a DNS name or IP address, but it should be
directed to the set of all controlplane nodes, as opposed to a
single one.
As mentioned above, this can be achieved by a number of strategies, including:
BGP peering of a shared IP (such as with kube-vip)
Using a DNS name here is a good idea, since it allows any other option, while offering
a layer of abstraction.
It allows the underlying IP addresses to change without impacting the
canonical URL.
Unlike most services in Kubernetes, the API server runs with host networking,
meaning that it shares the network namespace with the host.
This means you can use the IP address(es) of the host to refer to the Kubernetes
API server.
For availability of the API, it is important that any load balancer be aware of
the health of the backend API servers, to minimize disruptions during
common node operations like reboots and upgrades.
It is critical that the control plane endpoint works correctly during cluster bootstrap phase, as nodes discover
each other using control plane endpoint.
kubelet is not running on control plane node
The kubelet service should be running on control plane nodes as soon as networking is configured:
$ talosctl -n <IP> service kubelet
NODE 172.20.0.2
ID kubelet
STATE Running
HEALTH OK
EVENTS [Running]: Health check successful (2m54s ago)[Running]: Health check failed: Get "http://127.0.0.1:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused (3m4s ago)[Running]: Started task kubelet (PID 2334)for container kubelet (3m6s ago)[Preparing]: Creating service runner (3m6s ago)[Preparing]: Running pre state (3m15s ago)[Waiting]: Waiting for service "timed" to be "up"(3m15s ago)[Waiting]: Waiting for service "cri" to be "up", service "timed" to be "up"(3m16s ago)[Waiting]: Waiting for service "cri" to be "up", service "networkd" to be "up", service "timed" to be "up"(3m18s ago)
If the kubelet is not running, it may be due to invalid configuration.
Check kubelet logs with the talosctl logs command:
By far the most likely cause of etcd not running is because the cluster has
not yet been bootstrapped or because bootstrapping is currently in progress.
The talosctl bootstrap command must be run manually and only once per
cluster, and this step is commonly missed.
Once a node is bootstrapped, it will start etcd and, over the course of a
minute or two (depending on the download speed of the control plane nodes), the
other control plane nodes should discover it and join themselves to the cluster.
Also, etcd will only run on control plane nodes.
If a node is designated as a worker node, you should not expect etcd to be
running on it.
When node boots for the first time, the etcd data directory (/var/lib/etcd) is empty, and it will only be populated when etcd is launched.
If etcd is not running, check service etcd state:
$ talosctl -n <IP> service etcd
NODE 172.20.0.2
ID etcd
STATE Running
HEALTH OK
EVENTS [Running]: Health check successful (3m21s ago)[Running]: Started task etcd (PID 2343)for container etcd (3m26s ago)[Preparing]: Creating service runner (3m26s ago)[Preparing]: Running pre state (3m26s ago)[Waiting]: Waiting for service "cri" to be "up", service "networkd" to be "up", service "timed" to be "up"(3m26s ago)
If service is stuck in Preparing state for bootstrap node, it might be related to slow network - at this stage
Talos pulls the etcd image from the container registry.
If the etcd service is crashing and restarting, check its logs with talosctl -n <IP> logs etcd.
The most common reasons for crashes are:
wrong arguments passed via extraArgs in the configuration;
booting Talos on non-empty disk with previous Talos installation, /var/lib/etcd contains data from old cluster.
etcd is not running on non-bootstrap control plane node
The etcd service on control plane nodes which were not the target of the cluster bootstrap will wait until the bootstrapped control plane node has completed.
The bootstrap and discovery processes may take a few minutes to complete.
As soon as the bootstrapped node starts its Kubernetes control plane components, kubectl get endpoints will return the IP of bootstrapped control plane node.
At this point, the other control plane nodes will start their etcd services, join the cluster, and then start their own Kubernetes control plane components.
Kubernetes static pod definitions are not generated
Talos should generate the static pod definitions for the Kubernetes control plane
as resources:
$ talosctl -n <IP> get staticpods
NODE NAMESPACE TYPE ID VERSION
172.20.0.2 k8s StaticPod kube-apiserver 1172.20.0.2 k8s StaticPod kube-controller-manager 1172.20.0.2 k8s StaticPod kube-scheduler 1
Talos should report that the static pod definitions are rendered for the kubelet:
$ talosctl -n <IP> dmesg | grep 'rendered new'172.20.0.2: user: warning: [2023-04-26T19:17:52.550527204Z]: [talos] rendered new static pod {"component": "controller-runtime", "controller": "k8s.StaticPodServerController", "id": "kube-apiserver"}172.20.0.2: user: warning: [2023-04-26T19:17:52.552186204Z]: [talos] rendered new static pod {"component": "controller-runtime", "controller": "k8s.StaticPodServerController", "id": "kube-controller-manager"}172.20.0.2: user: warning: [2023-04-26T19:17:52.554607204Z]: [talos] rendered new static pod {"component": "controller-runtime", "controller": "k8s.StaticPodServerController", "id": "kube-scheduler"}
If the static pod definitions are not rendered, check etcd and kubelet service health (see above)
and the controller runtime logs (talosctl logs controller-runtime).
Talos prints error an error on the server ("") has prevented the request from succeeding
This is expected during initial cluster bootstrap and sometimes after a reboot:
[ 70.093289][talos] task labelNodeAsControlPlane (1/1): starting
[ 80.094038][talos] retrying error: an error on the server ("") has prevented the request from succeeding (get nodes talos-default-controlplane-1)
Initially kube-apiserver component is not running yet, and it takes some time before it becomes fully up
during bootstrap (image should be pulled from the Internet, etc.)
Once the control plane endpoint is up, Talos should continue with its boot
process.
If Talos doesn’t proceed, it may be due to a configuration issue.
In any case, the status of the control plane components on each control plane nodes can be checked with talosctl containers -k:
If kube-apiserver shows as CONTAINER_EXITED, it might have exited due to configuration error.
Logs can be checked with taloctl logs --kubernetes (or with -k as a shorthand):
$ talosctl -n <IP> logs -k kube-system/kube-apiserver-talos-default-controlplane-1:kube-apiserver:51c3aad7a271
172.20.0.2: 2021-03-05T20:46:13.133902064Z stderr F 2021/03/05 20:46:13 Running command:
172.20.0.2: 2021-03-05T20:46:13.133933824Z stderr F Command env: (log-file=, also-stdout=false, redirect-stderr=true)172.20.0.2: 2021-03-05T20:46:13.133938524Z stderr F Run from directory:
172.20.0.2: 2021-03-05T20:46:13.13394154Z stderr F Executable path: /usr/local/bin/kube-apiserver
...
Talos prints error nodes "talos-default-controlplane-1" not found
This error means that kube-apiserver is up and the control plane endpoint is healthy, but the kubelet hasn’t received
its client certificate yet, and it wasn’t able to register itself to Kubernetes.
The Kubernetes controller manager (kube-controller-manager)is responsible for monitoring the certificate
signing requests (CSRs) and issuing certificates for each of them.
The kubelet is responsible for generating and submitting the CSRs for its
associated node.
For the kubelet to get its client certificate, then, the Kubernetes control plane
must be healthy:
the API server is running and available at the Kubernetes control plane
endpoint URL
the controller manager is running and a leader has been elected
The states of any CSRs can be checked with kubectl get csr:
$ kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-jcn9j 14m kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:q9pyzr Approved,Issued
csr-p6b9q 14m kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:q9pyzr Approved,Issued
csr-sw6rm 14m kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:q9pyzr Approved,Issued
csr-vlghg 14m kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:q9pyzr Approved,Issued
Talos prints error node not ready
A Node in Kubernetes is marked as Ready only once its CNI is up.
It takes a minute or two for the CNI images to be pulled and for the CNI to start.
If the node is stuck in this state for too long, check CNI pods and logs with kubectl.
Usually, CNI-related resources are created in kube-system namespace.
For example, for Talos default Flannel CNI:
$ kubectl -n kube-system get pods
NAME READY STATUS RESTARTS AGE
...
kube-flannel-25drx 1/1 Running 0 23m
kube-flannel-8lmb6 1/1 Running 0 23m
kube-flannel-gl7nx 1/1 Running 0 23m
kube-flannel-jknt9 1/1 Running 0 23m
...
Talos prints error x509: certificate signed by unknown authority
The full error might look like:
x509: certificate signed by unknown authority (possiby because of crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes"
Usually, this occurs because the control plane endpoint points to a different
cluster than the client certificate was generated for.
If a node was recycled between clusters, make sure it was properly wiped between
uses.
If a client has multiple client configurations, make sure you are matching the correct talosconfig with the
correct cluster.
etcd is running on bootstrap node, but stuck in pre state on non-bootstrap nodes
Please see question etcd is not running on non-bootstrap control plane node.
Checking kube-controller-manager and kube-scheduler
If the control plane endpoint is up, the status of the pods can be ascertained with kubectl:
$ kubectl get pods -n kube-system -l k8s-app=kube-controller-manager
NAME READY STATUS RESTARTS AGE
kube-controller-manager-talos-default-controlplane-1 1/1 Running 0 28m
kube-controller-manager-talos-default-controlplane-2 1/1 Running 0 28m
kube-controller-manager-talos-default-controlplane-3 1/1 Running 0 28m
If the control plane endpoint is not yet up, the container status of the control plane components can be queried with
talosctl containers --kubernetes:
If some of the containers are not running, it could be that image is still being pulled.
Otherwise the process might crashing.
The logs can be checked with talosctl logs --kubernetes <containerID>:
$ talosctl -n <IP> logs -k kube-system/kube-controller-manager-talos-default-controlplane-1:kube-controller-manager:84fc77c59e17
172.20.0.3: 2021-03-09T13:59:34.291667526Z stderr F 2021/03/09 13:59:34 Running command:
172.20.0.3: 2021-03-09T13:59:34.291702262Z stderr F Command env: (log-file=, also-stdout=false, redirect-stderr=true)172.20.0.3: 2021-03-09T13:59:34.291707121Z stderr F Run from directory:
172.20.0.3: 2021-03-09T13:59:34.291710908Z stderr F Executable path: /usr/local/bin/kube-controller-manager
172.20.0.3: 2021-03-09T13:59:34.291719163Z stderr F Args (comma-delimited): /usr/local/bin/kube-controller-manager,--allocate-node-cidrs=true,--cloud-provider=,--cluster-cidr=10.244.0.0/16,--service-cluster-ip-range=10.96.0.0/12,--cluster-signing-cert-file=/system/secrets/kubernetes/kube-controller-manager/ca.crt,--cluster-signing-key-file=/system/secrets/kubernetes/kube-controller-manager/ca.key,--configure-cloud-routes=false,--kubeconfig=/system/secrets/kubernetes/kube-controller-manager/kubeconfig,--leader-elect=true,--root-ca-file=/system/secrets/kubernetes/kube-controller-manager/ca.crt,--service-account-private-key-file=/system/secrets/kubernetes/kube-controller-manager/service-account.key,--profiling=false172.20.0.3: 2021-03-09T13:59:34.293870359Z stderr F 2021/03/09 13:59:34 Now listening for interrupts
172.20.0.3: 2021-03-09T13:59:34.761113762Z stdout F I0309 13:59:34.760982 10 serving.go:331] Generated self-signed cert in-memory
...
Checking controller runtime logs
Talos runs a set of controllers which operate on resources to build and support the Kubernetes control plane.
Some debugging information can be queried from the controller logs with talosctl logs controller-runtime:
Controllers continuously run a reconcile loop, so at any time, they may be starting, failing, or restarting.
This is expected behavior.
Things to look for:
k8s.KubeletStaticPodController: rendered new static pod: static pod definitions were rendered successfully.
k8s.ManifestApplyController: controller failed: error creating mapping for object /v1/Secret/bootstrap-token-q9pyzr: an error on the server ("") has prevented the request from succeeding: control plane endpoint is not up yet, bootstrap manifests can’t be injected, controller is going to retry.
k8s.KubeletStaticPodController: controller failed: error refreshing pod status: error fetching pod status: an error on the server ("Authorization error (user=apiserver-kubelet-client, verb=get, resource=nodes, subresource=proxy)") has prevented the request from succeeding: kubelet hasn’t been able to contact kube-apiserver yet to push pod status, controller
is going to retry.
k8s.ManifestApplyController: created rbac.authorization.k8s.io/v1/ClusterRole/psp:privileged: one of the bootstrap manifests got successfully applied.
secrets.KubernetesController: controller failed: missing cluster.aggregatorCA secret: Talos is running with 0.8 configuration, if the cluster was upgraded from 0.8, this is expected, and conversion process will fix machine config
automatically.
If this cluster was bootstrapped with version 0.9, machine configuration should be regenerated with 0.9 talosctl.
If there are no new messages in the controller-runtime log, it means that the controllers have successfully finished reconciling, and that the current system state is the desired system state.
Checking static pod definitions
Talos generates static pod definitions for the kube-apiserver, kube-controller-manager, and kube-scheduler
components based on its machine configuration.
These definitions can be checked as resources with talosctl get staticpods:
The status of the static pods can queried with talosctl get staticpodstatus:
$ talosctl -n <IP> get staticpodstatus
NODE NAMESPACE TYPE ID VERSION READY
172.20.0.2 controlplane StaticPodStatus kube-system/kube-apiserver-talos-default-controlplane-1 1 True
172.20.0.2 controlplane StaticPodStatus kube-system/kube-controller-manager-talos-default-controlplane-1 1 True
172.20.0.2 controlplane StaticPodStatus kube-system/kube-scheduler-talos-default-controlplane-1 1 True
The most important status field is READY, which is the last column printed.
The complete status can be fetched by adding -o yaml flag.
Checking bootstrap manifests
As part of the bootstrap process, Talos injects bootstrap manifests into Kubernetes API server.
There are two kinds of these manifests: system manifests built-in into Talos and extra manifests downloaded (custom CNI, extra manifests in the machine config):
Worker node is stuck with apid health check failures
Control plane nodes have enough secret material to generate apid server certificates, but worker nodes
depend on control plane trustd services to generate certificates.
Worker nodes wait for their kubelet to join the cluster.
Then the Talos apid queries the Kubernetes endpoints via control plane
endpoint to find trustd endpoints.
They then use trustd to request and receive their certificate.
So if apid health checks are failing on worker node:
make sure control plane endpoint is healthy
check that worker node kubelet joined the cluster
4.16 - Verifying Images
Verifying Talos container image signatures.
Sidero Labs signs the container images generated for the Talos release with cosign:
ghcr.io/siderolabs/installer (Talos installer)
ghcr.io/siderolabs/talos (Talos image for container runtime)
ghcr.io/siderolabs/talosctl (talosctl client packaged as a container image)
The cosign tool can be used to verify the signatures of the Talos container images:
$ cosign verify --certificate-identity-regexp '@siderolabs\.com$' --certificate-oidc-issuer https://accounts.google.com ghcr.io/siderolabs/installer:v1.4.0
Verification for ghcr.io/siderolabs/installer:v1.4.0 --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- Existence of the claims in the transparency log was verified offline
- The code-signing certificate was verified using trusted certificate authority certificates
[{"critical":{"identity":{"docker-reference":"ghcr.io/siderolabs/installer"},"image":{"docker-manifest-digest":"sha256:f41795cc88f40eb1bc6b3c638c4a3123f6ef3c90627bfc35c04ebab82581e3ee"},"type":"cosign container image signature"},"optional":{"1.3.6.1.4.1.57264.1.1":"https://accounts.google.com","Bundle":{"SignedEntryTimestamp":"MEQCIERkQpgEnPWnfjUHIWO9QxC9Ute3/xJOc7TO5GUnu59xAiBKcFvrDWHoUYChT0/+gaazTrI+r0/GWSbi+Q+sEQ5AKA==","Payload":{"body":"eyJhcGlWZXJzaW9uIjoiMC4wLjEiLCJraW5kIjoiaGFzaGVkcmVrb3JkIiwic3BlYyI6eyJkYXRhIjp7Imhhc2giOnsiYWxnb3JpdGhtIjoic2hhMjU2IiwidmFsdWUiOiJkYjhjYWUyMDZmODE5MDlmZmI4NjE4ZjRkNjIzM2ZlYmM3NzY5MzliOGUxZmZkMTM1ODA4ZmZjNDgwNjYwNGExIn19LCJzaWduYXR1cmUiOnsiY29udGVudCI6Ik1FVUNJUURQWXhiVG5vSDhJTzBEakRGRE9rNU1HUjRjMXpWMys3YWFjczNHZ2J0TG1RSWdHczN4dVByWUgwQTAvM1BSZmZydDRYNS9nOUtzQVdwdG9JbE9wSDF0NllrPSIsInB1YmxpY0tleSI6eyJjb250ZW50IjoiTFMwdExTMUNSVWRKVGlCRFJWSlVTVVpKUTBGVVJTMHRMUzB0Q2sxSlNVTXhha05EUVd4NVowRjNTVUpCWjBsVlNIbEhaRTFQVEhkV09WbFFSbkJYUVRKb01qSjRVM1ZIZVZGM2QwTm5XVWxMYjFwSmVtb3dSVUYzVFhjS1RucEZWazFDVFVkQk1WVkZRMmhOVFdNeWJHNWpNMUoyWTIxVmRWcEhWakpOVWpSM1NFRlpSRlpSVVVSRmVGWjZZVmRrZW1SSE9YbGFVekZ3WW01U2JBcGpiVEZzV2tkc2FHUkhWWGRJYUdOT1RXcE5kMDVFUlRSTlZHZDZUbXBWTlZkb1kwNU5hazEzVGtSRk5FMVVaekJPYWxVMVYycEJRVTFHYTNkRmQxbElDa3R2V2tsNmFqQkRRVkZaU1V0dldrbDZhakJFUVZGalJGRm5RVVZaUVdKaVkwbDZUVzR3ZERBdlVEZHVUa0pNU0VscU1rbHlORTFQZGpoVVRrVjZUemNLUkVadVRXSldVbGc0TVdWdmExQnVZblJHTVZGMmRWQndTVm95VkV3NFFUUkdSMWw0YldFeGJFTk1kMkk0VEZOVWMzRlBRMEZZYzNkblowWXpUVUUwUndwQk1WVmtSSGRGUWk5M1VVVkJkMGxJWjBSQlZFSm5UbFpJVTFWRlJFUkJTMEpuWjNKQ1owVkdRbEZqUkVGNlFXUkNaMDVXU0ZFMFJVWm5VVlZqYWsweUNrbGpVa1lyTkhOVmRuRk5ia3hsU0ZGMVJIRkdRakZqZDBoM1dVUldVakJxUWtKbmQwWnZRVlV6T1ZCd2VqRlphMFZhWWpWeFRtcHdTMFpYYVhocE5Ga0tXa1E0ZDB0M1dVUldVakJTUVZGSUwwSkRSWGRJTkVWa1dWYzFhMk50VmpWTWJrNTBZVmhLZFdJeldrRmpNbXhyV2xoS2RtSkhSbWxqZVRWcVlqSXdkd3BMVVZsTFMzZFpRa0pCUjBSMmVrRkNRVkZSWW1GSVVqQmpTRTAyVEhrNWFGa3lUblprVnpVd1kzazFibUl5T1c1aVIxVjFXVEk1ZEUxRGMwZERhWE5IQ2tGUlVVSm5OemgzUVZGblJVaFJkMkpoU0ZJd1kwaE5Oa3g1T1doWk1rNTJaRmMxTUdONU5XNWlNamx1WWtkVmRWa3lPWFJOU1VkTFFtZHZja0puUlVVS1FXUmFOVUZuVVVOQ1NIZEZaV2RDTkVGSVdVRXpWREIzWVhOaVNFVlVTbXBIVWpSamJWZGpNMEZ4U2t0WWNtcGxVRXN6TDJnMGNIbG5Remh3TjI4MFFRcEJRVWRJYkdGbVp6Um5RVUZDUVUxQlVucENSa0ZwUVdKSE5tcDZiVUkyUkZCV1dUVXlWR1JhUmtzeGVUSkhZVk5wVW14c1IydHlSRlpRVXpsSmJGTktDblJSU1doQlR6WlZkbnBFYVVOYVFXOXZSU3RLZVdwaFpFdG5hV2xLT1RGS00yb3ZZek5CUTA5clJIcFhOamxaVUUxQmIwZERRM0ZIVTAwME9VSkJUVVFLUVRKblFVMUhWVU5OUVZCSlRUVjJVbVpIY0VGVWNqQTJVR1JDTURjeFpFOXlLMHhFSzFWQ04zbExUVWRMWW10a1UxTnJaMUp5U3l0bGNuZHdVREp6ZGdvd1NGRkdiM2h0WlRkM1NYaEJUM2htWkcxTWRIQnpjazFJZGs5cWFFSmFTMVoxVG14WmRXTkJaMVF4V1VWM1ZuZHNjR2QzYTFWUFdrWjRUemRrUnpONkNtVnZOWFJ3YVdoV1kyTndWMlozUFQwS0xTMHRMUzFGVGtRZ1EwVlNWRWxHU1VOQlZFVXRMUzB0TFFvPSJ9fX19","integratedTime":1681843022,"logIndex":18304044,"logID":"c0d23d6ad406973f9559f3ba2d1ca01f84147d8ffc5b8445c224f98b9591801d"}},"Issuer":"https://accounts.google.com","Subject":"andrey.smirnov@siderolabs.com"}}]
The image should be signed using cosign certificate authority flow by a Sidero Labs employee with and email from siderolabs.com domain.
Reproducible Builds
Talos builds for kernel, initramfs, talosctl, ISO image, and container images are reproducible.
So you can verify that the build is the same as the one as provided on GitHub releases page.
TypeUnknown represents undefined node type, when there is no machine configuration yet.
TYPE_INIT
1
TypeInit type designates the first control plane node to come up. You can think of it like a bootstrap node. This node will perform the initial steps to bootstrap the cluster – generation of TLS assets, starting of the control plane, etc.
TYPE_CONTROL_PLANE
2
TypeControlPlane designates the node as a control plane member. This means it will host etcd along with the Kubernetes controlplane components such as API Server, Controller Manager, Scheduler.
TYPE_WORKER
3
TypeWorker designates the node as a worker node. This means it will be an available compute node for scheduling workloads.
NethelpersADSelect
NethelpersADSelect is ADSelect.
Name
Number
Description
AD_SELECT_STABLE
0
AD_SELECT_BANDWIDTH
1
AD_SELECT_COUNT
2
NethelpersARPAllTargets
NethelpersARPAllTargets is an ARP targets mode.
Name
Number
Description
ARP_ALL_TARGETS_ANY
0
ARP_ALL_TARGETS_ALL
1
NethelpersARPValidate
NethelpersARPValidate is an ARP Validation mode.
Name
Number
Description
ARP_VALIDATE_NONE
0
ARP_VALIDATE_ACTIVE
1
ARP_VALIDATE_BACKUP
2
ARP_VALIDATE_ALL
3
NethelpersAddressFlag
NethelpersAddressFlag wraps IFF_* constants.
Name
Number
Description
NETHELPERS_ADDRESSFLAG_UNSPECIFIED
0
ADDRESS_TEMPORARY
1
ADDRESS_NO_DAD
2
ADDRESS_OPTIMISTIC
4
ADDRESS_DAD_FAILED
8
ADDRESS_HOME
16
ADDRESS_DEPRECATED
32
ADDRESS_TENTATIVE
64
ADDRESS_PERMANENT
128
ADDRESS_MANAGEMENT_TEMP
256
ADDRESS_NO_PREFIX_ROUTE
512
ADDRESS_MC_AUTO_JOIN
1024
ADDRESS_STABLE_PRIVACY
2048
NethelpersBondMode
NethelpersBondMode is a bond mode.
Name
Number
Description
BOND_MODE_ROUNDROBIN
0
BOND_MODE_ACTIVE_BACKUP
1
BOND_MODE_XOR
2
BOND_MODE_BROADCAST
3
BOND_MODE8023_AD
4
BOND_MODE_TLB
5
BOND_MODE_ALB
6
NethelpersBondXmitHashPolicy
NethelpersBondXmitHashPolicy is a bond hash policy.
Name
Number
Description
BOND_XMIT_POLICY_LAYER2
0
BOND_XMIT_POLICY_LAYER34
1
BOND_XMIT_POLICY_LAYER23
2
BOND_XMIT_POLICY_ENCAP23
3
BOND_XMIT_POLICY_ENCAP34
4
NethelpersDuplex
NethelpersDuplex wraps ethtool.Duplex for YAML marshaling.
Name
Number
Description
HALF
0
FULL
1
UNKNOWN
255
NethelpersFailOverMAC
NethelpersFailOverMAC is a MAC failover mode.
Name
Number
Description
FAIL_OVER_MAC_NONE
0
FAIL_OVER_MAC_ACTIVE
1
FAIL_OVER_MAC_FOLLOW
2
NethelpersFamily
NethelpersFamily is a network family.
Name
Number
Description
NETHELPERS_FAMILY_UNSPECIFIED
0
FAMILY_INET4
2
FAMILY_INET6
10
NethelpersLACPRate
NethelpersLACPRate is a LACP rate.
Name
Number
Description
LACP_RATE_SLOW
0
LACP_RATE_FAST
1
NethelpersLinkType
NethelpersLinkType is a link type.
Name
Number
Description
LINK_NETROM
0
LINK_ETHER
1
LINK_EETHER
2
LINK_AX25
3
LINK_PRONET
4
LINK_CHAOS
5
LINK_IEE802
6
LINK_ARCNET
7
LINK_ATALK
8
LINK_DLCI
15
LINK_ATM
19
LINK_METRICOM
23
LINK_IEEE1394
24
LINK_EUI64
27
LINK_INFINIBAND
32
LINK_SLIP
256
LINK_CSLIP
257
LINK_SLIP6
258
LINK_CSLIP6
259
LINK_RSRVD
260
LINK_ADAPT
264
LINK_ROSE
270
LINK_X25
271
LINK_HWX25
272
LINK_CAN
280
LINK_PPP
512
LINK_CISCO
513
LINK_HDLC
513
LINK_LAPB
516
LINK_DDCMP
517
LINK_RAWHDLC
518
LINK_TUNNEL
768
LINK_TUNNEL6
769
LINK_FRAD
770
LINK_SKIP
771
LINK_LOOPBCK
772
LINK_LOCALTLK
773
LINK_FDDI
774
LINK_BIF
775
LINK_SIT
776
LINK_IPDDP
777
LINK_IPGRE
778
LINK_PIMREG
779
LINK_HIPPI
780
LINK_ASH
781
LINK_ECONET
782
LINK_IRDA
783
LINK_FCPP
784
LINK_FCAL
785
LINK_FCPL
786
LINK_FCFABRIC
787
LINK_FCFABRIC1
788
LINK_FCFABRIC2
789
LINK_FCFABRIC3
790
LINK_FCFABRIC4
791
LINK_FCFABRIC5
792
LINK_FCFABRIC6
793
LINK_FCFABRIC7
794
LINK_FCFABRIC8
795
LINK_FCFABRIC9
796
LINK_FCFABRIC10
797
LINK_FCFABRIC11
798
LINK_FCFABRIC12
799
LINK_IEE802TR
800
LINK_IEE80211
801
LINK_IEE80211PRISM
802
LINK_IEE80211_RADIOTAP
803
LINK_IEE8021154
804
LINK_IEE8021154MONITOR
805
LINK_PHONET
820
LINK_PHONETPIPE
821
LINK_CAIF
822
LINK_IP6GRE
823
LINK_NETLINK
824
LINK6_LOWPAN
825
LINK_VOID
65535
LINK_NONE
65534
NethelpersOperationalState
NethelpersOperationalState wraps rtnetlink.OperationalState for YAML marshaling.
Name
Number
Description
OPER_STATE_UNKNOWN
0
OPER_STATE_NOT_PRESENT
1
OPER_STATE_DOWN
2
OPER_STATE_LOWER_LAYER_DOWN
3
OPER_STATE_TESTING
4
OPER_STATE_DORMANT
5
OPER_STATE_UP
6
NethelpersPort
NethelpersPort wraps ethtool.Port for YAML marshaling.
Name
Number
Description
TWISTED_PAIR
0
AUI
1
MII
2
FIBRE
3
BNC
4
DIRECT_ATTACH
5
NONE
239
OTHER
255
NethelpersPrimaryReselect
NethelpersPrimaryReselect is an ARP targets mode.
Name
Number
Description
PRIMARY_RESELECT_ALWAYS
0
PRIMARY_RESELECT_BETTER
1
PRIMARY_RESELECT_FAILURE
2
NethelpersRouteFlag
NethelpersRouteFlag wraps RTM_F_* constants.
Name
Number
Description
NETHELPERS_ROUTEFLAG_UNSPECIFIED
0
ROUTE_NOTIFY
256
ROUTE_CLONED
512
ROUTE_EQUALIZE
1024
ROUTE_PREFIX
2048
ROUTE_LOOKUP_TABLE
4096
ROUTE_FIB_MATCH
8192
ROUTE_OFFLOAD
16384
ROUTE_TRAP
32768
NethelpersRouteProtocol
NethelpersRouteProtocol is a routing protocol.
Name
Number
Description
PROTOCOL_UNSPEC
0
PROTOCOL_REDIRECT
1
PROTOCOL_KERNEL
2
PROTOCOL_BOOT
3
PROTOCOL_STATIC
4
PROTOCOL_RA
9
PROTOCOL_MRT
10
PROTOCOL_ZEBRA
11
PROTOCOL_BIRD
12
PROTOCOL_DNROUTED
13
PROTOCOL_XORP
14
PROTOCOL_NTK
15
PROTOCOL_DHCP
16
PROTOCOL_MRTD
17
PROTOCOL_KEEPALIVED
18
PROTOCOL_BABEL
42
PROTOCOL_OPENR
99
PROTOCOL_BGP
186
PROTOCOL_ISIS
187
PROTOCOL_OSPF
188
PROTOCOL_RIP
189
PROTOCOL_EIGRP
192
NethelpersRouteType
NethelpersRouteType is a route type.
Name
Number
Description
TYPE_UNSPEC
0
TYPE_UNICAST
1
TYPE_LOCAL
2
TYPE_BROADCAST
3
TYPE_ANYCAST
4
TYPE_MULTICAST
5
TYPE_BLACKHOLE
6
TYPE_UNREACHABLE
7
TYPE_PROHIBIT
8
TYPE_THROW
9
TYPE_NAT
10
TYPE_X_RESOLVE
11
NethelpersRoutingTable
NethelpersRoutingTable is a routing table ID.
Name
Number
Description
TABLE_UNSPEC
0
TABLE_DEFAULT
253
TABLE_MAIN
254
TABLE_LOCAL
255
NethelpersScope
NethelpersScope is an address scope.
Name
Number
Description
SCOPE_GLOBAL
0
SCOPE_SITE
200
SCOPE_LINK
253
SCOPE_HOST
254
SCOPE_NOWHERE
255
NethelpersVLANProtocol
NethelpersVLANProtocol is a VLAN protocol.
Name
Number
Description
NETHELPERS_VLANPROTOCOL_UNSPECIFIED
0
VLAN_PROTOCOL8021_Q
33024
VLAN_PROTOCOL8021_AD
34984
NetworkConfigLayer
NetworkConfigLayer describes network configuration layers, with lowest priority first.
System_partitions_to_wipe lists specific system disk partitions to be reset (wiped). If system_partitions_to_wipe is empty, all the partitions are erased.
Snapshot can be later used to recover the cluster via Bootstrap method. |
| EtcdSnapshot | EtcdSnapshotRequest | .common.Data stream | EtcdSnapshot method creates etcd data snapshot (backup) from the local etcd instance and streams it back to the client.
This method is available only on control plane nodes (which run etcd). |
| EtcdAlarmList | .google.protobuf.Empty | EtcdAlarmListResponse | EtcdAlarmList lists etcd alarms for the current node.
This method is available only on control plane nodes (which run etcd). |
| EtcdAlarmDisarm | .google.protobuf.Empty | EtcdAlarmDisarmResponse | EtcdAlarmDisarm disarms etcd alarms for the current node.
This method is available only on control plane nodes (which run etcd). |
| EtcdDefragment | .google.protobuf.Empty | EtcdDefragmentResponse | EtcdDefragment defragments etcd data directory for the current node.
Defragmentation is a resource-heavy operation, so it should only run on a specific node.
This method is available only on control plane nodes (which run etcd). |
| EtcdStatus | .google.protobuf.Empty | EtcdStatusResponse | EtcdStatus returns etcd status for the current member.
--cert-fingerprint strings list of server certificate fingeprints to accept (defaults to no check)
-p, --config-patch strings the list of config patches to apply to the local config file before sending it to the node
--dry-run check how the config change will be applied in dry-run mode
-f, --file string the filename of the updated configuration
-h, --help help for apply-config
-i, --insecure apply the config using the insecure (encrypted with no auth) maintenance service
-m, --mode auto, interactive, no-reboot, reboot, staged, try apply config mode (default auto)
--timeout duration the config will be rolled back after specified timeout (if try mode is selected) (default 1m0s)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl bootstrap
Bootstrap the etcd cluster on the specified node.
Synopsis
When Talos cluster is created etcd service on control plane nodes enter the join loop waiting
to join etcd peers from other control plane nodes. One node should be picked as the boostrap node.
When boostrap command is issued, the node aborts join process and bootstraps etcd cluster as a single node cluster.
Other control plane nodes will join etcd cluster once Kubernetes is boostrapped on the bootstrap node.
This command should not be used when “init” type node are used.
Talos etcd cluster can be recovered from a known snapshot with ‘–recover-from=’ flag.
talosctl bootstrap [flags]
Options
-h, --help help for bootstrap
--recover-from string recover etcd cluster from the snapshot
--recover-skip-hash-check skip integrity check when recovering etcd (use when recovering from data directory copy)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl cluster create
Creates a local docker-based or QEMU-based kubernetes cluster
talosctl cluster create [flags]
Options
--arch string cluster architecture (default "amd64")
--bad-rtc launch VM with bad RTC state (QEMU only)
--cidr string CIDR of the cluster network (IPv4, ULA network for IPv6 is derived in automated way) (default "10.5.0.0/24")
--cni-bin-path strings search path for CNI binaries (VM only) (default [/home/user/.talos/cni/bin])
--cni-bundle-url string URL to download CNI bundle from (VM only) (default "https://github.com/siderolabs/talos/releases/download/v1.4.0-alpha.4/talosctl-cni-bundle-${ARCH}.tar.gz")
--cni-cache-dir string CNI cache directory path (VM only) (default "/home/user/.talos/cni/cache")
--cni-conf-dir string CNI config directory path (VM only) (default "/home/user/.talos/cni/conf.d")
--config-patch stringArray patch generated machineconfigs (applied to all node types), use @file to read a patch from file
--config-patch-control-plane stringArray patch generated machineconfigs (applied to 'init' and 'controlplane' types)
--config-patch-worker stringArray patch generated machineconfigs (applied to 'worker' type)
--control-plane-port int control plane port (load balancer and local API port) (default 6443)
--controlplanes int the number of controlplanes to create (default 1)
--cpus string the share of CPUs as fraction (each control plane/VM) (default "2.0")
--cpus-workers string the share of CPUs as fraction (each worker/VM) (default "2.0")
--crashdump print debug crashdump to stderr when cluster startup fails
--custom-cni-url string install custom CNI from the URL (Talos cluster)
--disable-dhcp-hostname skip announcing hostname via DHCP (QEMU only)
--disk int default limit on disk size in MB (each VM) (default 6144)
--disk-image-path string disk image to use
--dns-domain string the dns domain to use for cluster (default "cluster.local")
--docker-disable-ipv6 skip enabling IPv6 in containers (Docker only)
--docker-host-ip string Host IP to forward exposed ports to (Docker provisioner only) (default "0.0.0.0")
--encrypt-ephemeral enable ephemeral partition encryption
--encrypt-state enable state partition encryption
--endpoint string use endpoint instead of provider defaults
-p, --exposed-ports string Comma-separated list of ports/protocols to expose on init node. Ex -p <hostPort>:<containerPort>/<protocol (tcp or udp)> (Docker provisioner only)
--extra-boot-kernel-args string add extra kernel args to the initial boot from vmlinuz and initramfs (QEMU only)
--extra-disks int number of extra disks to create for each worker VM
--extra-disks-size int default limit on disk size in MB (each VM) (default 5120)
--extra-uefi-search-paths strings additional search paths for UEFI firmware (only applies when UEFI is enabled)
-h, --help help for create
--image string the image to use (default "ghcr.io/siderolabs/talos:latest")
--init-node-as-endpoint use init node as endpoint instead of any load balancer endpoint
--initrd-path string initramfs image to use (default "_out/initramfs-${ARCH}.xz")
-i, --input-dir string location of pre-generated config files
--install-image string the installer image to use (default "ghcr.io/siderolabs/installer:latest")
--ipv4 enable IPv4 network in the cluster (default true)
--ipv6 enable IPv6 network in the cluster (QEMU provisioner only)
--iso-path string the ISO path to use for the initial boot (VM only)
--kubernetes-version string desired kubernetes version to run (default "1.27.1")
--memory int the limit on memory usage in MB (each control plane/VM) (default 2048)
--memory-workers int the limit on memory usage in MB (each worker/VM) (default 2048)
--mtu int MTU of the cluster network (default 1500)
--nameservers strings list of nameservers to use (default [8.8.8.8,1.1.1.1,2001:4860:4860::8888,2606:4700:4700::1111])
--registry-insecure-skip-verify strings list of registry hostnames to skip TLS verification for
--registry-mirror strings list of registry mirrors to use in format: <registry host>=<mirror URL>
--skip-boot-phase-finished-check skip waiting for node to finish boot phase
--skip-injecting-config skip injecting config from embedded metadata server, write config files to current directory
--skip-kubeconfig skip merging kubeconfig from the created cluster
--talos-version string the desired Talos version to generate config for (if not set, defaults to image version)
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--use-vip use a virtual IP for the controlplane endpoint instead of the loadbalancer
--user-disk strings list of disks to create for each VM in format: <mount_point1>:<size1>:<mount_point2>:<size2>
--vmlinuz-path string the compressed kernel image to use (default "_out/vmlinuz-${ARCH}")
--wait wait for the cluster to be ready before returning (default true)
--wait-timeout duration timeout to wait for the cluster to be ready (default 20m0s)
--wireguard-cidr string CIDR of the wireguard network
--with-apply-config enable apply config when the VM is starting in maintenance mode
--with-bootloader enable bootloader to load kernel and initramfs from disk image after install (default true)
--with-cluster-discovery enable cluster discovery (default true)
--with-debug enable debug in Talos config to send service logs to the console
--with-init-node create the cluster with an init node
--with-kubespan enable KubeSpan system
--with-uefi enable UEFI on x86_64 architecture (default true)
--workers int the number of workers to create (default 1)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
--name string the name of the cluster (default "talos-default")
-n, --nodes strings target the specified nodes
--provisioner string Talos cluster provisioner to use (default "docker")
--state string directory path to store cluster state (default "/home/user/.talos/clusters")
SEE ALSO
talosctl cluster - A collection of commands for managing local docker-based or QEMU-based clusters
talosctl cluster destroy
Destroys a local docker-based or firecracker-based kubernetes cluster
talosctl cluster destroy [flags]
Options
-f, --force force deletion of cluster directory if there were errors
-h, --help help for destroy
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
--name string the name of the cluster (default "talos-default")
-n, --nodes strings target the specified nodes
--provisioner string Talos cluster provisioner to use (default "docker")
--state string directory path to store cluster state (default "/home/user/.talos/clusters")
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl cluster - A collection of commands for managing local docker-based or QEMU-based clusters
talosctl cluster show
Shows info about a local provisioned kubernetes cluster
talosctl cluster show [flags]
Options
-h, --help help for show
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
--name string the name of the cluster (default "talos-default")
-n, --nodes strings target the specified nodes
--provisioner string Talos cluster provisioner to use (default "docker")
--state string directory path to store cluster state (default "/home/user/.talos/clusters")
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl cluster - A collection of commands for managing local docker-based or QEMU-based clusters
talosctl cluster
A collection of commands for managing local docker-based or QEMU-based clusters
Options
-h, --help help for cluster
--name string the name of the cluster (default "talos-default")
--provisioner string Talos cluster provisioner to use (default "docker")
--state string directory path to store cluster state (default "/home/user/.talos/clusters")
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
Output shell completion code for the specified shell (bash, fish or zsh)
Synopsis
Output shell completion code for the specified shell (bash, fish or zsh).
The shell code must be evaluated to provide interactive
completion of talosctl commands. This can be done by sourcing it from
the .bash_profile.
Note for zsh users: [1] zsh completions are only supported in versions of zsh >= 5.2
talosctl completion SHELL [flags]
Examples
# Installing bash completion on macOS using homebrew
## If running Bash 3.2 included with macOS
brew install bash-completion
## or, if running Bash 4.1+
brew install bash-completion@2
## If talosctl is installed via homebrew, this should start working immediately.
## If you've installed via other means, you may need add the completion to your completion directory
talosctl completion bash > $(brew --prefix)/etc/bash_completion.d/talosctl
# Installing bash completion on Linux
## If bash-completion is not installed on Linux, please install the 'bash-completion' package
## via your distribution's package manager.
## Load the talosctl completion code for bash into the current shell
source <(talosctl completion bash)
## Write bash completion code to a file and source if from .bash_profile
talosctl completion bash > ~/.talos/completion.bash.inc
printf "
# talosctl shell completion
source '$HOME/.talos/completion.bash.inc'
" >> $HOME/.bash_profile
source $HOME/.bash_profile
# Load the talosctl completion code for fish[1] into the current shell
talosctl completion fish | source
# Set the talosctl completion code for fish[1] to autoload on startup
talosctl completion fish > ~/.config/fish/completions/talosctl.fish
# Load the talosctl completion code for zsh[1] into the current shell
source <(talosctl completion zsh)
# Set the talosctl completion code for zsh[1] to autoload on startup
talosctl completion zsh > "${fpath[1]}/_talosctl"
Options
-h, --help help for completion
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl config add
Add a new context
talosctl config add <context> [flags]
Options
--ca string the path to the CA certificate
--crt string the path to the certificate
-h, --help help for add
--key string the path to the key
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config context
Set the current context
talosctl config context <context> [flags]
Options
-h, --help help for context
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config contexts
List defined contexts
talosctl config contexts [flags]
Options
-h, --help help for contexts
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config endpoint
Set the endpoint(s) for the current context
talosctl config endpoint <endpoint>... [flags]
Options
-h, --help help for endpoint
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config info
Show information about the current context
talosctl config info [flags]
Options
-h, --help help for info
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config merge
Merge additional contexts from another client configuration file
Synopsis
Contexts with the same name are renamed while merging configs.
talosctl config merge <from> [flags]
Options
-h, --help help for merge
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config new
Generate a new client configuration file
talosctl config new [<path>] [flags]
Options
--crt-ttl duration certificate TTL (default 87600h0m0s)
-h, --help help for new
--roles strings roles (default [os:admin])
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config node
Set the node(s) for the current context
talosctl config node <endpoint>... [flags]
Options
-h, --help help for node
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config remove
Remove contexts
talosctl config remove <context> [flags]
Options
--dry-run dry run
-h, --help help for remove
-y, --noconfirm do not ask for confirmation
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl config - Manage the client configuration file (talosconfig)
talosctl config
Manage the client configuration file (talosconfig)
Options
-h, --help help for config
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
-h, --help help for kubernetes
--mode string conformance test mode: [fast, certified] (default "fast")
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
-h, --help help for containers
-k, --kubernetes use the k8s.io containerd namespace
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl copy
Copy data out from the node
Synopsis
Creates an .tar.gz archive at the node starting at and
streams it back to the client.
If ‘-’ is given for , archive is written to stdout.
Otherwise archive is extracted to which should be an empty directory or
talosctl creates a directory if doesn’t exist. Command doesn’t preserve
ownership and access mode for the files in extract mode, while streamed .tar archive
captures ownership and permission bits.
talosctl copy <src-path> -|<local-path> [flags]
Options
-h, --help help for copy
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl dashboard
Cluster dashboard with node overview, logs and real-time metrics
Synopsis
Provide a text-based UI to navigate node overview, logs and real-time metrics.
Keyboard shortcuts:
h, : switch one node to the left
l, : switch one node to the right
j, : scroll logs/process list down
k, : scroll logs/process list up
: scroll logs/process list half page down
: scroll logs/process list half page up
: scroll logs/process list one page down
: scroll logs/process list one page up
talosctl dashboard [flags]
Options
-h, --help help for dashboard
-d, --update-interval duration interval between updates (default 3s)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl disks
Get the list of disks from /sys/block on the machine
talosctl disks [flags]
Options
-h, --help help for disks
-i, --insecure get disks using the insecure (encrypted with no auth) maintenance service
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl dmesg
Retrieve kernel logs
talosctl dmesg [flags]
Options
-f, --follow specify if the kernel log should be streamed
-h, --help help for dmesg
--tail specify if only new messages should be sent (makes sense only when combined with --follow)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl edit
Edit a resource from the default editor.
Synopsis
The edit command allows you to directly edit any API resource
you can retrieve via the command line tools.
It will open the editor defined by your TALOS_EDITOR,
or EDITOR environment variables, or fall back to ‘vi’ for Linux
or ’notepad’ for Windows.
talosctl edit <type> [<id>] [flags]
Options
--dry-run do not apply the change after editing and print the change summary instead
-h, --help help for edit
-m, --mode auto, no-reboot, reboot, staged, try apply config mode (default auto)
--namespace string resource namespace (default is to use default namespace per resource)
--timeout duration the config will be rolled back after specified timeout (if try mode is selected) (default 1m0s)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl etcd alarm disarm
Disarm the etcd alarms for the node.
talosctl etcd alarm disarm [flags]
Options
-h, --help help for disarm
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
Defragmentation is a maintenance operation that releases unused space from the etcd database file.
Defragmentation is a resource heavy operation and should be performed only when necessary on a single node at a time.
talosctl etcd defrag [flags]
Options
-h, --help help for defrag
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
Use this command only if you want to remove a member which is in broken state.
If there is no access to the node, or the node can’t access etcd to call etcd leave.
Always prefer etcd leave over this command.
It’s always better to use member ID than hostname, as hostname might not be set consistently.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
Returns the status of etcd member on the node, use multiple nodes to get status of all members.
talosctl etcd status [flags]
Options
-h, --help help for status
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
--actor-id string filter events by the specified actor ID (default is no filter)
--duration duration show events for the past duration interval (one second resolution, default is to show no history)
-h, --help help for events
--since string show events after the specified event ID (default is to show no history)
--tail int32 show specified number of past events (use -1 to show full history, default is to show no history)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl gen ca
Generates a self-signed X.509 certificate authority
talosctl gen ca [flags]
Options
-h, --help help for ca
--hours int the hours from now on which the certificate validity period ends (default 87600)
--organization string X.509 distinguished name for the Organization
--rsa generate in RSA format
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-f, --force will overwrite existing files
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl gen - Generate CAs, certificates, and private keys
talosctl gen config
Generates a set of configuration files for Talos cluster
Synopsis
The cluster endpoint is the URL for the Kubernetes API. If you decide to use
a control plane node, common in a single node control plane setup, use port 6443 as
this is the port that the API server binds to on every control plane node. For an HA
setup, usually involving a load balancer, use the IP and port of the load balancer.
talosctl gen config <cluster name> <cluster endpoint> [flags]
Options
--additional-sans strings additional Subject-Alt-Names for the APIServer certificate
--config-patch stringArray patch generated machineconfigs (applied to all node types), use @file to read a patch from file
--config-patch-control-plane stringArray patch generated machineconfigs (applied to 'init' and 'controlplane' types)
--config-patch-worker stringArray patch generated machineconfigs (applied to 'worker' type)
--dns-domain string the dns domain to use for cluster (default "cluster.local")
-h, --help help for config
--install-disk string the disk to install to (default "/dev/sda")
--install-image string the image used to perform an installation (default "ghcr.io/siderolabs/installer:latest")
--kubernetes-version string desired kubernetes version to run (default "1.27.1")
-o, --output string destination to output generated files. when multiple output types are specified, it must be a directory. for a single output type, it must either be a file path, or "-" for stdout
-t, --output-types strings types of outputs to be generated. valid types are: ["controlplane" "worker" "talosconfig"] (default [controlplane,worker,talosconfig])
-p, --persist the desired persist value for configs (default true)
--registry-mirror strings list of registry mirrors to use in format: <registry host>=<mirror URL>
--talos-version string the desired Talos version to generate config for (backwards compatibility, e.g. v0.8)
--version string the desired machine config version to generate (default "v1alpha1")
--with-cluster-discovery enable cluster discovery feature (default true)
--with-docs renders all machine configs adding the documentation for each field (default true)
--with-examples renders all machine configs with the commented examples (default true)
--with-kubespan enable KubeSpan feature
--with-secrets string use a secrets file generated using 'gen secrets'
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-f, --force will overwrite existing files
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl gen - Generate CAs, certificates, and private keys
talosctl gen crt
Generates an X.509 Ed25519 certificate
talosctl gen crt [flags]
Options
--ca string path to the PEM encoded CERTIFICATE
--csr string path to the PEM encoded CERTIFICATE REQUEST
-h, --help help for crt
--hours int the hours from now on which the certificate validity period ends (default 24)
--name string the basename of the generated file
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-f, --force will overwrite existing files
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl gen - Generate CAs, certificates, and private keys
talosctl gen csr
Generates a CSR using an Ed25519 private key
talosctl gen csr [flags]
Options
-h, --help help for csr
--ip string generate the certificate for this IP address
--key string path to the PEM encoded EC or RSA PRIVATE KEY
--roles strings roles (default [os:admin])
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-f, --force will overwrite existing files
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl gen - Generate CAs, certificates, and private keys
talosctl gen key
Generates an Ed25519 private key
talosctl gen key [flags]
Options
-h, --help help for key
--name string the basename of the generated file
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-f, --force will overwrite existing files
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl gen - Generate CAs, certificates, and private keys
talosctl gen keypair
Generates an X.509 Ed25519 key pair
talosctl gen keypair [flags]
Options
-h, --help help for keypair
--ip string generate the certificate for this IP address
--organization string X.509 distinguished name for the Organization
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-f, --force will overwrite existing files
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl gen - Generate CAs, certificates, and private keys
talosctl gen secrets
Generates a secrets bundle file which can later be used to generate a config
talosctl gen secrets [flags]
Options
-p, --from-kubernetes-pki string use a Kubernetes PKI directory (e.g. /etc/kubernetes/pki) as input
-h, --help help for secrets
-t, --kubernetes-bootstrap-token string use the provided bootstrap token as input
-o, --output-file string path of the output file (default "secrets.yaml")
--talos-version string the desired Talos version to generate secrets bundle for (backwards compatibility, e.g. v0.8)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-f, --force will overwrite existing files
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl gen - Generate CAs, certificates, and private keys
talosctl gen
Generate CAs, certificates, and private keys
Options
-f, --force will overwrite existing files
-h, --help help for gen
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl gen ca - Generates a self-signed X.509 certificate authority
talosctl gen config - Generates a set of configuration files for Talos cluster
talosctl gen secrets - Generates a secrets bundle file which can later be used to generate a config
talosctl get
Get a specific resource or list of resources (use ’talosctl get rd’ to see all available resource types).
Synopsis
Similar to ‘kubectl get’, ’talosctl get’ returns a set of resources from the OS.
To get a list of all available resource definitions, issue ’talosctl get rd’
talosctl get <type> [<id>] [flags]
Options
-h, --help help for get
-i, --insecure get resources using the insecure (encrypted with no auth) maintenance service
--namespace string resource namespace (default is to use default namespace per resource)
-o, --output string output mode (json, table, yaml, jsonpath) (default "table")
-w, --watch watch resource changes
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl health
Check cluster health
talosctl health [flags]
Options
--control-plane-nodes strings specify IPs of control plane nodes
-h, --help help for health
--init-node string specify IPs of init node
--k8s-endpoint string use endpoint instead of kubeconfig default
--run-e2e run Kubernetes e2e test
--server run server-side check (default true)
--wait-timeout duration timeout to wait for the cluster to be ready (default 20m0s)
--worker-nodes strings specify IPs of worker nodes
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl images
List the default images used by Talos
talosctl images [flags]
Options
-h, --help help for images
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl inject serviceaccount
Inject Talos API ServiceAccount into Kubernetes manifests
talosctl inject serviceaccount --roles="os:admin" -f deployment.yaml > deployment-injected.yaml
Alternatively, stdin can be piped to the command:
cat deployment.yaml | talosctl inject serviceaccount --roles="os:admin" -f - > deployment-injected.yaml
Options
-f, --file string file with Kubernetes manifests to be injected with ServiceAccount
-h, --help help for serviceaccount
-r, --roles strings roles to add to the generated ServiceAccount manifests (default [os:reader])
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl inject - Inject Talos API resources into Kubernetes manifests
talosctl inject
Inject Talos API resources into Kubernetes manifests
Options
-h, --help help for inject
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
-h, --help help for dependencies
--with-resources display live resource information with dependencies
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
Download the admin kubeconfig from the node.
If merge flag is defined, config will be merged with ~/.kube/config or [local-path] if specified.
Otherwise kubeconfig will be written to PWD or [local-path] if specified.
talosctl kubeconfig [local-path] [flags]
Options
-f, --force Force overwrite of kubeconfig if already present, force overwrite on kubeconfig merge
--force-context-name string Force context name for kubeconfig merge
-h, --help help for kubeconfig
-m, --merge Merge with existing kubeconfig (default true)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl list
Retrieve a directory listing
talosctl list [path] [flags]
Options
-d, --depth int32 maximum recursion depth (default 1)
-h, --help help for list
-H, --humanize humanize size and time in the output
-l, --long display additional file details
-r, --recurse recurse into subdirectories
-t, --type strings filter by specified types:
f regular file
d directory
l, L symbolic link
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl logs
Retrieve logs for a service
talosctl logs <service name> [flags]
Options
-f, --follow specify if the logs should be streamed
-h, --help help for logs
-k, --kubernetes use the k8s.io containerd namespace
--tail int32 lines of log file to display (default is to show from the beginning) (default -1)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl machineconfig gen
Generates a set of configuration files for Talos cluster
Synopsis
The cluster endpoint is the URL for the Kubernetes API. If you decide to use
a control plane node, common in a single node control plane setup, use port 6443 as
this is the port that the API server binds to on every control plane node. For an HA
setup, usually involving a load balancer, use the IP and port of the load balancer.
talosctl machineconfig gen <cluster name> <cluster endpoint> [flags]
Options
-h, --help help for gen
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
-h, --help help for patch
-o, --output string output destination. if not specified, output will be printed to stdout
-p, --patch stringArray patch generated machineconfigs (applied to all node types), use @file to read a patch from file
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
-h, --help help for memory
-v, --verbose display extended memory statistics
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl meta delete
Delete a key from the META partition.
talosctl meta delete key [flags]
Options
-h, --help help for delete
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl meta - Write and delete keys in the META partition
talosctl meta write
Write a key-value pair to the META partition.
talosctl meta write key value [flags]
Options
-h, --help help for write
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl meta - Write and delete keys in the META partition
talosctl meta
Write and delete keys in the META partition
Options
-h, --help help for meta
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl netstat
Show network connections and sockets
Synopsis
Show network connections and sockets.
You can pass an optional argument to view a specific pod’s connections.
To do this, format the argument as “namespace/pod”.
Note that only pods with a pod network namespace are allowed.
If you don’t pass an argument, the command will show host connections.
talosctl netstat [flags]
Options
-a, --all display all sockets states (default: connected)
-x, --extend show detailed socket information
-h, --help help for netstat
-4, --ipv4 display only ipv4 sockets
-6, --ipv6 display only ipv6 sockets
-l, --listening display listening server sockets
-k, --pods show sockets used by Kubernetes pods
-p, --programs show process using socket
-w, --raw display only RAW sockets
-t, --tcp display only TCP sockets
-o, --timers display timers
-u, --udp display only UDP sockets
-U, --udplite display only UDPLite sockets
-v, --verbose display sockets of all supported transport protocols
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl patch
Update field(s) of a resource using a JSON patch.
talosctl patch <type> [<id>] [flags]
Options
--dry-run print the change summary and patch preview without applying the changes
-h, --help help for patch
-m, --mode auto, no-reboot, reboot, staged, try apply config mode (default auto)
--namespace string resource namespace (default is to use default namespace per resource)
-p, --patch stringArray the patch to be applied to the resource file, use @file to read a patch from file.
--patch-file string a file containing a patch to be applied to the resource.
--timeout duration the config will be rolled back after specified timeout (if try mode is selected) (default 1m0s)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl pcap
Capture the network packets from the node.
Synopsis
The command launches packet capture on the node and streams back the packets as raw pcap file.
Default behavior is to decode the packets with internal decoder to stdout:
talosctl pcap -i eth0
Raw pcap file can be saved with –output flag:
talosctl pcap -i eth0 –output eth0.pcap
Output can be piped to tcpdump:
talosctl pcap -i eth0 -o - | tcpdump -vvv -r -
BPF filter can be applied, but it has to compiled to BPF instructions first using tcpdump.
Correct link type should be specified for the tcpdump: EN10MB for Ethernet links and RAW
for e.g. Wireguard tunnels:
talosctl pcap -i eth0 –bpf-filter “$(tcpdump -dd -y EN10MB ’tcp and dst port 80’)”
As packet capture is transmitted over the network, it is recommended to filter out the Talos API traffic,
e.g. by excluding packets with the port 50000.
talosctl pcap [flags]
Options
--bpf-filter string bpf filter to apply, tcpdump -dd format
--duration duration duration of the capture
-h, --help help for pcap
-i, --interface string interface name to capture packets on (default "eth0")
-o, --output string if not set, decode packets to stdout; if set write raw pcap data to a file, use '-' for stdout
--promiscuous put interface into promiscuous mode
-s, --snaplen int maximum packet size to capture (default 65536)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl processes
List running processes
talosctl processes [flags]
Options
-h, --help help for processes
-s, --sort string Column to sort output by. [rss|cpu] (default "rss")
-w, --watch Stream running processes
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl read
Read a file on the machine
talosctl read <path> [flags]
Options
-h, --help help for read
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl reboot
Reboot a node
talosctl reboot [flags]
Options
--debug debug operation from kernel logs. --wait is set to true when this flag is set
-h, --help help for reboot
-m, --mode string select the reboot mode: "default", "powercycle" (skips kexec) (default "default")
--timeout duration time to wait for the operation is complete if --debug or --wait is set (default 30m0s)
--wait wait for the operation to complete, tracking its progress. always set to true when --debug is set (default true)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl reset
Reset a node
talosctl reset [flags]
Options
--debug debug operation from kernel logs. --wait is set to true when this flag is set
--graceful if true, attempt to cordon/drain node and leave etcd (if applicable) (default true)
-h, --help help for reset
--insecure reset using the insecure (encrypted with no auth) maintenance service
--reboot if true, reboot the node after resetting instead of shutting down
--system-labels-to-wipe strings if set, just wipe selected system disk partitions by label but keep other partitions intact
--timeout duration time to wait for the operation is complete if --debug or --wait is set (default 30m0s)
--user-disks-to-wipe strings if set, wipes defined devices in the list
--wait wait for the operation to complete, tracking its progress. always set to true when --debug is set (default true)
--wipe-mode all, system-disk, user-disks disk reset mode (default all)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl restart
Restart a process
talosctl restart <id> [flags]
Options
-h, --help help for restart
-k, --kubernetes use the k8s.io containerd namespace
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl rollback
Rollback a node to the previous installation
talosctl rollback [flags]
Options
-h, --help help for rollback
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl service
Retrieve the state of a service (or all services), control service state
Synopsis
Service control command. If run without arguments, lists all the services and their state.
If service ID is specified, default action ‘status’ is executed which shows status of a single list service.
With actions ‘start’, ‘stop’, ‘restart’, service state is updated respectively.
talosctl service [<id> [start|stop|restart|status]] [flags]
Options
-h, --help help for service
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl shutdown
Shutdown a node
talosctl shutdown [flags]
Options
--debug debug operation from kernel logs. --wait is set to true when this flag is set
--force if true, force a node to shutdown without a cordon/drain
-h, --help help for shutdown
--timeout duration time to wait for the operation is complete if --debug or --wait is set (default 30m0s)
--wait wait for the operation to complete, tracking its progress. always set to true when --debug is set (default true)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl stats
Get container stats
talosctl stats [flags]
Options
-h, --help help for stats
-k, --kubernetes use the k8s.io containerd namespace
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl support
Dump debug information about the cluster
Synopsis
Generated bundle contains the following debug information:
For each node:
Kernel logs.
All Talos internal services logs.
All kube-system pods logs.
Talos COSI resources without secrets.
COSI runtime state graph.
Processes snapshot.
IO pressure snapshot.
Mounts list.
PCI devices info.
Talos version.
For the cluster:
Kubernetes nodes and kube-system pods manifests.
talosctl support [flags]
Options
-h, --help help for support
-w, --num-workers int number of workers per node (default 1)
-O, --output string output file to write support archive to
-v, --verbose verbose output
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl time
Gets current server time
talosctl time [--check server] [flags]
Options
-c, --check string checks server time against specified ntp server
-h, --help help for time
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl upgrade
Upgrade Talos on the target node
talosctl upgrade [flags]
Options
--debug debug operation from kernel logs. --wait is set to true when this flag is set
-f, --force force the upgrade (skip checks on etcd health and members, might lead to data loss)
-h, --help help for upgrade
-i, --image string the container image to use for performing the install (default "ghcr.io/siderolabs/installer:v1.4.0-alpha.4")
--insecure upgrade using the insecure (encrypted with no auth) maintenance service
-p, --preserve preserve data
-s, --stage stage the upgrade to perform it after a reboot
--timeout duration time to wait for the operation is complete if --debug or --wait is set (default 30m0s)
--wait wait for the operation to complete, tracking its progress. always set to true when --debug is set (default true)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl upgrade-k8s
Upgrade Kubernetes control plane in the Talos cluster.
Synopsis
Command runs upgrade of Kubernetes control plane components between specified versions.
talosctl upgrade-k8s [flags]
Options
--dry-run skip the actual upgrade and show the upgrade plan instead
--endpoint string the cluster control plane endpoint
--from string the Kubernetes control plane version to upgrade from
-h, --help help for upgrade-k8s
--to string the Kubernetes control plane version to upgrade to (default "1.27.1")
--upgrade-kubelet upgrade kubelet service (default true)
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
-a, --all write counts for all files, not just directories
-d, --depth int32 maximum recursion depth
-h, --help help for usage
-H, --humanize humanize size and time in the output
-t, --threshold int threshold exclude entries smaller than SIZE if positive, or entries greater than SIZE if negative
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl validate
Validate config
talosctl validate [flags]
Options
-c, --config string the path of the config file
-h, --help help for validate
-m, --mode string the mode to validate the config for (valid values are metal, cloud, and container)
--strict treat validation warnings as errors
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl version
Prints the version
talosctl version [flags]
Options
--client Print client version only
-h, --help help for version
-i, --insecure use Talos maintenance mode API
--short Print the short version
Options inherited from parent commands
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
SEE ALSO
talosctl - A CLI for out-of-band management of Kubernetes nodes created by Talos
talosctl
A CLI for out-of-band management of Kubernetes nodes created by Talos
Options
--cluster string Cluster to connect to if a proxy endpoint is used.
--context string Context to be used in command
-e, --endpoints strings override default endpoints in Talos configuration
-h, --help help for talosctl
-n, --nodes strings target the specified nodes
--talosconfig string The path to the Talos configuration file. Defaults to 'TALOSCONFIG' env variable if set, otherwise '$HOME/.talos/config' and '/var/run/secrets/talos.dev/config' in order.
type: controlplane
# InstallConfig represents the installation options for preparing a node.install:
disk: /dev/sda # The disk used for installations.# Allows for supplying extra kernel args via the bootloader.extraKernelArgs:
- console=ttyS1
- panic=10
image: ghcr.io/siderolabs/installer:latest # Allows for supplying the image used to perform the installation.bootloader: true# Indicates if a bootloader should be installed.wipe: false# Indicates if the installation disk should be wiped at installation time.# # Look up disk using disk attributes like model, size, serial and others.# diskSelector:# size: 4GB # Disk size.# model: WDC* # Disk model `/sys/block/<dev>/device/model`.# busPath: /pci0000:00/0000:00:17.0/ata1/host0/target0:0:0/0:0:0:0 # Disk bus path.# # Allows for supplying additional system extension images to install on top of base Talos image.# extensions:# - image: ghcr.io/siderolabs/gvisor:20220117.0-v1.0.0 # System extension image.
Field
Type
Description
Value(s)
type
string
Defines the role of the machine within the cluster. Control Plane
Control Plane node type designates the node as a control plane member. This means it will host etcd along with the Kubernetes controlplane components such as API Server, Controller Manager, Scheduler.
Worker
Worker node type designates the node as a worker node. This means it will be an available compute node for scheduling workloads.
This node type was previously known as “join”; that value is still supported but deprecated.
controlplane worker
token
string
The token is used by a machine to join the PKI of the cluster.Using this token, a machine will create a certificate signing request (CSR), and request a certificate that will be used as its’ identity.Show example(s)
token: 328hom.uqjzh6jnn2eie9oi
ca
PEMEncodedCertificateAndKey
The root certificate authority of the PKI.It is composed of a base64 encoded crt and key.Show example(s)
Extra certificate subject alternative names for the machine’s certificate.By default, all non-loopback interface IPs are automatically added to the certificate’s SANs.Show example(s)
Provides machine specific control plane configuration options. Show example(s)
controlPlane:
# Controller manager machine specific configuration options.controllerManager:
disabled: false# Disable kube-controller-manager on the node.# Scheduler machine specific configuration options.scheduler:
disabled: true# Disable kube-scheduler on the node.
Used to provide additional options to the kubelet. Show example(s)
kubelet:
image: ghcr.io/siderolabs/kubelet:v1.27.1 # The `image` field is an optional reference to an alternative kubelet image.# The `extraArgs` field is used to provide additional flags to the kubelet.extraArgs:
feature-gates: ServerSideApply=true
# # The `ClusterDNS` field is an optional reference to an alternative kubelet clusterDNS ip list.# clusterDNS:# - 10.96.0.10# - 169.254.2.53# # The `extraMounts` field is used to add additional mounts to the kubelet container.# extraMounts:# - destination: /var/lib/example# type: bind# source: /var/lib/example# options:# - bind# - rshared# - rw# # The `extraConfig` field is used to provide kubelet configuration overrides.# extraConfig:# serverTLSBootstrap: true# # The `nodeIP` field is used to configure `--node-ip` flag for the kubelet.# nodeIP:# # The `validSubnets` field configures the networks to pick kubelet node IP from.# validSubnets:# - 10.0.0.0/8# - '!10.0.0.3/32'# - fdc7::/16
pods
[]Unstructured
Used to provide static pod definitions to be run by the kubelet directly bypassing the kube-apiserver. Static pods can be used to run components which should be started before the Kubernetes control plane is up. Talos doesn’t validate the pod definition. Updates to this field can be applied without a reboot.
Provides machine specific network configuration options. Show example(s)
network:
hostname: worker-1 # Used to statically set the hostname for the machine.# `interfaces` is used to define the network interface configuration.interfaces:
- interface: eth0 # The interface name.# Assigns static IP addresses to the interface.addresses:
- 192.168.2.0/24
# A list of routes associated with the interface.routes:
- network: 0.0.0.0/0 # The route's network (destination).gateway: 192.168.2.1# The route's gateway (if empty, creates link scope route).metric: 1024# The optional metric for the route.mtu: 1500# The interface's MTU.# # Picks a network device using the selector.# # select a device with bus prefix 00:*.# deviceSelector:# busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# # select a device with mac address matching `*:f0:ab` and `virtio` kernel driver.# deviceSelector:# hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# # select a device with bus prefix 00:*, a device with mac address matching `*:f0:ab` and `virtio` kernel driver.# deviceSelector:# - busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# - hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# # Bond specific options.# bond:# # The interfaces that make up the bond.# interfaces:# - eth0# - eth1# # Picks a network device using the selector.# deviceSelectors:# - busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# - hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# mode: 802.3ad # A bond option.# lacpRate: fast # A bond option.# # Bridge specific options.# bridge:# # The interfaces that make up the bridge.# interfaces:# - eth0# - eth1# # A bridge option.# stp:# enabled: true # Whether Spanning Tree Protocol (STP) is enabled.# # Indicates if DHCP should be used to configure the interface.# dhcp: true# # DHCP specific options.# dhcpOptions:# routeMetric: 1024 # The priority of all routes received via DHCP.# # Wireguard specific configuration.# # wireguard server example# wireguard:# privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# listenPort: 51111 # Specifies a device's listening port.# # Specifies a list of peer configurations to apply to a device.# peers:# - publicKey: ABCDEF... # Specifies the public key of this peer.# endpoint: 192.168.1.3 # Specifies the endpoint of this peer entry.# # AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.# allowedIPs:# - 192.168.1.0/24# # wireguard peer example# wireguard:# privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# # Specifies a list of peer configurations to apply to a device.# peers:# - publicKey: ABCDEF... # Specifies the public key of this peer.# endpoint: 192.168.1.2:51822 # Specifies the endpoint of this peer entry.# persistentKeepaliveInterval: 10s # Specifies the persistent keepalive interval for this peer.# # AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.# allowedIPs:# - 192.168.1.0/24# # Virtual (shared) IP address configuration.# # layer2 vip example# vip:# ip: 172.16.199.55 # Specifies the IP address to be used.# Used to statically set the nameservers for the machine.nameservers:
- 9.8.7.6 - 8.7.6.5# # Allows for extra entries to be added to the `/etc/hosts` file# extraHostEntries:# - ip: 192.168.1.100 # The IP of the host.# # The host alias.# aliases:# - example# - example.domain.tld# # Configures KubeSpan feature.# kubespan:# enabled: true # Enable the KubeSpan feature.
Used to partition, format and mount additional disks.Since the rootfs is read only with the exception of /var, mounts are only valid if they are under /var. Note that the partitioning and formatting is done only once, if and only if no existing XFS partitions are found. If size: is omitted, the partition is sized to occupy the full disk.Show example(s)
disks:
- device: /dev/sdb # The name of the disk to use.# A list of partitions to create on the disk.partitions:
- mountpoint: /var/mnt/extra # Where to mount the partition.# # The size of partition: either bytes or human readable representation. If `size:` is omitted, the partition is sized to occupy the full disk.# # Human readable representation.# size: 100 MB# # Precise value in bytes.# size: 1073741824
Used to provide instructions for installations. Note that this configuration section gets silently ignored by Talos images that are considered pre-installed. To make sure Talos installs according to the provided configuration, Talos should be booted with ISO or PXE-booted.Show example(s)
install:
disk: /dev/sda # The disk used for installations.# Allows for supplying extra kernel args via the bootloader.extraKernelArgs:
- console=ttyS1
- panic=10
image: ghcr.io/siderolabs/installer:latest # Allows for supplying the image used to perform the installation.bootloader: true# Indicates if a bootloader should be installed.wipe: false# Indicates if the installation disk should be wiped at installation time.# # Look up disk using disk attributes like model, size, serial and others.# diskSelector:# size: 4GB # Disk size.# model: WDC* # Disk model `/sys/block/<dev>/device/model`.# busPath: /pci0000:00/0000:00:17.0/ata1/host0/target0:0:0/0:0:0:0 # Disk bus path.# # Allows for supplying additional system extension images to install on top of base Talos image.# extensions:# - image: ghcr.io/siderolabs/gvisor:20220117.0-v1.0.0 # System extension image.
Allows the addition of user specified files.The value of op can be create, overwrite, or append. In the case of create, path must not exist. In the case of overwrite, and append, path must be a valid file. If an op value of append is used, the existing file will be appended. Note that the file contents are not required to be base64 encoded.Show example(s)
files:
- content: '...'# The contents of the file.permissions: 0o666# The file's permissions in octal.path: /tmp/file.txt # The path of the file.op: append # The operation to use
env
Env
The env field allows for the addition of environment variables.All environment variables are set on PID 1 in addition to every service.Show example(s)
env:
GRPC_GO_LOG_SEVERITY_LEVEL: info
GRPC_GO_LOG_VERBOSITY_LEVEL: "99"https_proxy: http://SERVER:PORT/
Used to configure the machine’s time settings. Show example(s)
time:
disabled: false# Indicates if the time service is disabled for the machine.# Specifies time (NTP) servers to use for setting the system time.servers:
- time.cloudflare.com
bootTimeout: 2m0s # Specifies the timeout when the node time is considered to be in sync unlocking the boot sequence.
sysctls
map[string]string
Used to configure the machine’s sysctls. Show example(s)
Used to configure the machine’s container image registry mirrors. Automatically generates matching CRI configuration for registry mirrors.
The mirrors section allows to redirect requests for images to a non-default registry, which might be a local registry or a caching mirror.
The config section provides a way to authenticate to the registry with TLS client identity, provide registry CA, or authentication information. Authentication information has same meaning with the corresponding field in .docker/config.json.
registries:
# Specifies mirror configuration for each registry host namespace.mirrors:
docker.io:
# List of endpoints (URLs) for registry mirrors to use.endpoints:
- https://registry.local
# Specifies TLS & auth configuration for HTTPS image registries.config:
registry.local:
# The TLS configuration for the registry.tls:
# Enable mutual TLS authentication with the registry.clientIdentity:
crt: LS0tIEVYQU1QTEUgQ0VSVElGSUNBVEUgLS0t
key: LS0tIEVYQU1QTEUgS0VZIC0tLQ==
# The auth configuration for this registry.auth:
username: username # Optional registry authentication.password: password # Optional registry authentication.
Machine system disk encryption configuration.Defines each system partition encryption parameters.Show example(s)
systemDiskEncryption:
# Ephemeral partition encryption.ephemeral:
provider: luks2 # Encryption provider to use for the encryption.# Defines the encryption keys generation and storage method.keys:
- # Deterministically generated key from the node UUID and PartitionLabel.nodeID: {}
slot: 0# Key slot number for LUKS2 encryption.# # Cipher kind to use for the encryption. Depends on the encryption provider.# cipher: aes-xts-plain64# # Defines the encryption sector size.# blockSize: 4096# # Additional --perf parameters for the LUKS2 encryption.# options:# - no_read_workqueue# - no_write_workqueue
Features describe individual Talos features that can be switched on or off. Show example(s)
features:
rbac: true# Enable role-based access control (RBAC).# # Configure Talos API access from Kubernetes pods.# kubernetesTalosAPIAccess:# enabled: true # Enable Talos API access from Kubernetes pods.# # The list of Talos API roles which can be granted for access from Kubernetes pods.# allowedRoles:# - os:reader# # The list of Kubernetes namespaces Talos API access is available from.# allowedKubernetesNamespaces:# - kube-system
Configures the seccomp profiles for the machine. Show example(s)
seccompProfiles:
- name: audit.json # The `name` field is used to provide the file name of the seccomp profile.# The `value` field is used to provide the seccomp profile.value:
defaultAction: SCMP_ACT_LOG
nodeLabels
map[string]string
Configures the node labels for the machine. Show example(s)
nodeLabels:
exampleLabel: exampleLabelValue
MachineSeccompProfile
MachineSeccompProfile defines seccomp profiles for the machine.
- name: audit.json # The `name` field is used to provide the file name of the seccomp profile.# The `value` field is used to provide the seccomp profile.value:
defaultAction: SCMP_ACT_LOG
Field
Type
Description
Value(s)
name
string
The name field is used to provide the file name of the seccomp profile.
value
Unstructured
The value field is used to provide the seccomp profile.
ClusterConfig
ClusterConfig represents the cluster-wide config values.
# ControlPlaneConfig represents the control plane configuration options.controlPlane:
endpoint: https://1.2.3.4 # Endpoint is the canonical controlplane endpoint, which can be an IP address or a DNS hostname.localAPIServerPort: 443# The port that the API server listens on internally.clusterName: talos.local
# ClusterNetworkConfig represents kube networking configuration options.network:
# The CNI used.cni:
name: flannel # Name of CNI to use.dnsDomain: cluster.local # The domain used by Kubernetes DNS.# The pod subnet CIDR.podSubnets:
- 10.244.0.0/16
# The service subnet CIDR.serviceSubnets:
- 10.96.0.0/12
Field
Type
Description
Value(s)
id
string
Globally unique identifier for this cluster (base64 encoded random 32 bytes).
secret
string
Shared secret of cluster (base64 encoded random 32 bytes).This secret is shared among cluster members but should never be sent over the network.
Provides control plane specific configuration options. Show example(s)
controlPlane:
endpoint: https://1.2.3.4 # Endpoint is the canonical controlplane endpoint, which can be an IP address or a DNS hostname.localAPIServerPort: 443# The port that the API server listens on internally.
Provides cluster specific network configuration options. Show example(s)
network:
# The CNI used.cni:
name: flannel # Name of CNI to use.dnsDomain: cluster.local # The domain used by Kubernetes DNS.# The pod subnet CIDR.podSubnets:
- 10.244.0.0/16
# The service subnet CIDR.serviceSubnets:
- 10.96.0.0/12
token
string
The bootstrap token used to join the cluster. Show example(s)
The base64 encoded aggregator certificate authority used by Kubernetes for front-proxy certificate generation. This CA can be self-signed.Show example(s)
API server specific configuration options. Show example(s)
apiServer:
image: registry.k8s.io/kube-apiserver:v1.27.1 # The container image used in the API server manifest.# Extra arguments to supply to the API server.extraArgs:
feature-gates: ServerSideApply=true
http2-max-streams-per-connection: "32"# Extra certificate subject alternative names for the API server's certificate.certSANs:
- 1.2.3.4 - 4.5.6.7# # Configure the API server admission plugins.# admissionControl:# - name: PodSecurity # Name is the name of the admission controller.# # Configuration is an embedded configuration object to be used as the plugin's# configuration:# apiVersion: pod-security.admission.config.k8s.io/v1alpha1# defaults:# audit: restricted# audit-version: latest# enforce: baseline# enforce-version: latest# warn: restricted# warn-version: latest# exemptions:# namespaces:# - kube-system# runtimeClasses: []# usernames: []# kind: PodSecurityConfiguration# # Configure the API server audit policy.# auditPolicy:# apiVersion: audit.k8s.io/v1# kind: Policy# rules:# - level: Metadata
Controller manager server specific configuration options. Show example(s)
controllerManager:
image: registry.k8s.io/kube-controller-manager:v1.27.1 # The container image used in the controller manager manifest.# Extra arguments to supply to the controller manager.extraArgs:
feature-gates: ServerSideApply=true
Kube-proxy server-specific configuration options Show example(s)
proxy:
image: registry.k8s.io/kube-proxy:v1.27.1 # The container image used in the kube-proxy manifest.mode: ipvs # proxy mode of kube-proxy.# Extra arguments to supply to kube-proxy.extraArgs:
proxy-mode: iptables
# # Disable kube-proxy deployment on cluster bootstrap.# disabled: false
Scheduler server specific configuration options. Show example(s)
scheduler:
image: registry.k8s.io/kube-scheduler:v1.27.1 # The container image used in the scheduler manifest.# Extra arguments to supply to the scheduler.extraArgs:
feature-gates: AllBeta=true
Configures cluster member discovery. Show example(s)
discovery:
enabled: true# Enable the cluster membership discovery feature.# Configure registries used for cluster member discovery.registries:
# Kubernetes registry uses Kubernetes API server to discover cluster members and stores additional informationkubernetes: {}
# Service registry is using an external service to push and pull information about cluster members.service:
endpoint: https://discovery.talos.dev/ # External service endpoint.
Etcd specific configuration options. Show example(s)
etcd:
image: gcr.io/etcd-development/etcd:v3.5.8 # The container image used to create the etcd service.# The `ca` is the root certificate authority of the PKI.ca:
crt: LS0tIEVYQU1QTEUgQ0VSVElGSUNBVEUgLS0t
key: LS0tIEVYQU1QTEUgS0VZIC0tLQ==
# Extra arguments to supply to etcd.extraArgs:
election-timeout: "5000"# # The `advertisedSubnets` field configures the networks to pick etcd advertised IP from.# advertisedSubnets:# - 10.0.0.0/8
External cloud provider configuration. Show example(s)
externalCloudProvider:
enabled: true# Enable external cloud provider.# A list of urls that point to additional manifests for an external cloud provider.manifests:
- https://raw.githubusercontent.com/kubernetes/cloud-provider-aws/v1.20.0-alpha.0/manifests/rbac.yaml
- https://raw.githubusercontent.com/kubernetes/cloud-provider-aws/v1.20.0-alpha.0/manifests/aws-cloud-controller-manager-daemonset.yaml
extraManifests
[]string
A list of urls that point to additional manifests.These will get automatically deployed as part of the bootstrap.Show example(s)
A map of key value pairs that will be added while fetching the extraManifests. Show example(s)
extraManifestHeaders:
Token: "1234567"X-ExtraInfo: info
inlineManifests
ClusterInlineManifests
A list of inline Kubernetes manifests.These will get automatically deployed as part of the bootstrap.Show example(s)
inlineManifests:
- name: namespace-ci # Name of the manifest.contents: |- # Manifest contents as a string.apiVersion: v1
kind: Namespace
metadata:
name: ci
# Controller manager machine specific configuration options.controllerManager:
disabled: false# Disable kube-controller-manager on the node.# Scheduler machine specific configuration options.scheduler:
disabled: true# Disable kube-scheduler on the node.
image: ghcr.io/siderolabs/kubelet:v1.27.1 # The `image` field is an optional reference to an alternative kubelet image.# The `extraArgs` field is used to provide additional flags to the kubelet.extraArgs:
feature-gates: ServerSideApply=true
# # The `ClusterDNS` field is an optional reference to an alternative kubelet clusterDNS ip list.# clusterDNS:# - 10.96.0.10# - 169.254.2.53# # The `extraMounts` field is used to add additional mounts to the kubelet container.# extraMounts:# - destination: /var/lib/example# type: bind# source: /var/lib/example# options:# - bind# - rshared# - rw# # The `extraConfig` field is used to provide kubelet configuration overrides.# extraConfig:# serverTLSBootstrap: true# # The `nodeIP` field is used to configure `--node-ip` flag for the kubelet.# nodeIP:# # The `validSubnets` field configures the networks to pick kubelet node IP from.# validSubnets:# - 10.0.0.0/8# - '!10.0.0.3/32'# - fdc7::/16
Field
Type
Description
Value(s)
image
string
The image field is an optional reference to an alternative kubelet image. Show example(s)
image: ghcr.io/siderolabs/kubelet:v1.27.1
clusterDNS
[]string
The ClusterDNS field is an optional reference to an alternative kubelet clusterDNS ip list. Show example(s)
clusterDNS:
- 10.96.0.10 - 169.254.2.53
extraArgs
map[string]string
The extraArgs field is used to provide additional flags to the kubelet. Show example(s)
The extraMounts field is used to add additional mounts to the kubelet container.Note that either bind or rbind are required in the options.Show example(s)
The extraConfig field is used to provide kubelet configuration overrides. Some fields are not allowed to be overridden: authentication and authorization, cgroups configuration, ports, etc.Show example(s)
extraConfig:
serverTLSBootstrap: true
defaultRuntimeSeccompProfileEnabled
bool
Enable container runtime default Seccomp profile.
true yes false no
registerWithFQDN
bool
The registerWithFQDN field is used to force kubelet to use the node FQDN for registration.This is required in clouds like AWS.
The nodeIP field is used to configure --node-ip flag for the kubelet.This is used when a node has multiple addresses to choose from.Show example(s)
nodeIP:
# The `validSubnets` field configures the networks to pick kubelet node IP from.validSubnets:
- 10.0.0.0/8
- '!10.0.0.3/32' - fdc7::/16
skipNodeRegistration
bool
The skipNodeRegistration is used to run the kubelet without registering with the apiserver.This runs kubelet as standalone and only runs static pods.
true yes false no
disableManifestsDirectory
bool
The disableManifestsDirectory field configures the kubelet to get static pod manifests from the /etc/kubernetes/manifests directory.It’s recommended to configure static pods with the “pods” key instead.
true yes false no
KubeletNodeIPConfig
KubeletNodeIPConfig represents the kubelet node IP configuration.
# The `validSubnets` field configures the networks to pick kubelet node IP from.validSubnets:
- 10.0.0.0/8
- '!10.0.0.3/32' - fdc7::/16
Field
Type
Description
Value(s)
validSubnets
[]string
The validSubnets field configures the networks to pick kubelet node IP from.For dual stack configuration, there should be two subnets: one for IPv4, another for IPv6. IPs can be excluded from the list by using negative match with !, e.g !10.0.0.0/8. Negative subnet matches should be specified last to filter out IPs picked by positive matches. If not specified, node IP is picked based on cluster podCIDRs: IPv4/IPv6 address or both.
NetworkConfig
NetworkConfig represents the machine’s networking config values.
hostname: worker-1 # Used to statically set the hostname for the machine.# `interfaces` is used to define the network interface configuration.interfaces:
- interface: eth0 # The interface name.# Assigns static IP addresses to the interface.addresses:
- 192.168.2.0/24
# A list of routes associated with the interface.routes:
- network: 0.0.0.0/0 # The route's network (destination).gateway: 192.168.2.1# The route's gateway (if empty, creates link scope route).metric: 1024# The optional metric for the route.mtu: 1500# The interface's MTU.# # Picks a network device using the selector.# # select a device with bus prefix 00:*.# deviceSelector:# busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# # select a device with mac address matching `*:f0:ab` and `virtio` kernel driver.# deviceSelector:# hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# # select a device with bus prefix 00:*, a device with mac address matching `*:f0:ab` and `virtio` kernel driver.# deviceSelector:# - busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# - hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# # Bond specific options.# bond:# # The interfaces that make up the bond.# interfaces:# - eth0# - eth1# # Picks a network device using the selector.# deviceSelectors:# - busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# - hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# mode: 802.3ad # A bond option.# lacpRate: fast # A bond option.# # Bridge specific options.# bridge:# # The interfaces that make up the bridge.# interfaces:# - eth0# - eth1# # A bridge option.# stp:# enabled: true # Whether Spanning Tree Protocol (STP) is enabled.# # Indicates if DHCP should be used to configure the interface.# dhcp: true# # DHCP specific options.# dhcpOptions:# routeMetric: 1024 # The priority of all routes received via DHCP.# # Wireguard specific configuration.# # wireguard server example# wireguard:# privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# listenPort: 51111 # Specifies a device's listening port.# # Specifies a list of peer configurations to apply to a device.# peers:# - publicKey: ABCDEF... # Specifies the public key of this peer.# endpoint: 192.168.1.3 # Specifies the endpoint of this peer entry.# # AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.# allowedIPs:# - 192.168.1.0/24# # wireguard peer example# wireguard:# privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# # Specifies a list of peer configurations to apply to a device.# peers:# - publicKey: ABCDEF... # Specifies the public key of this peer.# endpoint: 192.168.1.2:51822 # Specifies the endpoint of this peer entry.# persistentKeepaliveInterval: 10s # Specifies the persistent keepalive interval for this peer.# # AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.# allowedIPs:# - 192.168.1.0/24# # Virtual (shared) IP address configuration.# # layer2 vip example# vip:# ip: 172.16.199.55 # Specifies the IP address to be used.# Used to statically set the nameservers for the machine.nameservers:
- 9.8.7.6 - 8.7.6.5# # Allows for extra entries to be added to the `/etc/hosts` file# extraHostEntries:# - ip: 192.168.1.100 # The IP of the host.# # The host alias.# aliases:# - example# - example.domain.tld# # Configures KubeSpan feature.# kubespan:# enabled: true # Enable the KubeSpan feature.
Field
Type
Description
Value(s)
hostname
string
Used to statically set the hostname for the machine.
interfaces is used to define the network interface configuration.By default all network interfaces will attempt a DHCP discovery. This can be further tuned through this configuration parameter.Show example(s)
interfaces:
- interface: eth0 # The interface name.# Assigns static IP addresses to the interface.addresses:
- 192.168.2.0/24
# A list of routes associated with the interface.routes:
- network: 0.0.0.0/0 # The route's network (destination).gateway: 192.168.2.1# The route's gateway (if empty, creates link scope route).metric: 1024# The optional metric for the route.mtu: 1500# The interface's MTU.# # Picks a network device using the selector.# # select a device with bus prefix 00:*.# deviceSelector:# busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# # select a device with mac address matching `*:f0:ab` and `virtio` kernel driver.# deviceSelector:# hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# # select a device with bus prefix 00:*, a device with mac address matching `*:f0:ab` and `virtio` kernel driver.# deviceSelector:# - busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# - hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# # Bond specific options.# bond:# # The interfaces that make up the bond.# interfaces:# - eth0# - eth1# # Picks a network device using the selector.# deviceSelectors:# - busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# - hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# mode: 802.3ad # A bond option.# lacpRate: fast # A bond option.# # Bridge specific options.# bridge:# # The interfaces that make up the bridge.# interfaces:# - eth0# - eth1# # A bridge option.# stp:# enabled: true # Whether Spanning Tree Protocol (STP) is enabled.# # Indicates if DHCP should be used to configure the interface.# dhcp: true# # DHCP specific options.# dhcpOptions:# routeMetric: 1024 # The priority of all routes received via DHCP.# # Wireguard specific configuration.# # wireguard server example# wireguard:# privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# listenPort: 51111 # Specifies a device's listening port.# # Specifies a list of peer configurations to apply to a device.# peers:# - publicKey: ABCDEF... # Specifies the public key of this peer.# endpoint: 192.168.1.3 # Specifies the endpoint of this peer entry.# # AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.# allowedIPs:# - 192.168.1.0/24# # wireguard peer example# wireguard:# privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# # Specifies a list of peer configurations to apply to a device.# peers:# - publicKey: ABCDEF... # Specifies the public key of this peer.# endpoint: 192.168.1.2:51822 # Specifies the endpoint of this peer entry.# persistentKeepaliveInterval: 10s # Specifies the persistent keepalive interval for this peer.# # AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.# allowedIPs:# - 192.168.1.0/24# # Virtual (shared) IP address configuration.# # layer2 vip example# vip:# ip: 172.16.199.55 # Specifies the IP address to be used.
nameservers
[]string
Used to statically set the nameservers for the machine.Defaults to 1.1.1.1 and 8.8.8.8Show example(s)
disk: /dev/sda # The disk used for installations.# Allows for supplying extra kernel args via the bootloader.extraKernelArgs:
- console=ttyS1
- panic=10
image: ghcr.io/siderolabs/installer:latest # Allows for supplying the image used to perform the installation.bootloader: true# Indicates if a bootloader should be installed.wipe: false# Indicates if the installation disk should be wiped at installation time.# # Look up disk using disk attributes like model, size, serial and others.# diskSelector:# size: 4GB # Disk size.# model: WDC* # Disk model `/sys/block/<dev>/device/model`.# busPath: /pci0000:00/0000:00:17.0/ata1/host0/target0:0:0/0:0:0:0 # Disk bus path.# # Allows for supplying additional system extension images to install on top of base Talos image.# extensions:# - image: ghcr.io/siderolabs/gvisor:20220117.0-v1.0.0 # System extension image.
Look up disk using disk attributes like model, size, serial and others.Always has priority over disk.Show example(s)
diskSelector:
size: 4GB # Disk size.model: WDC* # Disk model `/sys/block/<dev>/device/model`.busPath: /pci0000:00/0000:00:17.0/ata1/host0/target0:0:0/0:0:0:0 # Disk bus path.
extraKernelArgs
[]string
Allows for supplying extra kernel args via the bootloader. Show example(s)
Allows for supplying the image used to perform the installation.Image reference for each Talos release can be found on GitHub releases page.Show example(s)
Allows for supplying additional system extension images to install on top of base Talos image. Show example(s)
extensions:
- image: ghcr.io/siderolabs/gvisor:20220117.0-v1.0.0 # System extension image.
bootloader
bool
Indicates if a bootloader should be installed.
true yes false no
wipe
bool
Indicates if the installation disk should be wiped at installation time.Defaults to true.
true yes false no
legacyBIOSSupport
bool
Indicates if MBR partition should be marked as bootable (active).Should be enabled only for the systems with legacy BIOS that doesn’t support GPT partitioning scheme.
InstallDiskSelector
InstallDiskSelector represents a disk query parameters for the install disk lookup.
size: 4GB # Disk size.model: WDC* # Disk model `/sys/block/<dev>/device/model`.busPath: /pci0000:00/0000:00:17.0/ata1/host0/target0:0:0/0:0:0:0 # Disk bus path.
disabled: false# Indicates if the time service is disabled for the machine.# Specifies time (NTP) servers to use for setting the system time.servers:
- time.cloudflare.com
bootTimeout: 2m0s # Specifies the timeout when the node time is considered to be in sync unlocking the boot sequence.
Field
Type
Description
Value(s)
disabled
bool
Indicates if the time service is disabled for the machine.Defaults to false.
servers
[]string
Specifies time (NTP) servers to use for setting the system time.Defaults to pool.ntp.org
bootTimeout
Duration
Specifies the timeout when the node time is considered to be in sync unlocking the boot sequence.NTP sync will be still running in the background. Defaults to “infinity” (waiting forever for time sync)
RegistriesConfig
RegistriesConfig represents the image pull options.
# Specifies mirror configuration for each registry host namespace.mirrors:
docker.io:
# List of endpoints (URLs) for registry mirrors to use.endpoints:
- https://registry.local
# Specifies TLS & auth configuration for HTTPS image registries.config:
registry.local:
# The TLS configuration for the registry.tls:
# Enable mutual TLS authentication with the registry.clientIdentity:
crt: LS0tIEVYQU1QTEUgQ0VSVElGSUNBVEUgLS0t
key: LS0tIEVYQU1QTEUgS0VZIC0tLQ==
# The auth configuration for this registry.auth:
username: username # Optional registry authentication.password: password # Optional registry authentication.
Specifies mirror configuration for each registry host namespace.This setting allows to configure local pull-through caching registires, air-gapped installations, etc.
For example, when pulling an image with the reference example.com:123/image:v1, the example.com:123 key will be used to lookup the mirror configuration.
Optionally the * key can be used to configure a fallback mirror.
Registry name is the first segment of image identifier, with ‘docker.io’ being default one.Show example(s)
mirrors:
ghcr.io:
# List of endpoints (URLs) for registry mirrors to use.endpoints:
- https://registry.insecure
- https://ghcr.io/v2/
endpoint: https://1.2.3.4 # Endpoint is the canonical controlplane endpoint, which can be an IP address or a DNS hostname.localAPIServerPort: 443# The port that the API server listens on internally.
Endpoint is the canonical controlplane endpoint, which can be an IP address or a DNS hostname.It is single-valued, and may optionally include a port number.Show example(s)
endpoint: https://1.2.3.4:6443
endpoint: https://cluster1.internal:6443
localAPIServerPort
int
The port that the API server listens on internally.This may be different than the port portion listed in the endpoint field above. The default is 6443.
APIServerConfig
APIServerConfig represents the kube apiserver configuration options.
image: registry.k8s.io/kube-apiserver:v1.27.1 # The container image used in the API server manifest.# Extra arguments to supply to the API server.extraArgs:
feature-gates: ServerSideApply=true
http2-max-streams-per-connection: "32"# Extra certificate subject alternative names for the API server's certificate.certSANs:
- 1.2.3.4 - 4.5.6.7# # Configure the API server admission plugins.# admissionControl:# - name: PodSecurity # Name is the name of the admission controller.# # Configuration is an embedded configuration object to be used as the plugin's# configuration:# apiVersion: pod-security.admission.config.k8s.io/v1alpha1# defaults:# audit: restricted# audit-version: latest# enforce: baseline# enforce-version: latest# warn: restricted# warn-version: latest# exemptions:# namespaces:# - kube-system# runtimeClasses: []# usernames: []# kind: PodSecurityConfiguration# # Configure the API server audit policy.# auditPolicy:# apiVersion: audit.k8s.io/v1# kind: Policy# rules:# - level: Metadata
Field
Type
Description
Value(s)
image
string
The container image used in the API server manifest. Show example(s)
Configure the API server admission plugins. Show example(s)
admissionControl:
- name: PodSecurity # Name is the name of the admission controller.# Configuration is an embedded configuration object to be used as the plugin'sconfiguration:
apiVersion: pod-security.admission.config.k8s.io/v1alpha1
defaults:
audit: restricted
audit-version: latest
enforce: baseline
enforce-version: latest
warn: restricted
warn-version: latest
exemptions:
namespaces:
- kube-system
runtimeClasses: []
usernames: []
kind: PodSecurityConfiguration
auditPolicy
Unstructured
Configure the API server audit policy. Show example(s)
- name: PodSecurity # Name is the name of the admission controller.# Configuration is an embedded configuration object to be used as the plugin'sconfiguration:
apiVersion: pod-security.admission.config.k8s.io/v1alpha1
defaults:
audit: restricted
audit-version: latest
enforce: baseline
enforce-version: latest
warn: restricted
warn-version: latest
exemptions:
namespaces:
- kube-system
runtimeClasses: []
usernames: []
kind: PodSecurityConfiguration
Field
Type
Description
Value(s)
name
string
Name is the name of the admission controller.It must match the registered admission plugin name.
configuration
Unstructured
Configuration is an embedded configuration object to be used as the plugin’sconfiguration.
ControllerManagerConfig
ControllerManagerConfig represents the kube controller manager configuration options.
image: registry.k8s.io/kube-controller-manager:v1.27.1 # The container image used in the controller manager manifest.# Extra arguments to supply to the controller manager.extraArgs:
feature-gates: ServerSideApply=true
Field
Type
Description
Value(s)
image
string
The container image used in the controller manager manifest. Show example(s)
image: registry.k8s.io/kube-proxy:v1.27.1 # The container image used in the kube-proxy manifest.mode: ipvs # proxy mode of kube-proxy.# Extra arguments to supply to kube-proxy.extraArgs:
proxy-mode: iptables
# # Disable kube-proxy deployment on cluster bootstrap.# disabled: false
Field
Type
Description
Value(s)
disabled
bool
Disable kube-proxy deployment on cluster bootstrap. Show example(s)
disabled: false
image
string
The container image used in the kube-proxy manifest. Show example(s)
image: registry.k8s.io/kube-proxy:v1.27.1
mode
string
proxy mode of kube-proxy.The default is ‘iptables’.
extraArgs
map[string]string
Extra arguments to supply to kube-proxy.
SchedulerConfig
SchedulerConfig represents the kube scheduler configuration options.
image: registry.k8s.io/kube-scheduler:v1.27.1 # The container image used in the scheduler manifest.# Extra arguments to supply to the scheduler.extraArgs:
feature-gates: AllBeta=true
Field
Type
Description
Value(s)
image
string
The container image used in the scheduler manifest. Show example(s)
image: gcr.io/etcd-development/etcd:v3.5.8 # The container image used to create the etcd service.# The `ca` is the root certificate authority of the PKI.ca:
crt: LS0tIEVYQU1QTEUgQ0VSVElGSUNBVEUgLS0t
key: LS0tIEVYQU1QTEUgS0VZIC0tLQ==
# Extra arguments to supply to etcd.extraArgs:
election-timeout: "5000"# # The `advertisedSubnets` field configures the networks to pick etcd advertised IP from.# advertisedSubnets:# - 10.0.0.0/8
Field
Type
Description
Value(s)
image
string
The container image used to create the etcd service. Show example(s)
image: gcr.io/etcd-development/etcd:v3.5.8
ca
PEMEncodedCertificateAndKey
The ca is the root certificate authority of the PKI.It is composed of a base64 encoded crt and key.Show example(s)
The advertisedSubnets field configures the networks to pick etcd advertised IP from. IPs can be excluded from the list by using negative match with !, e.g !10.0.0.0/8. Negative subnet matches should be specified last to filter out IPs picked by positive matches. If not specified, advertised IP is selected as the first routable address of the node.Show example(s)
advertisedSubnets:
- 10.0.0.0/8
listenSubnets
[]string
The listenSubnets field configures the networks for the etcd to listen for peer and client connections. If listenSubnets is not set, but advertisedSubnets is set, listenSubnets defaults to advertisedSubnets.
If neither advertisedSubnets nor listenSubnets is set, listenSubnets defaults to listen on all addresses.
IPs can be excluded from the list by using negative match with !, e.g !10.0.0.0/8. Negative subnet matches should be specified last to filter out IPs picked by positive matches. If not specified, advertised IP is selected as the first routable address of the node.
# The CNI used.cni:
name: flannel # Name of CNI to use.dnsDomain: cluster.local # The domain used by Kubernetes DNS.# The pod subnet CIDR.podSubnets:
- 10.244.0.0/16
# The service subnet CIDR.serviceSubnets:
- 10.96.0.0/12
The CNI used.Composed of “name” and “urls”. The “name” key supports the following options: “flannel”, “custom”, and “none”. “flannel” uses Talos-managed Flannel CNI, and that’s the default option. “custom” uses custom manifests that should be provided in “urls”. “none” indicates that Talos will not manage any CNI installation.Show example(s)
cni:
name: custom # Name of CNI to use.# URLs containing manifests to apply for the CNI.urls:
- https://docs.projectcalico.org/archive/v3.20/manifests/canal.yaml
dnsDomain
string
The domain used by Kubernetes DNS.The default is cluster.localShow example(s)
dnsDomain: cluser.local
podSubnets
[]string
The pod subnet CIDR. Show example(s)
podSubnets:
- 10.244.0.0/16
serviceSubnets
[]string
The service subnet CIDR. Show example(s)
serviceSubnets:
- 10.96.0.0/12
CNIConfig
CNIConfig represents the CNI configuration options.
name: custom # Name of CNI to use.# URLs containing manifests to apply for the CNI.urls:
- https://docs.projectcalico.org/archive/v3.20/manifests/canal.yaml
Field
Type
Description
Value(s)
name
string
Name of CNI to use.
flannel custom none
urls
[]string
URLs containing manifests to apply for the CNI.Should be present for “custom”, must be empty for “flannel” and “none”.
enabled: true# Enable external cloud provider.# A list of urls that point to additional manifests for an external cloud provider.manifests:
- https://raw.githubusercontent.com/kubernetes/cloud-provider-aws/v1.20.0-alpha.0/manifests/rbac.yaml
- https://raw.githubusercontent.com/kubernetes/cloud-provider-aws/v1.20.0-alpha.0/manifests/aws-cloud-controller-manager-daemonset.yaml
Field
Type
Description
Value(s)
enabled
bool
Enable external cloud provider.
true yes false no
manifests
[]string
A list of urls that point to additional manifests for an external cloud provider.These will get automatically deployed as part of the bootstrap.Show example(s)
- device: /dev/sdb # The name of the disk to use.# A list of partitions to create on the disk.partitions:
- mountpoint: /var/mnt/extra # Where to mount the partition.# # The size of partition: either bytes or human readable representation. If `size:` is omitted, the partition is sized to occupy the full disk.# # Human readable representation.# size: 100 MB# # Precise value in bytes.# size: 1073741824
The size of partition: either bytes or human readable representation. If size: is omitted, the partition is sized to occupy the full disk. Show example(s)
- content: '...'# The contents of the file.permissions: 0o666# The file's permissions in octal.path: /tmp/file.txt # The path of the file.op: append # The operation to use
- interface: eth0 # The interface name.# Assigns static IP addresses to the interface.addresses:
- 192.168.2.0/24
# A list of routes associated with the interface.routes:
- network: 0.0.0.0/0 # The route's network (destination).gateway: 192.168.2.1# The route's gateway (if empty, creates link scope route).metric: 1024# The optional metric for the route.mtu: 1500# The interface's MTU.# # Picks a network device using the selector.# # select a device with bus prefix 00:*.# deviceSelector:# busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# # select a device with mac address matching `*:f0:ab` and `virtio` kernel driver.# deviceSelector:# hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# # select a device with bus prefix 00:*, a device with mac address matching `*:f0:ab` and `virtio` kernel driver.# deviceSelector:# - busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# - hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# # Bond specific options.# bond:# # The interfaces that make up the bond.# interfaces:# - eth0# - eth1# # Picks a network device using the selector.# deviceSelectors:# - busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.# - hardwareAddr: '*:f0:ab' # Device hardware address, supports matching by wildcard.# driver: virtio # Kernel driver, supports matching by wildcard.# mode: 802.3ad # A bond option.# lacpRate: fast # A bond option.# # Bridge specific options.# bridge:# # The interfaces that make up the bridge.# interfaces:# - eth0# - eth1# # A bridge option.# stp:# enabled: true # Whether Spanning Tree Protocol (STP) is enabled.# # Indicates if DHCP should be used to configure the interface.# dhcp: true# # DHCP specific options.# dhcpOptions:# routeMetric: 1024 # The priority of all routes received via DHCP.# # Wireguard specific configuration.# # wireguard server example# wireguard:# privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# listenPort: 51111 # Specifies a device's listening port.# # Specifies a list of peer configurations to apply to a device.# peers:# - publicKey: ABCDEF... # Specifies the public key of this peer.# endpoint: 192.168.1.3 # Specifies the endpoint of this peer entry.# # AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.# allowedIPs:# - 192.168.1.0/24# # wireguard peer example# wireguard:# privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# # Specifies a list of peer configurations to apply to a device.# peers:# - publicKey: ABCDEF... # Specifies the public key of this peer.# endpoint: 192.168.1.2:51822 # Specifies the endpoint of this peer entry.# persistentKeepaliveInterval: 10s # Specifies the persistent keepalive interval for this peer.# # AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.# allowedIPs:# - 192.168.1.0/24# # Virtual (shared) IP address configuration.# # layer2 vip example# vip:# ip: 172.16.199.55 # Specifies the IP address to be used.
Field
Type
Description
Value(s)
interface
string
The interface name.Mutually exclusive with deviceSelector.Show example(s)
Picks a network device using the selector.Mutually exclusive with interface. Supports partial match using wildcard syntax.Show example(s)
deviceSelector:
busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard.
deviceSelector:
hardwareAddr: '*:f0:ab'# Device hardware address, supports matching by wildcard.driver: virtio # Kernel driver, supports matching by wildcard.
addresses
[]string
Assigns static IP addresses to the interface.An address can be specified either in proper CIDR notation or as a standalone address (netmask of all ones is assumed).Show example(s)
A list of routes associated with the interface.If used in combination with DHCP, these routes will be appended to routes returned by DHCP server.Show example(s)
routes:
- network: 0.0.0.0/0 # The route's network (destination).gateway: 10.5.0.1# The route's gateway (if empty, creates link scope route). - network: 10.2.0.0/16 # The route's network (destination).gateway: 10.2.0.1# The route's gateway (if empty, creates link scope route).
bond:
# The interfaces that make up the bond.interfaces:
- eth0
- eth1
# Picks a network device using the selector.deviceSelectors:
- busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard. - hardwareAddr: '*:f0:ab'# Device hardware address, supports matching by wildcard.driver: virtio # Kernel driver, supports matching by wildcard.mode: 802.3ad # A bond option.lacpRate: fast # A bond option.
bridge:
# The interfaces that make up the bridge.interfaces:
- eth0
- eth1
# A bridge option.stp:
enabled: true# Whether Spanning Tree Protocol (STP) is enabled.
Wireguard specific configuration.Includes things like private key, listen port, peers.Show example(s)
wireguard:
privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).listenPort: 51111# Specifies a device's listening port.# Specifies a list of peer configurations to apply to a device.peers:
- publicKey: ABCDEF... # Specifies the public key of this peer.endpoint: 192.168.1.3# Specifies the endpoint of this peer entry.# AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.allowedIPs:
- 192.168.1.0/24
wireguard:
privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# Specifies a list of peer configurations to apply to a device.peers:
- publicKey: ABCDEF... # Specifies the public key of this peer.endpoint: 192.168.1.2:51822# Specifies the endpoint of this peer entry.persistentKeepaliveInterval: 10s # Specifies the persistent keepalive interval for this peer.# AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.allowedIPs:
- 192.168.1.0/24
privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).listenPort: 51111# Specifies a device's listening port.# Specifies a list of peer configurations to apply to a device.peers:
- publicKey: ABCDEF... # Specifies the public key of this peer.endpoint: 192.168.1.3# Specifies the endpoint of this peer entry.# AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.allowedIPs:
- 192.168.1.0/24
privateKey: ABCDEF... # Specifies a private key configuration (base64 encoded).# Specifies a list of peer configurations to apply to a device.peers:
- publicKey: ABCDEF... # Specifies the public key of this peer.endpoint: 192.168.1.2:51822# Specifies the endpoint of this peer entry.persistentKeepaliveInterval: 10s # Specifies the persistent keepalive interval for this peer.# AllowedIPs specifies a list of allowed IP addresses in CIDR notation for this peer.allowedIPs:
- 192.168.1.0/24
Field
Type
Description
Value(s)
privateKey
string
Specifies a private key configuration (base64 encoded).Can be generated by wg genkey.
# The interfaces that make up the bond.interfaces:
- eth0
- eth1
# Picks a network device using the selector.deviceSelectors:
- busPath: 00:* # PCI, USB bus prefix, supports matching by wildcard. - hardwareAddr: '*:f0:ab'# Device hardware address, supports matching by wildcard.driver: virtio # Kernel driver, supports matching by wildcard.mode: 802.3ad # A bond option.lacpRate: fast # A bond option.
# The interfaces that make up the bridge.interfaces:
- eth0
- eth1
# A bridge option.stp:
enabled: true# Whether Spanning Tree Protocol (STP) is enabled.
ghcr.io:
# List of endpoints (URLs) for registry mirrors to use.endpoints:
- https://registry.insecure
- https://ghcr.io/v2/
Field
Type
Description
Value(s)
endpoints
[]string
List of endpoints (URLs) for registry mirrors to use.Endpoint configures HTTP/HTTPS access mode, host name, port and path (if path is not set, it defaults to /v2).
overridePath
bool
Use the exact path specified for the endpoint (don’t append /v2/).This setting is often required for setting up multiple mirrors on a single instance of a registry.
RegistryConfig
RegistryConfig specifies auth & TLS config per registry.
The auth configuration for this registry.Note: changes to the registry auth will not be picked up by the CRI containerd plugin without a reboot.Show example(s)
# Ephemeral partition encryption.ephemeral:
provider: luks2 # Encryption provider to use for the encryption.# Defines the encryption keys generation and storage method.keys:
- # Deterministically generated key from the node UUID and PartitionLabel.nodeID: {}
slot: 0# Key slot number for LUKS2 encryption.# # Cipher kind to use for the encryption. Depends on the encryption provider.# cipher: aes-xts-plain64# # Defines the encryption sector size.# blockSize: 4096# # Additional --perf parameters for the LUKS2 encryption.# options:# - no_read_workqueue# - no_write_workqueue
rbac: true# Enable role-based access control (RBAC).# # Configure Talos API access from Kubernetes pods.# kubernetesTalosAPIAccess:# enabled: true # Enable Talos API access from Kubernetes pods.# # The list of Talos API roles which can be granted for access from Kubernetes pods.# allowedRoles:# - os:reader# # The list of Kubernetes namespaces Talos API access is available from.# allowedKubernetesNamespaces:# - kube-system
Configure Talos API access from Kubernetes pods. This feature is disabled if the feature config is not specified.Show example(s)
kubernetesTalosAPIAccess:
enabled: true# Enable Talos API access from Kubernetes pods.# The list of Talos API roles which can be granted for access from Kubernetes pods.allowedRoles:
- os:reader
# The list of Kubernetes namespaces Talos API access is available from.allowedKubernetesNamespaces:
- kube-system
apidCheckExtKeyUsage
bool
Enable checks for extended key usage of client certificates in apid.
KubernetesTalosAPIAccessConfig
KubernetesTalosAPIAccessConfig describes the configuration for the Talos API access from Kubernetes pods.
enabled: true# Enable Talos API access from Kubernetes pods.# The list of Talos API roles which can be granted for access from Kubernetes pods.allowedRoles:
- os:reader
# The list of Kubernetes namespaces Talos API access is available from.allowedKubernetesNamespaces:
- kube-system
Field
Type
Description
Value(s)
enabled
bool
Enable Talos API access from Kubernetes pods.
allowedRoles
[]string
The list of Talos API roles which can be granted for access from Kubernetes pods. Empty list means that no roles can be granted, so access is blocked.
allowedKubernetesNamespaces
[]string
The list of Kubernetes namespaces Talos API access is available from.
VolumeMountConfig
VolumeMountConfig struct describes extra volume mount for the static pods.
Enable the KubeSpan feature.Cluster discovery should be enabled with .cluster.discovery.enabled for KubeSpan to be enabled.
advertiseKubernetesNetworks
bool
Control whether Kubernetes pod CIDRs are announced over KubeSpan from the node.If disabled, CNI handles encapsulating pod-to-pod traffic into some node-to-node tunnel, and KubeSpan handles the node-to-node traffic. If enabled, KubeSpan will take over pod-to-pod traffic and send it over KubeSpan directly. When enabled, KubeSpan should have a way to detect complete pod CIDRs of the node which is not always the case with CNIs not relying on Kubernetes for IPAM.
allowDownPeerBypass
bool
Skip sending traffic via KubeSpan if the peer connection state is not up.This provides configurable choice between connectivity and security: either traffic is always forced to go via KubeSpan (even if Wireguard peer connection is not up), or traffic can go directly to the peer if Wireguard connection can’t be established.
Filter node addresses which will be advertised as KubeSpan endpoints for peer-to-peer Wireguard connections. By default, all addresses are advertised, and KubeSpan cycles through all endpoints until it finds one that works.
enabled: true# Enable the cluster membership discovery feature.# Configure registries used for cluster member discovery.registries:
# Kubernetes registry uses Kubernetes API server to discover cluster members and stores additional informationkubernetes: {}
# Service registry is using an external service to push and pull information about cluster members.service:
endpoint: https://discovery.talos.dev/ # External service endpoint.
Field
Type
Description
Value(s)
enabled
bool
Enable the cluster membership discovery feature.Cluster discovery is based on individual registries which are configured under the registries field.
Talos supports a number of kernel commandline parameters. Some are required for
it to operate. Others are optional and useful in certain circumstances.
Several of these are enforced by the Kernel Self Protection Project KSPP.
Required parameters:
talos.platform: can be one of aws, azure, container, digitalocean, equinixMetal, gcp, hcloud, metal, nocloud, openstack, oracle, scaleway, upcloud, vmware or vultr
slab_nomerge: required by KSPP
pti=on: required by KSPP
Recommended parameters:
init_on_alloc=1: advised by KSPP, enabled by default in kernel config
init_on_free=1: advised by KSPP, enabled by default in kernel config
Available Talos-specific parameters
ip
Initial configuration of the interface, routes, DNS, NTP servers (multiple ip= kernel parameters are accepted).
Talos will use the configuration supplied via the kernel parameter as the initial network configuration.
This parameter is useful in the environments where DHCP doesn’t provide IP addresses or when default DNS and NTP servers should be overridden
before loading machine configuration.
Partial configuration can be applied as well, e.g. ip=:::::::<dns0-ip>:<dns1-ip>:<ntp0-ip> sets only the DNS and NTP servers.
IPv6 addresses can be specified by enclosing them in the square brackets, e.g. ip=[2001:db8::a]:[2001:db8::b]:[fe80::1]::controlplane1:eth1::[2001:4860:4860::6464]:[2001:4860:4860::64]:[2001:4860:4806::].
<netmask> can use either an IP address notation (IPv4: 255.255.255.0, IPv6: [ffff:ffff:ffff:ffff::0]), or simply a number of one bits in the netmask (24).
<device> can be traditional interface naming scheme eth0, eth1 or enx<MAC>, example: enx78e7d1ea46da
DHCP can be enabled by setting <autoconf> to dhcp, example: ip=:::::eth0.3:dhcp.
Alternative syntax is ip=eth0.3:dhcp.
Talos will use the bond= kernel parameter if supplied to set the initial bond configuration.
This parameter is useful in environments where the switch ports are suspended if the machine doesn’t setup a LACP bond.
If only the bond name is supplied, the bond will be created with eth0 and eth1 as slaves and bond mode set as balance-rr
All these below configurations are equivalent:
bond=bond0
bond=bond0:
bond=bond0::
bond=bond0:::
bond=bond0:eth0,eth1
bond=bond0:eth0,eth1:balance-rr
An example of a bond configuration with all options specified:
This will create a bond interface named bond1 with eth3 and eth4 as slaves and set the bond mode to 802.3ad, the transmit hash policy to layer2+3 and bond interface MTU to 1450.
Talos will use the vlan= kernel parameter if supplied to set the initial vlan configuration.
This parameter is useful in environments where the switch ports are VLAN tagged with no native VLAN.
Only one vlan can be configured at this stage.
An example of a vlan configuration including static ip configuration:
This will create a vlan interface named eth0.100 with eth0 as the underlying interface and set the vlan id to 100 with static IP 172.20.0.2/24 and 172.20.0.1 as default gateway.
panic
The amount of time to wait after a panic before a reboot is issued.
Talos will always reboot if it encounters an unrecoverable error.
However, when collecting debug information, it may reboot too quickly for
humans to read the logs.
This option allows the user to delay the reboot to give time to collect debug
information from the console screen.
A value of 0 disables automatic rebooting entirely.
talos.config
The URL at which the machine configuration data may be found (only for metal platform, with the kernel parameter talos.platform=metal).
This parameter supports variable substitution inside URL query values for the following case-insensitive placeholders:
${uuid} the SMBIOS UUID
${serial} the SMBIOS Serial Number
${mac} the MAC address of the first network interface attaining link state up
For backwards compatibility we insert the system UUID into the query parameter uuid if its value is empty. As in
http://example.com/metadata?uuid= => http://example.com/metadata?uuid=40dcbd19-3b10-444e-bfff-aaee44a51fda
metal-iso
When the kernel parameter talos.config=metal-iso is set, Talos will attempt to load the machine configuration from any block device with a filesystem label of metal-iso.
Talos will look for a file named config.yaml in the root of the filesystem.
For example, such ISO filesystem can be created with:
The board name, if Talos is being used on an ARM64 SBC.
Supported boards are:
bananapi_m64: Banana Pi M64
libretech_all_h3_cc_h5: Libre Computer ALL-H3-CC
rock64: Pine64 Rock64
rpi_4: Raspberry Pi 4, Model B
talos.hostname
The hostname to be used.
The hostname is generally specified in the machine config.
However, in some cases, the DHCP server needs to know the hostname
before the machine configuration has been acquired.
Unless specifically required, the machine configuration should be used
instead.
talos.shutdown
The type of shutdown to use when Talos is told to shutdown.
Valid options are:
halt
poweroff
talos.network.interface.ignore
A network interface which should be ignored and not configured by Talos.
Before a configuration is applied (early on each boot), Talos attempts to
configure each network interface by DHCP.
If there are many network interfaces on the machine which have link but no
DHCP server, this can add significant boot delays.
This option may be specified multiple times for multiple network interfaces.
talos.experimental.wipe
Resets the disk before starting up the system.
Valid options are:
system resets system disk.
system:EPHEMERAL,STATE resets ephemeral and state partitions. Doing this reverts Talos into maintenance mode.
talos.unified_cgroup_hierarchy
Talos defaults to always using the unified cgroup hierarchy (cgroupsv2), but cgroupsv1
can be forced with talos.unified_cgroup_hierarchy=0.
Note: cgroupsv1 is deprecated and it should be used only for compatibility with workloads which don’t support cgroupsv2 yet.
talos.dashboard.disabled
By default, Talos redirects kernel logs to virtual console /dev/tty1 and starts the dashboard on /dev/tty2,
then switches to the dashboard tty.
If you set talos.dashboard.disabled=1, this behavior will be disabled.
Kernel logs will be sent to the currently active console and the dashboard will not be started.
It is set to be 1 by default on SBCs.
talos.environment
Each value of the argument sets a default environment variable.
The expected format is key=value.
Learn about the philosophy behind the need for Talos Linux.
Distributed
Talos is intended to be operated in a distributed manner: it is built for a high-availability dataplane first.
Its etcd cluster is built in an ad-hoc manner, with each appointed node joining on its own directive (with proper security validations enforced, of course).
Like Kubernetes, workloads are intended to be distributed across any number of compute nodes.
There should be no single points of failure, and the level of required coordination is as low as each platform allows.
Immutable
Talos takes immutability very seriously.
Talos itself, even when installed on a disk, always runs from a SquashFS image, meaning that even if a directory is mounted to be writable, the image itself is never modified.
All images are signed and delivered as single, versioned files.
We can always run integrity checks on our image to verify that it has not been modified.
While Talos does allow a few, highly-controlled write points to the filesystem, we strive to make them as non-unique and non-critical as possible.
We call the writable partition the “ephemeral” partition precisely because we want to make sure none of us ever uses it for unique, non-replicated, non-recreatable data.
Thus, if all else fails, we can always wipe the disk and get back up and running.
Minimal
We are always trying to reduce Talos’ footprint.
Because nearly the entire OS is built from scratch in Go, we are
in a good position.
We have no shell.
We have no SSH.
We have none of the GNU utilities, not even a rollup tool such as busybox.
Everything in Talos is there because it is necessary, and
nothing is included which isn’t.
As a result, the OS right now produces a SquashFS image size of less than 80 MB.
Ephemeral
Everything Talos writes to its disk is either replicated or reconstructable.
Since the controlplane is highly available, the loss of any node will cause
neither service disruption nor loss of data.
No writes are even allowed to the vast majority of the filesystem.
We even call the writable partition “ephemeral” to keep this idea always in
focus.
Secure
Talos has always been designed with security in mind.
With its immutability, its minimalism, its signing, and its componenture, we are
able to simply bypass huge classes of vulnerabilities.
Moreover, because of the way we have designed Talos, we are able to take
advantage of a number of additional settings, such as the recommendations of the Kernel Self Protection Project (kspp) and completely disabling dynamic modules.
There are no passwords in Talos.
All networked communication is encrypted and key-authenticated.
The Talos certificates are short-lived and automatically-rotating.
Kubernetes is always constructed with its own separate PKI structure which is
enforced.
Declarative
Everything which can be configured in Talos is done through a single YAML
manifest.
There is no scripting and no procedural steps.
Everything is defined by the one declarative YAML file.
This configuration includes that of both Talos itself and the Kubernetes which
it forms.
This is achievable because Talos is tightly focused to do one thing: run
Kubernetes, in the easiest, most secure, most reliable way it can.
Not based on X distro
Talos Linux isn’t based on any other distribution.
We think of ourselves as being the second-generation of
container-optimised operating systems, where things like CoreOS, Flatcar, and Rancher represent the first generation (but the technology is not derived from any of those.)
Talos Linux is actually a ground-up rewrite of the userspace, from PID 1.
We run the Linux kernel, but everything downstream of that is our own custom
code, written in Go, rigorously-tested, and published as an immutable,
integrated image.
The Linux kernel launches what we call machined, for instance, not systemd.
There is no systemd on our system.
There are no GNU utilities, no shell, no SSH, no packages, nothing you could associate with
any other distribution.
An Operating System designed for Kubernetes
Technically, Talos Linux installs to a computer like any other operating system.
Unlike other operating systems, Talos is not meant to run alone, on a
single machine.
A design goal of Talos Linux is eliminating the management
of individual nodes as much as possible.
In order to do that, Talos Linux operates as a cluster of machines, with lots of
checking and coordination between them, at all levels.
There is only a cluster.
Talos is meant to do one thing: maintain a Kubernetes cluster, and it does this
very, very well.
The entirety of the configuration of any machine is specified by a single
configuration file, which can often be the same configuration file used
across many machines.
Much like a biological system, if some component misbehaves, just cut it out and
let a replacement grow.
Rebuilds of Talos are remarkably fast, whether they be new machines, upgrades,
or reinstalls.
Never get hung up on an individual machine.
6.2 - Architecture
Learn the system architecture of Talos Linux itself.
Talos is designed to be atomic in deployment and modular in composition.
It is atomic in that the entirety of Talos is distributed as a
single, self-contained image, which is versioned, signed, and immutable.
It is modular in that it is composed of many separate components
which have clearly defined gRPC interfaces which facilitate internal flexibility
and external operational guarantees.
All of the main Talos components communicate with each other by gRPC, through a socket on the local machine.
This imposes a clear separation of concerns and ensures that changes over time which affect the interoperation of components are a part of the public git record.
The benefit is that each component may be iterated and changed as its needs dictate, so long as the external API is controlled.
This is a key component in reducing coupling and maintaining modularity.
File system partitions
Talos uses these partitions with the following labels:
EFI - stores EFI boot data.
BIOS - used for GRUB’s second stage boot.
BOOT - used for the boot loader, stores initramfs and kernel data.
META - stores metadata about the talos node, such as node id’s.
STATE - stores machine configuration, node identity data for cluster discovery and KubeSpan info
EPHEMERAL - stores ephemeral state information, mounted at /var
The File System
One of the unique design decisions in Talos is the layout of the root file system.
There are three “layers” to the Talos root file system.
At its core the rootfs is a read-only squashfs.
The squashfs is then mounted as a loop device into memory.
This provides Talos with an immutable base.
The next layer is a set of tmpfs file systems for runtime specific needs.
Aside from the standard pseudo file systems such as /dev, /proc, /run, /sys and /tmp, a special /system is created for internal needs.
One reason for this is that we need special files such as /etc/hosts, and /etc/resolv.conf to be writable (remember that the rootfs is read-only).
For example, at boot Talos will write /system/etc/hosts and then bind mount it over /etc/hosts.
This means that instead of making all of /etc writable, Talos only makes very specific files writable under /etc.
All files under /system are completely recreated on each boot.
For files and directories that need to persist across boots, Talos creates overlayfs file systems.
The /etc/kubernetes is a good example of this.
Directories like this are overlayfs backed by an XFS file system mounted at /var.
The /var directory is owned by Kubernetes with the exception of the above overlayfs file systems.
This directory is writable and used by etcd (in the case of control plane nodes), the kubelet, and the CRI (containerd).
Its content survives machine reboots, but it is wiped and lost on machine upgrades and resets, unless the
--preserve option of talosctl upgrade or the
--system-labels-to-wipe option of talosctl reset
is used.
6.3 - Components
Understand the system components that make up Talos Linux.
In this section, we discuss the various components that underpin Talos.
Components
Talos Linux and Kubernetes are tightly integrated.
In the following, the focus is on the Talos Linux specific components.
Component
Description
apid
When interacting with Talos, the gRPC API endpoint you interact with directly is provided by apid. apid acts as the gateway for all component interactions and forwards the requests to machined.
containerd
An industry-standard container runtime with an emphasis on simplicity, robustness, and portability. To learn more, see the containerd website.
machined
Talos replacement for the traditional Linux init-process. Specially designed to run Kubernetes and does not allow starting arbitrary user services.
kernel
The Linux kernel included with Talos is configured according to the recommendations outlined in the Kernel Self Protection Project.
trustd
To run and operate a Kubernetes cluster, a certain level of trust is required. Based on the concept of a ‘Root of Trust’, trustd is a simple daemon responsible for establishing trust within the system.
udevd
Implementation of eudev into machined. eudev is Gentoo’s fork of udev, systemd’s device file manager for the Linux kernel. It manages device nodes in /dev and handles all user space actions when adding or removing devices. To learn more, see the Gentoo Wiki.
apid
When interacting with Talos, the gRPC api endpoint you will interact with directly is apid.
Apid acts as the gateway for all component interactions.
Apid provides a mechanism to route requests to the appropriate destination when running on a control plane node.
We’ll use some examples below to illustrate what apid is doing.
When a user wants to interact with a Talos component via talosctl, there are two flags that control the interaction with apid.
The -e | --endpoints flag specifies which Talos node ( via apid ) should handle the connection.
Typically this is a public-facing server.
The -n | --nodes flag specifies which Talos node(s) should respond to the request.
If --nodes is omitted, the first endpoint will be used.
Note: Typically, there will be an endpoint already defined in the Talos config file.
Optionally, nodes can be included here as well.
For example, if a user wants to interact with machined, a command like talosctl -e cluster.talos.dev memory may be used.
$ talosctl -e cluster.talos.dev memory
NODE TOTAL USED FREE SHARED BUFFERS CACHE AVAILABLE
cluster.talos.dev 7938176823901455337246571
In this case, talosctl is interacting with apid running on cluster.talos.dev and forwarding the request to the machined api.
If we wanted to extend our example to retrieve memory from another node in our cluster, we could use the command talosctl -e cluster.talos.dev -n node02 memory.
$ talosctl -e cluster.talos.dev -n node02 memory
NODE TOTAL USED FREE SHARED BUFFERS CACHE AVAILABLE
node02 7938176823901455337246571
The apid instance on cluster.talos.dev receives the request and forwards it to apid running on node02, which forwards the request to the machined api.
We can further extend our example to retrieve memory for all nodes in our cluster by appending additional -n node flags or using a comma separated list of nodes ( -n node01,node02,node03 ):
$ talosctl -e cluster.talos.dev -n node01 -n node02 -n node03 memory
NODE TOTAL USED FREE SHARED BUFFERS CACHE AVAILABLE
node01 793887140711374929457042node02 25784414408190796181384952589227492node03 257844183025518612549777254556
The apid instance on cluster.talos.dev receives the request and forwards it to node01, node02, and node03, which then forwards the request to their local machined api.
containerd
Containerd provides the container runtime to launch workloads on Talos and Kubernetes.
Talos services are namespaced under the system namespace in containerd, whereas the Kubernetes services are namespaced under the k8s.io namespace.
machined
A common theme throughout the design of Talos is minimalism.
We believe strongly in the UNIX philosophy that each program should do one job well.
The init included in Talos is one example of this, and we are calling it “machined”.
We wanted to create a focused init that had one job - run Kubernetes.
To that extent, machined is relatively static in that it does not allow for arbitrary user-defined services.
Only the services necessary to run Kubernetes and manage the node are available.
This includes:
The machined process handles all machine configuration, API handling, resource and controller management.
kernel
The Linux kernel included with Talos is configured according to the recommendations outlined in the Kernel Self Protection Project (KSSP).
trustd
Security is one of the highest priorities within Talos.
To run a Kubernetes cluster, a certain level of trust is required to operate a cluster.
For example, orchestrating the bootstrap of a highly available control plane requires sensitive PKI data distribution.
To that end, we created trustd.
Based on a Root of Trust concept, trustd is a simple daemon responsible for establishing trust within the system.
Once trust is established, various methods become available to the trustee.
For example, it can accept a write request from another node to place a file on disk.
Additional methods and capabilities will be added to the trustd component to support new functionality in the rest of the Talos environment.
udevd
Udevd handles the kernel device notifications and sets up the necessary links in /dev.
6.4 - Control Plane
Understand the Kubernetes Control Plane.
This guide provides information about the Kubernetes control plane, and details on how Talos runs and bootstraps the Kubernetes control plane.
What is a control plane node?
A control plane node is a node which:
runs etcd, the Kubernetes database
runs the Kubernetes control plane
kube-apiserver
kube-controller-manager
kube-scheduler
serves as an administrative proxy to the worker nodes
These nodes are critical to the operation of your cluster.
Without control plane nodes, Kubernetes will not respond to changes in the
system, and certain central services may not be available.
Talos nodes which have .machine.type of controlplane are control plane nodes.
(check via talosctl get member)
Control plane nodes are tainted by default to prevent workloads from being scheduled onto them.
This is both to protect the control plane from workloads consuming resources and starving the control plane processes, and also to reduce the risk of a vulnerability exposes the control plane’s credentials to a workload.
The Control Plane and Etcd
A critical design concept of Kubernetes (and Talos) is the etcd database.
Properly managed (which Talos Linux does), etcd should never have split brain or noticeable down time.
In order to do this, etcd maintains the concept of “membership” and of
“quorum”.
To perform any operation, read or write, the database requires
quorum.
That is, a majority of members must agree on the current leader, and absenteeism (members that are down, or not reachable)
counts as a negative.
For example, if there are three members, at least two out
of the three must agree on the current leader.
If two disagree or fail to answer, the etcd database will lock itself
until quorum is achieved in order to protect the integrity of
the data.
This design means that having two controlplane nodes is worse than having only one, because if either goes down, your database will lock (and the chance of one of two nodes going down is greater than the chance of just a single node going down).
Similarly, a 4 node etcd cluster is worse than a 3 node etcd cluster - a 4 node cluster requires 3 nodes to be up to achieve quorum (in order to have a majority), while the 3 node cluster requires 2 nodes:
i.e. both can support a single node failure and keep running - but the chance of a node failing in a 4 node cluster is higher than that in a 3 node cluster.
Another note about etcd: due to the need to replicate data amongst members, performance of etcd decreases as the cluster scales.
A 5 node cluster can commit about 5% less writes per second than a 3 node cluster running on the same hardware.
Recommendations for your control plane
Run your clusters with three or five control plane nodes.
Three is enough for most use cases.
Five will give you better availability (in that it can tolerate two node failures simultaneously), but cost you more both in the number of nodes required, and also as each node may require more hardware resources to offset the performance degradation seen in larger clusters.
Implement good monitoring and put processes in place to deal with a failed node in a timely manner (and test them!)
Even with robust monitoring and procedures for replacing failed nodes in place, backup etcd and your control plane node configuration to guard against unforeseen disasters.
Monitor the performance of your etcd clusters.
If etcd performance is slow, vertically scale the nodes, not the number of nodes.
If a control plane node fails, remove it first, then add the replacement node.
(This ensures that the failed node does not “vote” when adding in the new node, minimizing the chances of a quorum violation.)
If replacing a node that has not failed, add the new one, then remove the old.
Bootstrapping the Control Plane
Every new cluster must be bootstrapped only once, which is achieved by telling a single control plane node to initiate the bootstrap.
Bootstrapping itself does not do anything with Kubernetes.
Bootstrapping only tells etcd to form a cluster, so don’t judge the success of
a bootstrap by the failure of Kubernetes to start.
Kubernetes relies on etcd, so bootstrapping is required, but it is not
sufficient for Kubernetes to start.
If your Kubernetes cluster fails to form for other reasons (say, a bad
configuration option or unavailable container repository), if the bootstrap API
call returns successfully, you do NOT need to bootstrap again:
just fix the config or let Kubernetes retry.
High-level Overview
Talos cluster bootstrap flow:
The etcd service is started on control plane nodes.
Instances of etcd on control plane nodes build the etcd cluster.
The kubelet service is started.
Control plane components are started as static pods via the kubelet, and the kube-apiserver component connects to the local (running on the same node) etcd instance.
The kubelet issues client certificate using the bootstrap token using the control plane endpoint (via kube-apiserver and kube-controller-manager).
The kubelet registers the node in the API server.
Kubernetes control plane schedules pods on the nodes.
Cluster Bootstrapping
All nodes start the kubelet service.
The kubelet tries to contact the control plane endpoint, but as it is not up yet, it keeps retrying.
One of the control plane nodes is chosen as the bootstrap node, and promoted using the bootstrap API (talosctl bootstrap).
The bootstrap node initiates the etcd bootstrap process by initializing etcd as the first member of the cluster.
Once etcd is bootstrapped, the bootstrap node has no special role and acts the same way as other control plane nodes.
Services etcd on non-bootstrap nodes try to get Endpoints resource via control plane endpoint, but that request fails as control plane endpoint is not up yet.
As soon as etcd is up on the bootstrap node, static pod definitions for the Kubernetes control plane components (kube-apiserver, kube-controller-manager, kube-scheduler) are rendered to disk.
The kubelet service on the bootstrap node picks up the static pod definitions and starts the Kubernetes control plane components.
As soon as kube-apiserver is launched, the control plane endpoint comes up.
The bootstrap node acquires an etcd mutex and injects the bootstrap manifests into the API server.
The set of the bootstrap manifests specify the Kubernetes join token and kubelet CSR auto-approval.
The kubelet service on all the nodes is now able to issue client certificates for themselves and register nodes in the API server.
Other bootstrap manifests specify additional resources critical for Kubernetes operations (i.e. CNI, PSP, etc.)
The etcd service on non-bootstrap nodes is now able to discover other members of the etcd cluster via the Kubernetes Endpoints resource.
The etcd cluster is now formed and consists of all control plane nodes.
All control plane nodes render static pod manifests for the control plane components.
Each node now runs a full set of components to make the control plane HA.
The kubelet service on worker nodes is now able to issue the client certificate and register itself with the API server.
Scaling Up the Control Plane
When new nodes are added to the control plane, the process is the same as the bootstrap process above: the etcd service discovers existing members of the control plane via the
control plane endpoint, joins the etcd cluster, and the control plane components are scheduled on the node.
Scaling Down the Control Plane
Scaling down the control plane involves removing a node from the cluster.
The most critical part is making sure that the node which is being removed leaves the etcd cluster.
The recommended way to do this is to use:
talosctl -n IP.of.node.to.remove reset
kubectl delete node
When using talosctl reset command, the targeted control plane node leaves the etcd cluster as part of the reset sequence, and its disks are erased.
Upgrading Talos on Control Plane Nodes
When a control plane node is upgraded, Talos leaves etcd, wipes the system disk, installs a new version of itself, and reboots.
The upgraded node then joins the etcd cluster on reboot.
So upgrading a control plane node is equivalent to scaling down the control plane node followed by scaling up with a new version of Talos.
6.5 - Controllers and Resources
Discover how Talos Linux uses the concepts on Controllers and Resources.
Talos implements concepts of resources and controllers to facilitate internal operations of the operating system.
Talos resources and controllers are very similar to Kubernetes resources and controllers, but there are some differences.
The content of this document is not required to operate Talos, but it is useful for troubleshooting.
Starting with Talos 0.9, most of the Kubernetes control plane bootstrapping and operations is implemented via controllers and resources which allows Talos to be reactive to configuration changes, environment changes (e.g. time sync).
Resources
A resource captures a piece of system state.
Each resource belongs to a “Type” which defines resource contents.
Resource state can be split in two parts:
metadata: fixed set of fields describing resource - namespace, type, ID, etc.
spec: contents of the resource (depends on resource type).
Resource is uniquely identified by (namespace, type, id).
Namespaces provide a way to avoid conflicts on duplicate resource IDs.
At the moment of this writing, all resources are local to the node and stored in memory.
So on every reboot resource state is rebuilt from scratch (the only exception is MachineConfig resource which reflects current machine config).
Controllers
Controllers run as independent lightweight threads in Talos.
The goal of the controller is to reconcile the state based on inputs and eventually update outputs.
A controller can have any number of resource types (and namespaces) as inputs.
In other words, it watches specified resources for changes and reconciles when these changes occur.
A controller might also have additional inputs: running reconcile on schedule, watching etcd keys, etc.
A controller has a single output: a set of resources of fixed type in a fixed namespace.
Only one controller can manage resource type in the namespace, so conflicts are avoided.
Querying Resources
Talos CLI tool talosctl provides read-only access to the resource API which includes getting specific resource,
listing resources and watching for changes.
Talos stores resources describing resource types and namespaces in meta namespace:
$ talosctl get resourcedefinitions
NODE NAMESPACE TYPE ID VERSION
172.20.0.2 meta ResourceDefinition bootstrapstatuses.v1alpha1.talos.dev 1172.20.0.2 meta ResourceDefinition etcdsecrets.secrets.talos.dev 1172.20.0.2 meta ResourceDefinition kubernetescontrolplaneconfigs.config.talos.dev 1172.20.0.2 meta ResourceDefinition kubernetessecrets.secrets.talos.dev 1172.20.0.2 meta ResourceDefinition machineconfigs.config.talos.dev 1172.20.0.2 meta ResourceDefinition machinetypes.config.talos.dev 1172.20.0.2 meta ResourceDefinition manifests.kubernetes.talos.dev 1172.20.0.2 meta ResourceDefinition manifeststatuses.kubernetes.talos.dev 1172.20.0.2 meta ResourceDefinition namespaces.meta.cosi.dev 1172.20.0.2 meta ResourceDefinition resourcedefinitions.meta.cosi.dev 1172.20.0.2 meta ResourceDefinition rootsecrets.secrets.talos.dev 1172.20.0.2 meta ResourceDefinition secretstatuses.kubernetes.talos.dev 1172.20.0.2 meta ResourceDefinition services.v1alpha1.talos.dev 1172.20.0.2 meta ResourceDefinition staticpods.kubernetes.talos.dev 1172.20.0.2 meta ResourceDefinition staticpodstatuses.kubernetes.talos.dev 1172.20.0.2 meta ResourceDefinition timestatuses.v1alpha1.talos.dev 1
$ talosctl get namespaces
NODE NAMESPACE TYPE ID VERSION
172.20.0.2 meta Namespace config 1172.20.0.2 meta Namespace controlplane 1172.20.0.2 meta Namespace meta 1172.20.0.2 meta Namespace runtime 1172.20.0.2 meta Namespace secrets 1
Most of the time namespace flag (--namespace) can be omitted, as ResourceDefinition contains default
namespace which is used if no namespace is given:
Resource definition also contains type aliases which can be used interchangeably with canonical resource name:
$ talosctl get ns config
NODE NAMESPACE TYPE ID VERSION
172.20.0.2 meta Namespace config 1
Output
Command talosctl get supports following output modes:
table (default) prints resource list as a table
yaml prints pretty formatted resources with details, including full metadata spec.
This format carries most details from the backend resource (e.g. comments in MachineConfig resource)
json prints same information as yaml, some additional details (e.g. comments) might be lost.
This format is useful for automated processing with tools like jq.
Watching Changes
If flag --watch is appended to the talosctl get command, the command switches to watch mode.
If list of resources was requested, talosctl prints initial contents of the list and then appends resource information for every change:
$ talosctl get svc -w
NODE * NAMESPACE TYPE ID VERSION RUNNING HEALTHY
172.20.0.2 + runtime Service timed 2truetrue172.20.0.2 + runtime Service trustd 2truetrue172.20.0.2 + runtime Service udevd 2truetrue172.20.0.2 - runtime Service timed 2truetrue172.20.0.2 + runtime Service timed 1truefalse172.20.0.2 runtime Service timed 2truetrue
Column * specifies event type:
+ is created
- is deleted
is updated
In YAML/JSON output, field event is added to the resource representation to describe the event type.
Examples
Getting machine config:
$ talosctl get machineconfig -o yaml
node: 172.20.0.2
metadata:
namespace: config
type: MachineConfigs.config.talos.dev
id: v1alpha1
version: 2 phase: running
spec:
version: v1alpha1 # Indicates the schema used to decode the contents. debug: false# Enable verbose logging to the console. persist: true# Indicates whether to pull the machine config upon every boot.# Provides machine specific configuration options....
Getting control plane static pod statuses:
$ talosctl get staticpodstatus
NODE NAMESPACE TYPE ID VERSION READY
172.20.0.2 controlplane StaticPodStatus kube-system/kube-apiserver-talos-default-controlplane-1 3 True
172.20.0.2 controlplane StaticPodStatus kube-system/kube-controller-manager-talos-default-controlplane-1 3 True
172.20.0.2 controlplane StaticPodStatus kube-system/kube-scheduler-talos-default-controlplane-1 4 True
Talos network configuration subsystem is powered by COSI.
Talos translates network configuration from multiple sources: machine configuration, cloud metadata, network automatic configuration (e.g. DHCP) into COSI resources.
Network configuration and network state can be inspected using talosctl get command.
Network machine configuration can be modified using talosctl edit mc command (also variants talosctl patch mc, talosctl apply-config) without a reboot.
As API access requires network connection, --mode=try
can be used to test the configuration with automatic rollback to avoid losing network access to the node.
Resources
There are six basic network configuration items in Talos:
Address (IP address assigned to the interface/link);
Route (route to a destination);
Link (network interface/link configuration);
Resolver (list of DNS servers);
Hostname (node hostname and domainname);
TimeServer (list of NTP servers).
Each network configuration item has two counterparts:
*Status (e.g. LinkStatus) describes the current state of the system (Linux kernel state);
*Spec (e.g. LinkSpec) defines the desired configuration.
Resource
Status
Spec
Address
AddressStatus
AddressSpec
Route
RouteStatus
RouteSpec
Link
LinkStatus
LinkSpec
Resolver
ResolverStatus
ResolverSpec
Hostname
HostnameStatus
HostnameSpec
TimeServer
TimeServerStatus
TimeServerSpec
Status resources have aliases with the Status suffix removed, so for example
AddressStatus is also available as Address.
Talos networking controllers reconcile the state so that *Status equals the desired *Spec.
Observing State
The current network configuration state can be observed by querying *Status resources via
talosctl:
$ talosctl get addresses
NODE NAMESPACE TYPE ID VERSION ADDRESS LINK
172.20.0.2 network AddressStatus eth0/172.20.0.2/24 1 172.20.0.2/24 eth0
172.20.0.2 network AddressStatus eth0/fe80::9804:17ff:fe9d:3058/64 2 fe80::9804:17ff:fe9d:3058/64 eth0
172.20.0.2 network AddressStatus flannel.1/10.244.4.0/32 1 10.244.4.0/32 flannel.1
172.20.0.2 network AddressStatus flannel.1/fe80::10b5:44ff:fe62:6fb8/64 2 fe80::10b5:44ff:fe62:6fb8/64 flannel.1
172.20.0.2 network AddressStatus lo/127.0.0.1/8 1 127.0.0.1/8 lo
172.20.0.2 network AddressStatus lo/::1/128 1 ::1/128 lo
In the output there are addresses set up by Talos (e.g. eth0/172.20.0.2/24) and
addresses set up by other facilities (e.g. flannel.1/10.244.4.0/32 set up by CNI).
Talos networking controllers watch the kernel state and update resources
accordingly.
Additional details about the address can be accessed via the YAML output:
The desired networking configuration is combined from multiple sources and presented
as *Spec resources:
$ talosctl get addressspecs
NODE NAMESPACE TYPE ID VERSION
172.20.0.2 network AddressSpec eth0/172.20.0.2/24 2172.20.0.2 network AddressSpec lo/127.0.0.1/8 2172.20.0.2 network AddressSpec lo/::1/128 2
These AddressSpecs are applied to the Linux kernel to reach the desired state.
If, for example, an AddressSpec is removed, the address is removed from the Linux network interface as well.
*Spec resources can’t be manipulated directly, they are generated automatically by Talos
from multiple configuration sources (see a section below for details).
If a *Spec resource is queried in YAML format, some additional information is available:
An important field is the layer field, which describes a configuration layer this spec is coming from: in this case, it’s generated by a network operator (see below) and is set by the DHCPv4 operator.
Configuration Merging
Spec resources described in the previous section show the final merged configuration state,
while initial specs are put to a different unmerged namespace network-config.
Spec resources in the network-config namespace are merged with conflict resolution to produce the final merged representation in the network namespace.
Let’s take HostnameSpec as an example.
The final merged representation is:
We can see that the final configuration for the hostname is talos-default-controlplane-1.
And this is the hostname that was actually applied.
This can be verified by querying a HostnameStatus resource:
$ talosctl get hostnamestatus
NODE NAMESPACE TYPE ID VERSION HOSTNAME DOMAINNAME
172.20.0.2 network HostnameStatus hostname 1 talos-default-controlplane-1
Initial configuration for the hostname in the network-config namespace is:
We can see that there are two specs for the hostname:
one from the default configuration layer which defines the hostname as talos-172-20-0-2 (default driven by the default node address);
another one from the layer operator that defines the hostname as talos-default-controlplane-1 (DHCP).
Talos merges these two specs into a final HostnameSpec based on the configuration layer and merge rules.
Here is the order of precedence from low to high:
configuration (derived from the machine configuration).
So in our example the operator layer HostnameSpec overrides the default layer producing the final hostname talos-default-controlplane-1.
The merge process applies to all six core networking specs.
For each spec, the layer controls the merge behavior
If multiple configuration specs
appear at the same layer, they can be merged together if possible, otherwise merge result
is stable but not defined (e.g. if DHCP on multiple interfaces provides two different hostnames for the node).
LinkSpecs are merged across layers, so for example, machine configuration for the interface MTU overrides an MTU set by the DHCP server.
Network Operators
Network operators provide dynamic network configuration which can change over time as the node is running:
DHCPv4
DHCPv6
Virtual IP
Network operators produce specs for addresses, routes, links, etc., which are then merged and applied according to the rules described above.
Operators are configured with OperatorSpec resources which describe when operators
should run and additional configuration for the operator:
OperatorSpec resources are generated by Talos based on machine configuration mostly.
DHCP4 operator is created automatically for all physical network links which are not configured explicitly via the kernel command line or the machine configuration.
This also means that on the first boot, without a machine configuration, a DHCP request is made on all physical network interfaces by default.
Specs generated by operators are prefixed with the operator ID (dhcp4/eth0 in the example above) in the unmerged network-config namespace:
$ talosctl -n 172.20.0.2 get addressspecs --namespace network-config
NODE NAMESPACE TYPE ID VERSION
172.20.0.2 network-config AddressSpec dhcp4/eth0/eth0/172.20.0.2/24 1
Other Network Resources
There are some additional resources describing the network subsystem state.
The NodeAddress resource presents node addresses excluding link-local and loopback addresses:
$ talosctl get nodeaddresses
NODE NAMESPACE TYPE ID VERSION ADDRESSES
10.100.2.23 network NodeAddress accumulative 6["10.100.2.23","147.75.98.173","147.75.195.143","192.168.95.64","2604:1380:1:ca00::17"]10.100.2.23 network NodeAddress current 5["10.100.2.23","147.75.98.173","192.168.95.64","2604:1380:1:ca00::17"]10.100.2.23 network NodeAddress default 1["10.100.2.23"]
default is the node default address;
current is the set of addresses a node currently has;
accumulative is the set of addresses a node had over time (it might include virtual IPs which are not owned by the node at the moment).
NodeAddress resources are used to pick up the default address for etcd peer URL, to populate SANs field in the generated certificates, etc.
Another important resource is Nodename which provides Node name in Kubernetes:
$ talosctl get nodename
NODE NAMESPACE TYPE ID VERSION NODENAME
10.100.2.23 controlplane Nodename nodename 1 infra-green-cp-mmf7v
Depending on the machine configuration nodename might be just a hostname or the FQDN of the node.
NetworkStatus aggregates the current state of the network configuration:
For each of the six basic resource types, there are several controllers:
*StatusController populates *Status resources observing the Linux kernel state.
*ConfigController produces the initial unmerged *Spec resources in the network-config namespace based on defaults, kernel command line, and machine configuration.
*MergeController merges *Spec resources into the final representation in the network namespace.
*SpecController applies merged *Spec resources to the kernel state.
For the network operators:
OperatorConfigController produces OperatorSpec resources based on machine configuration and deafauls.
OperatorSpecController runs network operators watching OperatorSpec resources and producing various *Spec resources in the network-config namespace.
Configuration Sources
There are several configuration sources for the network configuration, which are described in this section.
Defaults
lo interface is assigned addresses 127.0.0.1/8 and ::1/128;
hostname is set to the talos-<IP> where IP is the default node address;
resolvers are set to 8.8.8.8, 1.1.1.1;
time servers are set to pool.ntp.org;
DHCP4 operator is run on any physical interface which is not configured explicitly.
Cmdline
The kernel command line is parsed for the following options:
ip= option is parsed for node IP, default gateway, hostname, DNS servers, NTP servers;
bond= option is parsed for bonding interfaces and their options;
talos.hostname= option is used to set node hostname;
talos.network.interface.ignore= can be used to make Talos skip network interface configuration completely.
Platform
Platform configuration delivers cloud environment-specific options (e.g. the hostname).
Platform configuration is specific to the environment metadata: for example, on Equinix Metal, Talos automatically
configures public and private IPs, routing, link bonding, hostname.
Platform configuration is cached across reboots in /system/state/platform-network.yaml.
Operator
Network operators provide configuration for all basic resource types.
Machine Configuration
The machine configuration is parsed for link configuration, addresses, routes, hostname,
resolvers and time servers.
Any changes to .machine.network configuration can be applied in immediate mode.
Network Configuration Debugging
Most of the network controller operations and failures are logged to the kernel console,
additional logs with debug level are available with talosctl logs controller-runtime command.
If the network configuration can’t be established and the API is not available, debug level
logs can be sent to the console with debug: true option in the machine configuration.
6.7 - Network Connectivity
Description of the Networking Connectivity needed by Talos Linux
Configuring Network Connectivity
The simplest way to deploy Talos is by ensuring that all the remote components of the system (talosctl, the control plane nodes, and worker nodes) all have layer 2 connectivity.
This is not always possible, however, so this page lays out the minimal network access that is required to configure and operate a talos cluster.
Note: These are the ports required for Talos specifically, and should be configured in addition to the ports required by kubernetes.
See the kubernetes docs for information on the ports used by kubernetes itself.
Ports marked with a * are not currently configurable, but that may change in the future.
Follow along here.
6.8 - KubeSpan
Understand more about KubeSpan for Talos Linux.
WireGuard Peer Discovery
The key pieces of information needed for WireGuard generally are:
the public key of the host you wish to connect to
an IP address and port of the host you wish to connect to
The latter is really only required of one side of the pair.
Once traffic is received, that information is known and updated by WireGuard automatically and internally.
For Kubernetes, though, this is not quite sufficient.
Kubernetes also needs to know which traffic goes to which WireGuard peer.
Because this information may be dynamic, we need a way to be able to constantly keep this information up to date.
If we have a functional connection to Kubernetes otherwise, it’s fairly easy: we can just keep that information in Kubernetes.
Otherwise, we have to have some way to discover it.
In our solution, we have a multi-tiered approach to gathering this information.
Each tier can operate independently, but the amalgamation of the tiers produces a more robust set of connection criteria.
For this discussion, we will point out two of these tiers:
The Kubernetes-based system utilises annotations on Kubernetes Nodes which describe each node’s public key and local addresses.
On top of this, we also optionally route Pod subnets.
This is often (maybe even usually) taken care of by the CNI, but there are many situations where the CNI fails to be able to do this itself, across networks.
NAT, Multiple Routes, Multiple IPs
One of the difficulties in communicating across networks is that there is often not a single address and port which can identify a connection for each node on the system.
For instance, a node sitting on the same network might see its peer as 192.168.2.10, but a node across the internet may see it as 2001:db8:1ef1::10.
We need to be able to handle any number of addresses and ports, and we also need to have a mechanism to try them.
WireGuard only allows us to select one at a time.
For our implementation, then, we have built a controller which continuously discovers and rotates these IP:port pairs until a connection is established.
It then starts trying again if that connection ever fails.
Packet Routing
After we have established a WireGuard connection, our work is not done.
We still have to make sure that the right packets get sent to the WireGuard interface.
WireGuard supplies a convenient facility for tagging packets which come from it, which is great.
But in our case, we need to be able to allow traffic which both does not come from WireGuard and also is not destined for another Kubernetes node to flow through the normal mechanisms.
Unlike many corporate or privacy-oriented VPNs, we need to allow general internet traffic to flow normally.
Also, as our cluster grows, this set of IP addresses can become quite large and quite dynamic.
This would be very cumbersome and slow in iptables.
Luckily, the kernel supplies a convenient mechanism by which to define this arbitrarily large set of IP addresses: IP sets.
Talos collects all of the IPs and subnets which are considered “in-cluster” and maintains these in the kernel as an IP set.
Now that we have the IP set defined, we need to tell the kernel how to use it.
The traditional way of doing this would be to use iptables.
However, there is a big problem with IPTables.
It is a common namespace in which any number of other pieces of software may dump things.
We have no surety that what we add will not be wiped out by something else (from Kubernetes itself, to the CNI, to some workload application), be rendered unusable by higher-priority rules, or just generally cause trouble and conflicts.
Instead, we use a three-pronged system which is both more foundational and less centralised.
NFTables offers a separately namespaced, decentralised way of marking packets for later processing based on IP sets.
Instead of a common set of well-known tables, NFTables uses hooks into the kernel’s netfilter system, which are less vulnerable to being usurped, bypassed, or a source of interference than IPTables, but which are rendered down by the kernel to the same underlying XTables system.
Our NFTables system is where we store the IP sets.
Any packet which enters the system, either by forward from inside Kubernetes or by generation from the host itself, is compared against a hash table of this IP set.
If it is matched, it is marked for later processing by our next stage.
This is a high-performance system which exists fully in the kernel and which ultimately becomes an eBPF program, so it scales well to hundreds of nodes.
The next stage is the kernel router’s route rules.
These are defined as a common ordered list of operations for the whole operating system, but they are intended to be tightly constrained and are rarely used by applications in any case.
The rules we add are very simple: if a packet is marked by our NFTables system, send it to an alternate routing table.
This leads us to our third and final stage of packet routing.
We have a custom routing table with two rules:
send all IPv4 traffic to the WireGuard interface
send all IPv6 traffic to the WireGuard interface
So in summary, we:
mark packets destined for Kubernetes applications or Kubernetes nodes
send marked packets to a special routing table
send anything which is sent to that routing table through the WireGuard interface
This gives us an isolated, resilient, tolerant, and non-invasive way to route Kubernetes traffic safely, automatically, and transparently through WireGuard across almost any set of network topologies.
Design Decisions
Routing
Routing for Wireguard is a touch complicated when the set of possible peer
endpoints includes at least one member of the set of destinations.
That is, packets from Wireguard to a peer endpoint should not be sent to
Wireguard, lest a loop be created.
In order to handle this situation, Wireguard provides the ability to mark
packets which it generates, so their routing can be handled separately.
In our case, though, we actually want the inverse of this: we want to route
Wireguard packets however the normal networking routes and rules say they should
be routed, while packets destined for the other side of Wireguard Peers should
be forced into Wireguard interfaces.
While IP Rules allow you to invert matches, they do not support matching based
on IP sets.
That means, to use simple rules, we would have to add a rule for
each destination, which could reach into hundreds or thousands of rules to
manage.
This is not really much of a performance issue, but it is a management
issue, since it is expected that we would not be the only manager of rules in
the system, and rules offer no facility to tag for ownership.
IP Sets are supported by IPTables, and we could integrate there.
However, IPTables exists in a global namespace, which makes it fragile having
multiple parties manipulating it.
The newer NFTables replacement for IPTables, though, allows users to
independently hook into various points of XTables, keeping all such rules and
sets independent.
This means that regardless of what CNIs or other user-side routing rules may do,
our KubeSpan setup will not be messed up.
Therefore, we utilise NFTables (which natively supports IP sets and owner
grouping) instead, to mark matching traffic which should be sent to the
Wireguard interface.
This way, we can keep all our KubeSpan set logic in one place, allowing us to
simply use a single ip rule match:
for our fwmark, and sending those matched packets to a separate routing table
with one rule: default to the wireguard interface.
So we have three components:
A routing table for Wireguard-destined packets
An NFTables table which defines the set of destinations packets to which will
be marked with our firewall mark.
Hook into PreRouting (type Filter)
Hook into Outgoing (type Route)
One IP Rule which sends packets marked with our firewall mark to our Wireguard
routing table.
Routing Table
The routing table (number 180 by default) is simple, containing a single route for each family: send everything through the Wireguard interface.
NFTables
The logic inside NFTables is fairly simple.
First, everything is compiled into a single table: talos_kubespan.
Next, two chains are set up: one for the prerouting hook (kubespan_prerouting)
and the other for the outgoing hook (kubespan_outgoing).
We define two sets of target IP prefixes: one for IPv6 (kubespan_targets_ipv6)
and the other for IPv4 (kubespan_targets_ipv4).
Last, we add rules to each chain which basically specify:
If the packet is marked as from Wireguard, just accept it and terminate
the chain.
If the packet matches an IP in either of the target IP sets, mark that
packet with the to Wireguard mark.
Rules
There are two route rules defined: one to match IPv6 packets and the other to
match IPv4 packets.
These rules say the same thing for each: if the packet is marked that it should
go to Wireguard, send it to the Wireguard
routing table.
Firewall Mark
KubeSpan is using only two bits of the firewall mark with the mask 0x00000060.
Note: if other software on the node is using the bits 0x60 of the firewall mark, this
might cause conflicts and break KubeSpan.
At the moment of the writing, it was confirmed that Calico CNI is using bits 0xffff0000 and
Cilium CNI is using bits 0xf00, so KubeSpan is compatible with both.
Flannel CNI uses 0x4000 mask, so it is also compatible.
In the routing rules table, we match on the mark 0x40 with the mask 0x60:
32500: from all fwmark 0x40/0x60 lookup 180
In the NFTables table, we match with the same mask 0x60 and we set the mask by only modifying
bits from the 0x60 mask:
meta mark & 0x00000060 == 0x00000020 accept
ip daddr @kubespan_targets_ipv4 meta mark set meta mark & 0xffffffdf | 0x00000040 accept
ip6 daddr @kubespan_targets_ipv6 meta mark set meta mark & 0xffffffdf | 0x00000040 accept
6.9 - Process Capabilities
Understand the Linux process capabilities restrictions with Talos Linux.
Linux defines a set of process capabilities that can be used to fine-tune the process permissions.
Talos Linux for security reasons restricts any process from gaining the following capabilities:
CAP_SYS_MODULE (loading kernel modules)
CAP_SYS_BOOT (rebooting the system)
This means that any process including privileged Kubernetes pods will not be able to get these capabilities.
If you see the following error on starting a pod, make sure it doesn’t have any of the capabilities listed above in the spec:
Error: failed to create containerd task: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: unable to apply caps: operation not permitted: unknown
Note: even with CAP_SYS_MODULE capability, Linux kernel module loading is restricted by requiring a valid signature.
Talos Linux creates a throw away signing key during kernel build, so it’s not possible to build/sign a kernel module for Talos Linux outside of the build process.
6.10 - talosctl
The design and use of the Talos Linux control application.
The talosctl tool acts as a reference implementation for the Talos API, but it also handles a lot of
conveniences for the use of Talos and its clusters.
Video Walkthrough
To see some live examples of talosctl usage, view the following video:
Client Configuration
Talosctl configuration is located in $XDG_CONFIG_HOME/talos/config.yaml if $XDG_CONFIG_HOME is defined.
Otherwise it is in $HOME/.talos/config.
The location can always be overridden by the TALOSCONFIG environment variable or the --talosconfig parameter.
Like kubectl, talosctl uses the concept of configuration contexts, so any number of Talos clusters can be managed with a single configuration file.
It also comes with some intelligent tooling to manage the merging of new contexts into the config.
The default operation is a non-destructive merge, where if a context of the same name already exists in the file, the context to be added is renamed by appending an index number.
You can easily overwrite instead, as well.
See the talosctl config help for more information.
Endpoints and Nodes
endpoints are the communication endpoints to which the client directly talks.
These can be load balancers, DNS hostnames, a list of IPs, etc.
If multiple endpoints are specified, the client will automatically load
balance and fail over between them.
It is recommended that these point to the set of control plane nodes, either directly or through a load balancer.
Each endpoint will automatically proxy requests destined to another node through it, so it is not necessary to change the endpoint configuration just because you wish to talk to a different node within the cluster.
Endpoints do, however, need to be members of the same Talos cluster as the target node, because these proxied connections reply on certificate-based authentication.
The node is the target node on which you wish to perform the API call.
While you can configure the target node (or even set of target nodes) inside the ’talosctl’ configuration file, it is recommended not to do so, but to explicitly declare the target node(s) using the -n or --nodes command-line parameter.
When specifying nodes, their IPs and/or hostnames are as seen by the endpoint servers, not as from the client.
This is because all connections are proxied first through the endpoints.
Kubeconfig
The configuration for accessing a Talos Kubernetes cluster is obtained with talosctl.
By default, talosctl will safely merge the cluster into the default kubeconfig.
Like talosctl itself, in the event of a naming conflict, the new context name will be index-appended before insertion.
The --force option can be used to overwrite instead.
You can also specify an alternate path by supplying it as a positional parameter.
Thus, like Talos clusters themselves, talosctl makes it easy to manage any
number of kubernetes clusters from the same workstation.
Commands
Please see the CLI reference for the entire list of commands which are available from talosctl.
6.11 - FAQs
Frequently Asked Questions about Talos Linux.
How is Talos different from other container optimized Linux distros?
Talos shares a lot of attributes with other distros, but there are some important differences.
Talos integrates tightly with Kubernetes, and is not meant to be a general-purpose operating system.
The most important difference is that Talos is fully controlled by an API via a gRPC interface, instead of an ordinary shell.
We don’t ship SSH, and there is no console access.
Removing components such as these has allowed us to dramatically reduce the footprint of Talos, and in turn, improve a number of other areas like security, predictability, reliability, and consistency across platforms.
It’s a big change from how operating systems have been managed in the past, but we believe that API-driven OSes are the future.
Why no shell or SSH?
Since Talos is fully API-driven, all maintenance and debugging operations should be possible via the OS API.
We would like for Talos users to start thinking about what a “machine” is in the context of a Kubernetes cluster.
That is, that a Kubernetes cluster can be thought of as one massive machine, and the nodes are merely additional, undifferentiated resources.
We don’t want humans to focus on the nodes, but rather on the machine that is the Kubernetes cluster.
Should an issue arise at the node level, talosctl should provide the necessary tooling to assist in the identification, debugging, and remediation of the issue.
However, the API is based on the Principle of Least Privilege, and exposes only a limited set of methods.
We envision Talos being a great place for the application of control theory in order to provide a self-healing platform.
Why the name “Talos”?
Talos was an automaton created by the Greek God of the forge to protect the island of Crete.
He would patrol the coast and enforce laws throughout the land.
We felt it was a fitting name for a security focused operating system designed to run Kubernetes.
Why does Talos rely on a separate configuration from Kubernetes?
The talosconfig file contains client credentials to access the Talos Linux API.
Sometimes Kubernetes might be down for a number of reasons (etcd issues, misconfiguration, etc.), while Talos API access will always be available.
The Talos API is a way to access the operating system and fix issues, e.g. fixing access to Kubernetes.
When Talos Linux is running fine, using the Kubernetes APIs (via kubeconfig) is all you should need to deploy and manage Kubernetes workloads.
6.12 - Knowledge Base
Recipes for common configuration tasks with Talos Linux.
Generating Talos Linux ISO image with custom kernel arguments
Pass additional kernel arguments using --extra-kernel-arg flag:
$ docker run --rm -i ghcr.io/siderolabs/imager:v1.4.8 iso --arch amd64 --tar-to-stdout --extra-kernel-arg console=ttyS1 --extra-kernel-arg console=tty0 | tar xz
2022/05/25 13:18:47 copying /usr/install/amd64/vmlinuz to /mnt/boot/vmlinuz
2022/05/25 13:18:47 copying /usr/install/amd64/initramfs.xz to /mnt/boot/initramfs.xz
2022/05/25 13:18:47 creating grub.cfg
2022/05/25 13:18:47 creating ISO
ISO will be output to the file talos-<arch>.iso in the current directory.
Logging Kubernetes audit logs with loki
If using loki-stack helm chart to gather logs from the Kubernetes cluster, you can use the helm values to configure loki-stack to log Kubernetes API server audit logs:
promtail:
extraArgs:
- -config.expand-env
# this is required so that the promtail process can read the kube-apiserver audit logs written as `nobody` usercontainerSecurityContext:
capabilities:
add:
- DAC_READ_SEARCH
extraVolumes:
- name: audit-logs
hostPath:
path: /var/log/audit/kube
extraVolumeMounts:
- name: audit-logs
mountPath: /var/log/audit/kube
readOnly: trueconfig:
snippets:
extraScrapeConfigs: | - job_name: auditlogs
static_configs:
- targets:
- localhost
labels:
job: auditlogs
host: ${HOSTNAME}
__path__: /var/log/audit/kube/*.log
Setting CPU scaling governor
While its possible to set CPU scaling governor via .machine.sysfs it’s sometimes cumbersome to set it for all CPU’s individually.
A more elegant approach would be set it via a kernel commandline parameter.
This also means that the options are applied way early in the boot process.
This can be set in the machineconfig via the snippet below: