This is the multi-page printable view of this section. Click here to print.
Configuration
- 1: Configuration Patches
- 2: Containerd
- 3: Custom Certificate Authorities
- 4: Disk Encryption
- 5: Editing Machine Configuration
- 6: Logging
- 7: NVIDIA Fabric Manager
- 8: NVIDIA GPU (OSS drivers)
- 9: NVIDIA GPU (Proprietary drivers)
- 10: Pull Through Image Cache
- 11: Role-based access control (RBAC)
- 12: System Extensions
- 13: Time Synchronization
1 - Configuration Patches
Talos generates machine configuration for two types of machines: controlplane and worker machines.
Many configuration options can be adjusted using talosctl gen config but not all of them.
Configuration patching allows modifying machine configuration to fit it for the cluster or a specific machine.
Configuration Patch Formats
Talos supports two configuration patch formats:
- strategic merge patches
- RFC6902 (JSON patches)
Strategic merge patches are the easiest to use, but JSON patches allow more precise configuration adjustments.
Note: Talos 1.5+ supports multi-document machine configuration. JSON patches don’t support multi-document machine configuration, while strategic merge patches do.
Strategic Merge patches
Strategic merge patches look like incomplete machine configuration files:
machine:
network:
hostname: worker1
When applied to the machine configuration, the patch gets merged with the respective section of the machine configuration:
machine:
network:
interfaces:
- interface: eth0
addresses:
- 10.0.0.2/24
hostname: worker1
In general, machine configuration contents are merged with the contents of the strategic merge patch, with strategic merge patch values overriding machine configuration values. There are some special rules:
- If the field value is a list, the patch value is appended to the list, with the following exceptions:
- values of the fields
cluster.network.podSubnetsandcluster.network.serviceSubnetsare overwritten on merge network.interfacessection is merged with the value in the machine config if there is a match oninterface:ordeviceSelector:keysnetwork.interfaces.vlanssection is merged with the value in the machine config if there is a match on thevlanId:keycluster.apiServer.auditPolicyvalue is replaced on merge
- values of the fields
When patching a multi-document machine configuration, following rules apply:
- for each document in the patch, the document is merged with the respective document in the machine configuration (matching by
kind,apiVersionandnamefor named documents) - if the patch document doesn’t exist in the machine configuration, it is appended to the machine configuration
The strategic merge patch itself might be a multi-document YAML, and each document will be applied as a patch to the base machine configuration.
RFC6902 (JSON Patches)
JSON patches can be written either in JSON or YAML format.
A proper JSON patch requires an op field that depends on the machine configuration contents: whether the path already exists or not.
For example, the strategic merge patch from the previous section can be written either as:
- op: replace
path: /machine/network/hostname
value: worker1
or:
- op: add
path: /machine/network/hostname
value: worker1
The correct op depends on whether the /machine/network/hostname section exists already in the machine config or not.
Examples
Machine Network
Base machine configuration:
# ...
machine:
network:
interfaces:
- interface: eth0
dhcp: false
addresses:
- 192.168.10.3/24
The goal is to add a virtual IP 192.168.10.50 to the eth0 interface and add another interface eth1 with DHCP enabled.
machine:
network:
interfaces:
- interface: eth0
vip:
ip: 192.168.10.50
- interface: eth1
dhcp: true- op: add
path: /machine/network/interfaces/0/vip
value:
ip: 192.168.10.50
- op: add
path: /machine/network/interfaces/-
value:
interface: eth1
dhcp: truePatched machine configuration:
machine:
network:
interfaces:
- interface: eth0
dhcp: false
addresses:
- 192.168.10.3/24
vip:
ip: 192.168.10.50
- interface: eth1
dhcp: true
Cluster Network
Base machine configuration:
cluster:
network:
dnsDomain: cluster.local
podSubnets:
- 10.244.0.0/16
serviceSubnets:
- 10.96.0.0/12
The goal is to update pod and service subnets and disable default CNI (Flannel).
cluster:
network:
podSubnets:
- 192.168.0.0/16
serviceSubnets:
- 192.0.0.0/12
cni:
name: none- op: replace
path: /cluster/network/podSubnets
value:
- 192.168.0.0/16
- op: replace
path: /cluster/network/serviceSubnets
value:
- 192.0.0.0/12
- op: add
path: /cluster/network/cni
value:
name: nonePatched machine configuration:
cluster:
network:
dnsDomain: cluster.local
podSubnets:
- 192.168.0.0/16
serviceSubnets:
- 192.0.0.0/12
cni:
name: none
Kubelet
Base machine configuration:
# ...
machine:
kubelet: {}
The goal is to set the kubelet node IP to come from the subnet 192.168.10.0/24.
machine:
kubelet:
nodeIP:
validSubnets:
- 192.168.10.0/24- op: add
path: /machine/kubelet/nodeIP
value:
validSubnets:
- 192.168.10.0/24Patched machine configuration:
machine:
kubelet:
nodeIP:
validSubnets:
- 192.168.10.0/24
Admission Control: Pod Security Policy
Base machine configuration:
cluster:
apiServer:
admissionControl:
- name: PodSecurity
configuration:
apiVersion: pod-security.admission.config.k8s.io/v1alpha1
defaults:
audit: restricted
audit-version: latest
enforce: baseline
enforce-version: latest
warn: restricted
warn-version: latest
exemptions:
namespaces:
- kube-system
runtimeClasses: []
usernames: []
kind: PodSecurityConfiguration
The goal is to add an exemption for the namespace rook-ceph.
cluster:
apiServer:
admissionControl:
- name: PodSecurity
configuration:
exemptions:
namespaces:
- rook-ceph- op: add
path: /cluster/apiServer/admissionControl/0/configuration/exemptions/namespaces/-
value: rook-cephPatched machine configuration:
cluster:
apiServer:
admissionControl:
- name: PodSecurity
configuration:
apiVersion: pod-security.admission.config.k8s.io/v1alpha1
defaults:
audit: restricted
audit-version: latest
enforce: baseline
enforce-version: latest
warn: restricted
warn-version: latest
exemptions:
namespaces:
- kube-system
- rook-ceph
runtimeClasses: []
usernames: []
kind: PodSecurityConfiguration
Configuration Patching with talosctl CLI
Several talosctl commands accept config patches as command-line flags.
Config patches might be passed either as an inline value or as a reference to a file with @file.patch syntax:
talosctl ... --patch '[{"op": "add", "path": "/machine/network/hostname", "value": "worker1"}]' --patch @file.patch
If multiple config patches are specified, they are applied in the order of appearance. The format of the patch (JSON patch or strategic merge patch) is detected automatically.
Talos machine configuration can be patched at the moment of generation with talosctl gen config:
talosctl gen config test-cluster https://172.20.0.1:6443 --config-patch @all.yaml --config-patch-control-plane @cp.yaml --config-patch-worker @worker.yaml
Generated machine configuration can also be patched after the fact with talosctl machineconfig patch
talosctl machineconfig patch worker.yaml --patch @patch.yaml -o worker1.yaml
Machine configuration on the running Talos node can be patched with talosctl patch:
talosctl patch mc --nodes 172.20.0.2 --patch @patch.yaml
2 - Containerd
The base containerd configuration expects to merge in any additional configs present in /etc/cri/conf.d/20-customization.part.
Examples
Exposing Metrics
Patch the machine config by adding the following:
machine:
files:
- content: |
[metrics]
address = "0.0.0.0:11234"
path: /etc/cri/conf.d/20-customization.part
op: create
Once the server reboots, metrics are now available:
$ curl ${IP}:11234/v1/metrics
# HELP container_blkio_io_service_bytes_recursive_bytes The blkio io service bytes recursive
# TYPE container_blkio_io_service_bytes_recursive_bytes gauge
container_blkio_io_service_bytes_recursive_bytes{container_id="0677d73196f5f4be1d408aab1c4125cf9e6c458a4bea39e590ac779709ffbe14",device="/dev/dm-0",major="253",minor="0",namespace="k8s.io",op="Async"} 0
container_blkio_io_service_bytes_recursive_bytes{container_id="0677d73196f5f4be1d408aab1c4125cf9e6c458a4bea39e590ac779709ffbe14",device="/dev/dm-0",major="253",minor="0",namespace="k8s.io",op="Discard"} 0
...
...
Pause Image
This change is often required for air-gapped environments, as containerd CRI plugin has a reference to the pause image which is used
to create pods, and it can’t be controlled with Kubernetes pod definitions.
machine:
files:
- content: |
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.k8s.io/pause:3.8"
path: /etc/cri/conf.d/20-customization.part
op: create
Now the pause image is set to registry.k8s.io/pause:3.8:
$ talosctl containers --kubernetes
NODE NAMESPACE ID IMAGE PID STATUS
172.20.0.5 k8s.io kube-system/kube-flannel-6hfck registry.k8s.io/pause:3.8 1773 SANDBOX_READY
172.20.0.5 k8s.io └─ kube-system/kube-flannel-6hfck:install-cni:bc39fec3cbac ghcr.io/siderolabs/install-cni:v1.3.0-alpha.0-2-gb155fa0 0 CONTAINER_EXITED
172.20.0.5 k8s.io └─ kube-system/kube-flannel-6hfck:install-config:5c3989353b98 ghcr.io/siderolabs/flannel:v0.20.1 0 CONTAINER_EXITED
172.20.0.5 k8s.io └─ kube-system/kube-flannel-6hfck:kube-flannel:116c67b50da8 ghcr.io/siderolabs/flannel:v0.20.1 2092 CONTAINER_RUNNING
172.20.0.5 k8s.io kube-system/kube-proxy-xp7jq registry.k8s.io/pause:3.8 1780 SANDBOX_READY
172.20.0.5 k8s.io └─ kube-system/kube-proxy-xp7jq:kube-proxy:84fc77c59e17 registry.k8s.io/kube-proxy:v1.26.0-alpha.3 1843 CONTAINER_RUNNING
3 - Custom Certificate Authorities
Appending the Certificate Authority
Append additional certificate authorities to the system’s trusted certificate store by patching the machine configuration with the following document:
apiVersion: v1alpha1
kind: TrustedRootsConfig
name: custom-ca
certificates: |-
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
Multiple documents can be appended, and multiple CA certificates might be present in each configuration document.
This configuration can be also applied in maintenance mode.
4 - Disk Encryption
It is possible to enable encryption for system disks at the OS level.
Currently, only STATE and EPHEMERAL partitions can be encrypted.
STATE contains the most sensitive node data: secrets and certs.
The EPHEMERAL partition may contain sensitive workload data.
Data is encrypted using LUKS2, which is provided by the Linux kernel modules and cryptsetup utility.
The operating system will run additional setup steps when encryption is enabled.
If the disk encryption is enabled for the STATE partition, the system will:
- Save STATE encryption config as JSON in the META partition.
- Before mounting the STATE partition, load encryption configs either from the machine config or from the META partition. Note that the machine config is always preferred over the META one.
- Before mounting the STATE partition, format and encrypt it. This occurs only if the STATE partition is empty and has no filesystem.
If the disk encryption is enabled for the EPHEMERAL partition, the system will:
- Get the encryption config from the machine config.
- Before mounting the EPHEMERAL partition, encrypt and format it.
This occurs only if the EPHEMERAL partition is empty and has no filesystem.
Talos Linux supports four encryption methods, which can be combined together for a single partition:
static- encrypt with the static passphrase (weakest protection, forSTATEpartition encryption it means that the passphrase will be stored in theMETApartition).nodeID- encrypt with the key derived from the node UUID (weak, it is designed to protect against data being leaked or recovered from a drive that has been removed from a Talos Linux node).kms- encrypt using key sealed with network KMS (strong, but requires network access to decrypt the data.)tpm- encrypt with the key derived from the TPM (strong, when used with SecureBoot).
Note:
nodeIDencryption is not designed to protect against attacks where physical access to the machine, including the drive, is available. It uses the hardware characteristics of the machine in order to decrypt the data, so drives that have been removed, or recycled from a cloud environment or attached to a different virtual machine, will maintain their protection and encryption.
Configuration
Disk encryption is disabled by default. To enable disk encryption you should modify the machine configuration with the following options:
machine:
...
systemDiskEncryption:
ephemeral:
provider: luks2
keys:
- nodeID: {}
slot: 0
state:
provider: luks2
keys:
- nodeID: {}
slot: 0
Encryption Keys
Note: What the LUKS2 docs call “keys” are, in reality, a passphrase. When this passphrase is added, LUKS2 runs argon2 to create an actual key from that passphrase.
LUKS2 supports up to 32 encryption keys and it is possible to specify all of them in the machine configuration. Talos always tries to sync the keys list defined in the machine config with the actual keys defined for the LUKS2 partition. So if you update the keys list, keep at least one key that is not changed to be used for key management.
When you define a key you should specify the key kind and the slot:
machine:
...
state:
keys:
- nodeID: {} # key kind
slot: 1
ephemeral:
keys:
- static:
passphrase: supersecret
slot: 0
Take a note that key order does not play any role on which key slot is used. Every key must always have a slot defined.
Encryption Key Kinds
Talos supports two kinds of keys:
nodeIDwhich is generated using the node UUID and the partition label (note that if the node UUID is not really random it will fail the entropy check).staticwhich you define right in the configuration.kmswhich is sealed with the network KMS.tpmwhich is sealed using the TPM and protected with SecureBoot.
Note: Use static keys only if your STATE partition is encrypted and only for the EPHEMERAL partition. For the STATE partition it will be stored in the META partition, which is not encrypted.
Key Rotation
In order to completely rotate keys, it is necessary to do talosctl apply-config a couple of times, since there is a need to always maintain a single working key while changing the other keys around it.
So, for example, first add a new key:
machine:
...
ephemeral:
keys:
- static:
passphrase: oldkey
slot: 0
- static:
passphrase: newkey
slot: 1
...
Run:
talosctl apply-config -n <node> -f config.yaml
Then remove the old key:
machine:
...
ephemeral:
keys:
- static:
passphrase: newkey
slot: 1
...
Run:
talosctl apply-config -n <node> -f config.yaml
Going from Unencrypted to Encrypted and Vice Versa
Ephemeral Partition
There is no in-place encryption support for the partitions right now, so to avoid losing data only empty partitions can be encrypted.
As such, migration from unencrypted to encrypted needs some additional handling, especially around explicitly wiping partitions.
apply-configshould be called with--mode=staged.- Partition should be wiped after
apply-config, but before the reboot.
Edit your machine config and add the encryption configuration:
vim config.yaml
Apply the configuration with --mode=staged:
talosctl apply-config -f config.yaml -n <node ip> --mode=staged
Wipe the partition you’re going to encrypt:
talosctl reset --system-labels-to-wipe EPHEMERAL -n <node ip> --reboot=true
That’s it! After you run the last command, the partition will be wiped and the node will reboot. During the next boot the system will encrypt the partition.
State Partition
Calling wipe against the STATE partition will make the node lose the config, so the previous flow is not going to work.
The flow should be to first wipe the STATE partition:
talosctl reset --system-labels-to-wipe STATE -n <node ip> --reboot=true
Node will enter into maintenance mode, then run apply-config with --insecure flag:
talosctl apply-config --insecure -n <node ip> -f config.yaml
After installation is complete the node should encrypt the STATE partition.
5 - Editing Machine Configuration
Talos node state is fully defined by machine configuration. Initial configuration is delivered to the node at bootstrap time, but configuration can be updated while the node is running.
There are three talosctl commands which facilitate machine configuration updates:
talosctl apply-configto apply configuration from the filetalosctl edit machineconfigto launch an editor with existing node configuration, make changes and apply configuration backtalosctl patch machineconfigto apply automated machine configuration via JSON patch
Each of these commands can operate in one of four modes:
- apply change in automatic mode (default): reboot if the change can’t be applied without a reboot, otherwise apply the change immediately
- apply change with a reboot (
--mode=reboot): update configuration, reboot Talos node to apply configuration change - apply change immediately (
--mode=no-rebootflag): change is applied immediately without a reboot, fails if the change contains any fields that can not be updated without a reboot - apply change on next reboot (
--mode=staged): change is staged to be applied after a reboot, but node is not rebooted - apply change with automatic revert (
--mode=try): change is applied immediately (if not possible, returns an error), and reverts it automatically in 1 minute if no configuration update is applied - apply change in the interactive mode (
--mode=interactive; only fortalosctl apply-config): launches TUI based interactive installer
Note: applying change on next reboot (
--mode=staged) doesn’t modify current node configuration, so next call totalosctl edit machineconfig --mode=stagedwill not see changes
Additionally, there is also talosctl get machineconfig -o yaml, which retrieves the current node configuration API resource and contains the machine configuration in the .spec field.
It can be used to modify the configuration locally before being applied to the node.
The list of config changes allowed to be applied immediately in Talos v1.8.0-alpha.0:
.debug.cluster.machine.time.machine.ca.machine.acceptedCAs.machine.certCANs.machine.install(configuration is only applied during install/upgrade).machine.network.machine.nodeLabels.machine.sysfs.machine.sysctls.machine.logging.machine.controlplane.machine.kubelet.machine.pods.machine.kernel.machine.registries(CRI containerd plugin will not pick up the registry authentication settings without a reboot).machine.features.kubernetesTalosAPIAccess
talosctl apply-config
This command is traditionally used to submit initial machine configuration generated by talosctl gen config to the node.
It can also be used to apply configuration to running nodes.
The initial YAML for this is typically obtained using talosctl get machineconfig -o yaml | yq eval .spec >machs.yaml.
(We must use yq because for historical reasons, get returns the configuration as a full resource, while apply-config only accepts the raw machine config directly.)
Example:
talosctl -n <IP> apply-config -f config.yaml
Command apply-config can also be invoked as apply machineconfig:
talosctl -n <IP> apply machineconfig -f config.yaml
Applying machine configuration immediately (without a reboot):
talosctl -n IP apply machineconfig -f config.yaml --mode=no-reboot
Starting the interactive installer:
talosctl -n IP apply machineconfig --mode=interactive
Note: when a Talos node is running in the maintenance mode it’s necessary to provide
--insecure (-i)flag to connect to the API and apply the config.
talosctl edit machineconfig
Command talosctl edit loads current machine configuration from the node and launches configured editor to modify the config.
If config hasn’t been changed in the editor (or if updated config is empty), update is not applied.
Note: Talos uses environment variables
TALOS_EDITOR,EDITORto pick up the editor preference. If environment variables are missing,vieditor is used by default.
Example:
talosctl -n <IP> edit machineconfig
Configuration can be edited for multiple nodes if multiple IP addresses are specified:
talosctl -n <IP1>,<IP2>,... edit machineconfig
Applying machine configuration change immediately (without a reboot):
talosctl -n <IP> edit machineconfig --mode=no-reboot
talosctl patch machineconfig
Command talosctl patch works similar to talosctl edit command - it loads current machine configuration, but instead of launching configured editor it applies a set of JSON patches to the configuration and writes the result back to the node.
Example, updating kubelet version (in auto mode):
$ talosctl -n <IP> patch machineconfig -p '[{"op": "replace", "path": "/machine/kubelet/image", "value": "ghcr.io/siderolabs/kubelet:v1.31.0-beta.0"}]'
patched mc at the node <IP>
Updating kube-apiserver version in immediate mode (without a reboot):
$ talosctl -n <IP> patch machineconfig --mode=no-reboot -p '[{"op": "replace", "path": "/cluster/apiServer/image", "value": "registry.k8s.io/kube-apiserver:v1.31.0-beta.0"}]'
patched mc at the node <IP>
A patch might be applied to multiple nodes when multiple IPs are specified:
talosctl -n <IP1>,<IP2>,... patch machineconfig -p '[{...}]'
Patches can also be sourced from files using @file syntax:
talosctl -n <IP> patch machineconfig -p @kubelet-patch.json -p @manifest-patch.json
It might be easier to store patches in YAML format vs. the default JSON format. Talos can detect file format automatically:
# kubelet-patch.yaml
- op: replace
path: /machine/kubelet/image
value: ghcr.io/siderolabs/kubelet:v1.31.0-beta.0
talosctl -n <IP> patch machineconfig -p @kubelet-patch.yaml
Recovering from Node Boot Failures
If a Talos node fails to boot because of wrong configuration (for example, control plane endpoint is incorrect), configuration can be updated to fix the issue.
6 - Logging
Viewing logs
Kernel messages can be retrieved with talosctl dmesg command:
$ talosctl -n 172.20.1.2 dmesg
172.20.1.2: kern: info: [2021-11-10T10:09:37.662764956Z]: Command line: init_on_alloc=1 slab_nomerge pti=on consoleblank=0 nvme_core.io_timeout=4294967295 printk.devkmsg=on ima_template=ima-ng ima_appraise=fix ima_hash=sha512 console=ttyS0 reboot=k panic=1 talos.shutdown=halt talos.platform=metal talos.config=http://172.20.1.1:40101/config.yaml
[...]
Service logs can be retrieved with talosctl logs command:
$ talosctl -n 172.20.1.2 services
NODE SERVICE STATE HEALTH LAST CHANGE LAST EVENT
172.20.1.2 apid Running OK 19m27s ago Health check successful
172.20.1.2 containerd Running OK 19m29s ago Health check successful
172.20.1.2 cri Running OK 19m27s ago Health check successful
172.20.1.2 etcd Running OK 19m22s ago Health check successful
172.20.1.2 kubelet Running OK 19m20s ago Health check successful
172.20.1.2 machined Running ? 19m30s ago Service started as goroutine
172.20.1.2 trustd Running OK 19m27s ago Health check successful
172.20.1.2 udevd Running OK 19m28s ago Health check successful
$ talosctl -n 172.20.1.2 logs machined
172.20.1.2: [talos] task setupLogger (1/1): done, 106.109µs
172.20.1.2: [talos] phase logger (1/7): done, 564.476µs
[...]
Container logs for Kubernetes pods can be retrieved with talosctl logs -k command:
$ talosctl -n 172.20.1.2 containers -k
NODE NAMESPACE ID IMAGE PID STATUS
172.20.1.2 k8s.io kube-system/kube-flannel-dk6d5 registry.k8s.io/pause:3.6 1329 SANDBOX_READY
172.20.1.2 k8s.io └─ kube-system/kube-flannel-dk6d5:install-cni:f1d4cf68feb9 ghcr.io/siderolabs/install-cni:v0.7.0-alpha.0-1-g2bb2efc 0 CONTAINER_EXITED
172.20.1.2 k8s.io └─ kube-system/kube-flannel-dk6d5:install-config:bc39fec3cbac quay.io/coreos/flannel:v0.13.0 0 CONTAINER_EXITED
172.20.1.2 k8s.io └─ kube-system/kube-flannel-dk6d5:kube-flannel:5c3989353b98 quay.io/coreos/flannel:v0.13.0 1610 CONTAINER_RUNNING
172.20.1.2 k8s.io kube-system/kube-proxy-gfkqj registry.k8s.io/pause:3.5 1311 SANDBOX_READY
172.20.1.2 k8s.io └─ kube-system/kube-proxy-gfkqj:kube-proxy:ad5e8ddc7e7f registry.k8s.io/kube-proxy:v1.31.0-beta.0 1379 CONTAINER_RUNNING
$ talosctl -n 172.20.1.2 logs -k kube-system/kube-proxy-gfkqj:kube-proxy:ad5e8ddc7e7f
172.20.1.2: 2021-11-30T19:13:20.567825192Z stderr F I1130 19:13:20.567737 1 server_others.go:138] "Detected node IP" address="172.20.0.3"
172.20.1.2: 2021-11-30T19:13:20.599684397Z stderr F I1130 19:13:20.599613 1 server_others.go:206] "Using iptables Proxier"
[...]
If some host workloads (e.g. system extensions) send syslog messages, they can be retrieved with talosctl logs syslogd command.
Sending logs
Service logs
You can enable logs sendings in machine configuration:
machine:
logging:
destinations:
- endpoint: "udp://127.0.0.1:12345/"
format: "json_lines"
- endpoint: "tcp://host:5044/"
format: "json_lines"
Several destinations can be specified.
Supported protocols are UDP and TCP.
The only currently supported format is json_lines:
{
"msg": "[talos] apply config request: immediate true, on reboot false",
"talos-level": "info",
"talos-service": "machined",
"talos-time": "2021-11-10T10:48:49.294858021Z"
}
Messages are newline-separated when sent over TCP.
Over UDP messages are sent with one message per packet.
msg, talos-level, talos-service, and talos-time fields are always present; there may be additional fields.
Every message sent can be enhanced with additional fields by using the extraTags field in the machine configuration:
machine:
logging:
destinations:
- endpoint: "udp://127.0.0.1:12345/"
format: "json_lines"
extraTags:
server: s03-rack07
The specified extraTags are added to every message sent to the destination verbatim.
Kernel logs
Kernel log delivery can be enabled with the talos.logging.kernel kernel command line argument, which can be specified
in the .machine.installer.extraKernelArgs:
machine:
install:
extraKernelArgs:
- talos.logging.kernel=tcp://host:5044/
Also kernel logs delivery can be configured using the document in machine configuration:
apiVersion: v1alpha1
kind: KmsgLogConfig
name: remote-log
url: tcp://host:5044/
Kernel log destination is specified in the same way as service log endpoint.
The only supported format is json_lines.
Sample message:
{
"clock":6252819, // time relative to the kernel boot time
"facility":"user",
"msg":"[talos] task startAllServices (1/1): waiting for 6 services\n",
"priority":"warning",
"seq":711,
"talos-level":"warn", // Talos-translated `priority` into common logging level
"talos-time":"2021-11-26T16:53:21.3258698Z" // Talos-translated `clock` using current time
}
extraKernelArgsin the machine configuration are only applied on Talos upgrades, not just by applying the config. (Upgrading to the same version is fine).
Filebeat example
To forward logs to other Log collection services, one way to do this is sending them to a Filebeat running in the cluster itself (in the host network), which takes care of forwarding it to other endpoints (and the necessary transformations).
If Elastic Cloud on Kubernetes is being used, the following Beat (custom resource) configuration might be helpful:
apiVersion: beat.k8s.elastic.co/v1beta1
kind: Beat
metadata:
name: talos
spec:
type: filebeat
version: 7.15.1
elasticsearchRef:
name: talos
config:
filebeat.inputs:
- type: "udp"
host: "127.0.0.1:12345"
processors:
- decode_json_fields:
fields: ["message"]
target: ""
- timestamp:
field: "talos-time"
layouts:
- "2006-01-02T15:04:05.999999999Z07:00"
- drop_fields:
fields: ["message", "talos-time"]
- rename:
fields:
- from: "msg"
to: "message"
daemonSet:
updateStrategy:
rollingUpdate:
maxUnavailable: 100%
podTemplate:
spec:
dnsPolicy: ClusterFirstWithHostNet
hostNetwork: true
securityContext:
runAsUser: 0
containers:
- name: filebeat
ports:
- protocol: UDP
containerPort: 12345
hostPort: 12345
The input configuration ensures that messages and timestamps are extracted properly. Refer to the Filebeat documentation on how to forward logs to other outputs.
Also note the hostNetwork: true in the daemonSet configuration.
This ensures filebeat uses the host network, and listens on 127.0.0.1:12345
(UDP) on every machine, which can then be specified as a logging endpoint in
the machine configuration.
Fluent-bit example
First, we’ll create a value file for the fluentd-bit Helm chart.
# fluentd-bit.yaml
podAnnotations:
fluentbit.io/exclude: 'true'
extraPorts:
- port: 12345
containerPort: 12345
protocol: TCP
name: talos
config:
service: |
[SERVICE]
Flush 5
Daemon Off
Log_Level warn
Parsers_File custom_parsers.conf
inputs: |
[INPUT]
Name tcp
Listen 0.0.0.0
Port 12345
Format json
Tag talos.*
[INPUT]
Name tail
Alias kubernetes
Path /var/log/containers/*.log
Parser containerd
Tag kubernetes.*
[INPUT]
Name tail
Alias audit
Path /var/log/audit/kube/*.log
Parser audit
Tag audit.*
filters: |
[FILTER]
Name kubernetes
Alias kubernetes
Match kubernetes.*
Kube_Tag_Prefix kubernetes.var.log.containers.
Use_Kubelet Off
Merge_Log On
Merge_Log_Trim On
Keep_Log Off
K8S-Logging.Parser Off
K8S-Logging.Exclude On
Annotations Off
Labels On
[FILTER]
Name modify
Match kubernetes.*
Add source kubernetes
Remove logtag
customParsers: |
[PARSER]
Name audit
Format json
Time_Key requestReceivedTimestamp
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
[PARSER]
Name containerd
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<log>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
outputs: |
[OUTPUT]
Name stdout
Alias stdout
Match *
Format json_lines
# If you wish to ship directly to Loki from Fluentbit,
# Uncomment the following output, updating the Host with your Loki DNS/IP info as necessary.
# [OUTPUT]
# Name loki
# Match *
# Host loki.loki.svc
# Port 3100
# Labels job=fluentbit
# Auto_Kubernetes_Labels on
daemonSetVolumes:
- name: varlog
hostPath:
path: /var/log
daemonSetVolumeMounts:
- name: varlog
mountPath: /var/log
tolerations:
- operator: Exists
effect: NoSchedule
Next, we will add the helm repo for FluentBit, and deploy it to the cluster.
helm repo add fluent https://fluent.github.io/helm-charts
helm upgrade -i --namespace=kube-system -f fluentd-bit.yaml fluent-bit fluent/fluent-bit
Now we need to find the service IP.
$ kubectl -n kube-system get svc -l app.kubernetes.io/name=fluent-bit
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
fluent-bit ClusterIP 10.200.0.138 <none> 2020/TCP,5170/TCP 108m
Finally, we will change talos log destination with the command talosctl edit mc.
machine:
logging:
destinations:
- endpoint: "tcp://10.200.0.138:5170"
format: "json_lines"
This example configuration was well tested with Cilium CNI, and it should work with iptables/ipvs based CNI plugins too.
Vector example
Vector is a lightweight observability pipeline ideal for a Kubernetes environment. It can ingest (source) logs from multiple sources, perform remapping on the logs (transform), and forward the resulting pipeline to multiple destinations (sinks). As it is an end to end platform, it can be run as a single-deployment ‘aggregator’ as well as a replicaSet of ‘Agents’ that run on each node.
As Talos can be set as above to send logs to a destination, we can run Vector as an Aggregator, and forward both kernel and service to a UDP socket in-cluster.
Below is an excerpt of a source/sink setup for Talos, with a ‘sink’ destination of an in-cluster Grafana Loki log aggregation service. As Loki can create labels from the log input, we have set up the Loki sink to create labels based on the host IP, service and facility of the inbound logs.
Note that a method of exposing the Vector service will be required which may vary depending on your setup - a LoadBalancer is a good option.
role: "Stateless-Aggregator"
# Sources
sources:
talos_kernel_logs:
address: 0.0.0.0:6050
type: socket
mode: udp
max_length: 102400
decoding:
codec: json
host_key: __host
talos_service_logs:
address: 0.0.0.0:6051
type: socket
mode: udp
max_length: 102400
decoding:
codec: json
host_key: __host
# Sinks
sinks:
talos_kernel:
type: loki
inputs:
- talos_kernel_logs_xform
endpoint: http://loki.system-monitoring:3100
encoding:
codec: json
except_fields:
- __host
batch:
max_bytes: 1048576
out_of_order_action: rewrite_timestamp
labels:
hostname: >-
{{`{{ __host }}`}}
facility: >-
{{`{{ facility }}`}}
talos_service:
type: loki
inputs:
- talos_service_logs_xform
endpoint: http://loki.system-monitoring:3100
encoding:
codec: json
except_fields:
- __host
batch:
max_bytes: 400000
out_of_order_action: rewrite_timestamp
labels:
hostname: >-
{{`{{ __host }}`}}
service: >-
{{`{{ "talos-service" }}`}}
7 - NVIDIA Fabric Manager
NVIDIA GPUs that have nvlink support (for eg: A100) will need the nvidia-fabricmanager system extension also enabled in addition to the NVIDIA drivers. For more information on Fabric Manager refer https://docs.nvidia.com/datacenter/tesla/fabric-manager-user-guide/index.html
The published versions of the NVIDIA fabricmanager system extensions is available here
The
nvidia-fabricmanagerextension version has to match with the NVIDIA driver version in use.
Enabling the NVIDIA fabricmanager system extension
Create the boot assets or a custom installer and perform a machine upgrade which include the following system extensions:
ghcr.io/siderolabs/nvidia-open-gpu-kernel-modules:535.129.03-v1.8.0-alpha.0
ghcr.io/siderolabs/nvidia-container-toolkit:535.129.03-v1.14.5
ghcr.io/siderolabs/nvidia-fabricmanager:535.129.03
Patch the machine configuration to load the required modules:
machine:
kernel:
modules:
- name: nvidia
- name: nvidia_uvm
- name: nvidia_drm
- name: nvidia_modeset
sysctls:
net.core.bpf_jit_harden: 1
8 - NVIDIA GPU (OSS drivers)
Enabling NVIDIA GPU support on Talos is bound by NVIDIA EULA. The Talos published NVIDIA OSS drivers are bound to a specific Talos release. The extensions versions also needs to be updated when upgrading Talos.
We will be using the following NVIDIA OSS system extensions:
nvidia-open-gpu-kernel-modulesnvidia-container-toolkit
Create the boot assets which includes the system extensions mentioned above (or create a custom installer and perform a machine upgrade if Talos is already installed).
Make sure the driver version matches for both the
nvidia-open-gpu-kernel-modulesandnvidia-container-toolkitextensions. Thenvidia-open-gpu-kernel-modulesextension is versioned as<nvidia-driver-version>-<talos-release-version>and thenvidia-container-toolkitextension is versioned as<nvidia-driver-version>-<nvidia-container-toolkit-version>.
Enabling the NVIDIA OSS modules
Patch Talos machine configuration using the patch gpu-worker-patch.yaml:
machine:
kernel:
modules:
- name: nvidia
- name: nvidia_uvm
- name: nvidia_drm
- name: nvidia_modeset
sysctls:
net.core.bpf_jit_harden: 1
Now apply the patch to all Talos nodes in the cluster having NVIDIA GPU’s installed:
talosctl patch mc --patch @gpu-worker-patch.yaml
The NVIDIA modules should be loaded and the system extension should be installed.
This can be confirmed by running:
talosctl read /proc/modules
which should produce an output similar to below:
nvidia_uvm 1146880 - - Live 0xffffffffc2733000 (PO)
nvidia_drm 69632 - - Live 0xffffffffc2721000 (PO)
nvidia_modeset 1142784 - - Live 0xffffffffc25ea000 (PO)
nvidia 39047168 - - Live 0xffffffffc00ac000 (PO)
talosctl get extensions
which should produce an output similar to below:
NODE NAMESPACE TYPE ID VERSION NAME VERSION
172.31.41.27 runtime ExtensionStatus 000.ghcr.io-siderolabs-nvidia-container-toolkit-515.65.01-v1.10.0 1 nvidia-container-toolkit 515.65.01-v1.10.0
172.31.41.27 runtime ExtensionStatus 000.ghcr.io-siderolabs-nvidia-open-gpu-kernel-modules-515.65.01-v1.2.0 1 nvidia-open-gpu-kernel-modules 515.65.01-v1.2.0
talosctl read /proc/driver/nvidia/version
which should produce an output similar to below:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 515.65.01 Wed Mar 16 11:24:05 UTC 2022
GCC version: gcc version 12.2.0 (GCC)
Deploying NVIDIA device plugin
First we need to create the RuntimeClass
Apply the following manifest to create a runtime class that uses the extension:
---
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: nvidia
handler: nvidia
Install the NVIDIA device plugin:
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm install nvidia-device-plugin nvdp/nvidia-device-plugin --version=0.13.0 --set=runtimeClassName=nvidia
(Optional) Setting the default runtime class as nvidia
Do note that this will set the default runtime class to
nvidiafor all pods scheduled on the node.
Create a patch yaml nvidia-default-runtimeclass.yaml to update the machine config similar to below:
- op: add
path: /machine/files
value:
- content: |
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
path: /etc/cri/conf.d/20-customization.part
op: create
Now apply the patch to all Talos nodes in the cluster having NVIDIA GPU’s installed:
talosctl patch mc --patch @nvidia-default-runtimeclass.yaml
Testing the runtime class
Note the
spec.runtimeClassNamebeing explicitly set tonvidiain the pod spec.
Run the following command to test the runtime class:
kubectl run \
nvidia-test \
--restart=Never \
-ti --rm \
--image nvcr.io/nvidia/cuda:12.5.0-base-ubuntu22.04 \
--overrides '{"spec": {"runtimeClassName": "nvidia"}}' \
nvidia-smi
9 - NVIDIA GPU (Proprietary drivers)
Enabling NVIDIA GPU support on Talos is bound by NVIDIA EULA. The Talos published NVIDIA drivers are bound to a specific Talos release. The extensions versions also needs to be updated when upgrading Talos.
We will be using the following NVIDIA system extensions:
nonfree-kmod-nvidianvidia-container-toolkit
To build a NVIDIA driver version not published by SideroLabs follow the instructions here
Create the boot assets which includes the system extensions mentioned above (or create a custom installer and perform a machine upgrade if Talos is already installed).
Make sure the driver version matches for both the
nonfree-kmod-nvidiaandnvidia-container-toolkitextensions. Thenonfree-kmod-nvidiaextension is versioned as<nvidia-driver-version>-<talos-release-version>and thenvidia-container-toolkitextension is versioned as<nvidia-driver-version>-<nvidia-container-toolkit-version>.
Enabling the NVIDIA modules and the system extension
Patch Talos machine configuration using the patch gpu-worker-patch.yaml:
machine:
kernel:
modules:
- name: nvidia
- name: nvidia_uvm
- name: nvidia_drm
- name: nvidia_modeset
sysctls:
net.core.bpf_jit_harden: 1
Now apply the patch to all Talos nodes in the cluster having NVIDIA GPU’s installed:
talosctl patch mc --patch @gpu-worker-patch.yaml
The NVIDIA modules should be loaded and the system extension should be installed.
This can be confirmed by running:
talosctl read /proc/modules
which should produce an output similar to below:
nvidia_uvm 1146880 - - Live 0xffffffffc2733000 (PO)
nvidia_drm 69632 - - Live 0xffffffffc2721000 (PO)
nvidia_modeset 1142784 - - Live 0xffffffffc25ea000 (PO)
nvidia 39047168 - - Live 0xffffffffc00ac000 (PO)
talosctl get extensions
which should produce an output similar to below:
NODE NAMESPACE TYPE ID VERSION NAME VERSION
172.31.41.27 runtime ExtensionStatus 000.ghcr.io-frezbo-nvidia-container-toolkit-510.60.02-v1.9.0 1 nvidia-container-toolkit 510.60.02-v1.9.0
talosctl read /proc/driver/nvidia/version
which should produce an output similar to below:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 510.60.02 Wed Mar 16 11:24:05 UTC 2022
GCC version: gcc version 11.2.0 (GCC)
Deploying NVIDIA device plugin
First we need to create the RuntimeClass
Apply the following manifest to create a runtime class that uses the extension:
---
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: nvidia
handler: nvidia
Install the NVIDIA device plugin:
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm install nvidia-device-plugin nvdp/nvidia-device-plugin --version=0.13.0 --set=runtimeClassName=nvidia
(Optional) Setting the default runtime class as nvidia
Do note that this will set the default runtime class to
nvidiafor all pods scheduled on the node.
Create a patch yaml nvidia-default-runtimeclass.yaml to update the machine config similar to below:
- op: add
path: /machine/files
value:
- content: |
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
path: /etc/cri/conf.d/20-customization.part
op: create
Now apply the patch to all Talos nodes in the cluster having NVIDIA GPU’s installed:
talosctl patch mc --patch @nvidia-default-runtimeclass.yaml
Testing the runtime class
Note the
spec.runtimeClassNamebeing explicitly set tonvidiain the pod spec.
Run the following command to test the runtime class:
kubectl run \
nvidia-test \
--restart=Never \
-ti --rm \
--image nvcr.io/nvidia/cuda:12.5.0-base-ubuntu22.04 \
--overrides '{"spec": {"runtimeClassName": "nvidia"}}' \
nvidia-smi
10 - Pull Through Image Cache
In this guide we will create a set of local caching Docker registry proxies to minimize local cluster startup time.
When running Talos locally, pulling images from container registries might take a significant amount of time. We spin up local caching pass-through registries to cache images and configure a local Talos cluster to use those proxies. A similar approach might be used to run Talos in production in air-gapped environments. It can be also used to verify that all the images are available in local registries.
Video Walkthrough
To see a live demo of this writeup, see the video below:
Requirements
The follow are requirements for creating the set of caching proxies:
Launch the Caching Docker Registry Proxies
Talos pulls from docker.io, registry.k8s.io, gcr.io, and ghcr.io by default.
If your configuration is different, you might need to modify the commands below:
docker run -d -p 5000:5000 \
-e REGISTRY_PROXY_REMOTEURL=https://registry-1.docker.io \
--restart always \
--name registry-docker.io registry:2
docker run -d -p 5001:5000 \
-e REGISTRY_PROXY_REMOTEURL=https://registry.k8s.io \
--restart always \
--name registry-registry.k8s.io registry:2
docker run -d -p 5003:5000 \
-e REGISTRY_PROXY_REMOTEURL=https://gcr.io \
--restart always \
--name registry-gcr.io registry:2
docker run -d -p 5004:5000 \
-e REGISTRY_PROXY_REMOTEURL=https://ghcr.io \
--restart always \
--name registry-ghcr.io registry:2
Note: Proxies are started as docker containers, and they’re automatically configured to start with Docker daemon.
As a registry container can only handle a single upstream Docker registry, we launch a container per upstream, each on its own host port (5000, 5001, 5002, 5003 and 5004).
Using Caching Registries with QEMU Local Cluster
With a QEMU local cluster, a bridge interface is created on the host. As registry containers expose their ports on the host, we can use bridge IP to direct proxy requests.
sudo talosctl cluster create --provisioner qemu \
--registry-mirror docker.io=http://10.5.0.1:5000 \
--registry-mirror registry.k8s.io=http://10.5.0.1:5001 \
--registry-mirror gcr.io=http://10.5.0.1:5003 \
--registry-mirror ghcr.io=http://10.5.0.1:5004
The Talos local cluster should now start pulling via caching registries.
This can be verified via registry logs, e.g. docker logs -f registry-docker.io.
The first time cluster boots, images are pulled and cached, so next cluster boot should be much faster.
Note:
10.5.0.1is a bridge IP with default network (10.5.0.0/24), if using custom--cidr, value should be adjusted accordingly.
Using Caching Registries with docker Local Cluster
With a docker local cluster we can use docker bridge IP, default value for that IP is 172.17.0.1.
On Linux, the docker bridge address can be inspected with ip addr show docker0.
talosctl cluster create --provisioner docker \
--registry-mirror docker.io=http://172.17.0.1:5000 \
--registry-mirror registry.k8s.io=http://172.17.0.1:5001 \
--registry-mirror gcr.io=http://172.17.0.1:5003 \
--registry-mirror ghcr.io=http://172.17.0.1:5004
Machine Configuration
The caching registries can be configured via machine configuration patch, equivalent to the command line flags above:
machine:
registries:
mirrors:
docker.io:
endpoints:
- http://10.5.0.1:5000
gcr.io:
endpoints:
- http://10.5.0.1:5003
ghcr.io:
endpoints:
- http://10.5.0.1:5004
registry.k8s.io:
endpoints:
- http://10.5.0.1:5001
Cleaning Up
To cleanup, run:
docker rm -f registry-docker.io
docker rm -f registry-registry.k8s.io
docker rm -f registry-gcr.io
docker rm -f registry-ghcr.io
Note: Removing docker registry containers also removes the image cache. So if you plan to use caching registries, keep the containers running.
Using Harbor as a Caching Registry
Harbor is an open source container registry that can be used as a caching proxy. Harbor supports configuring multiple upstream registries, so it can be used to cache multiple registries at once behind a single endpoint.
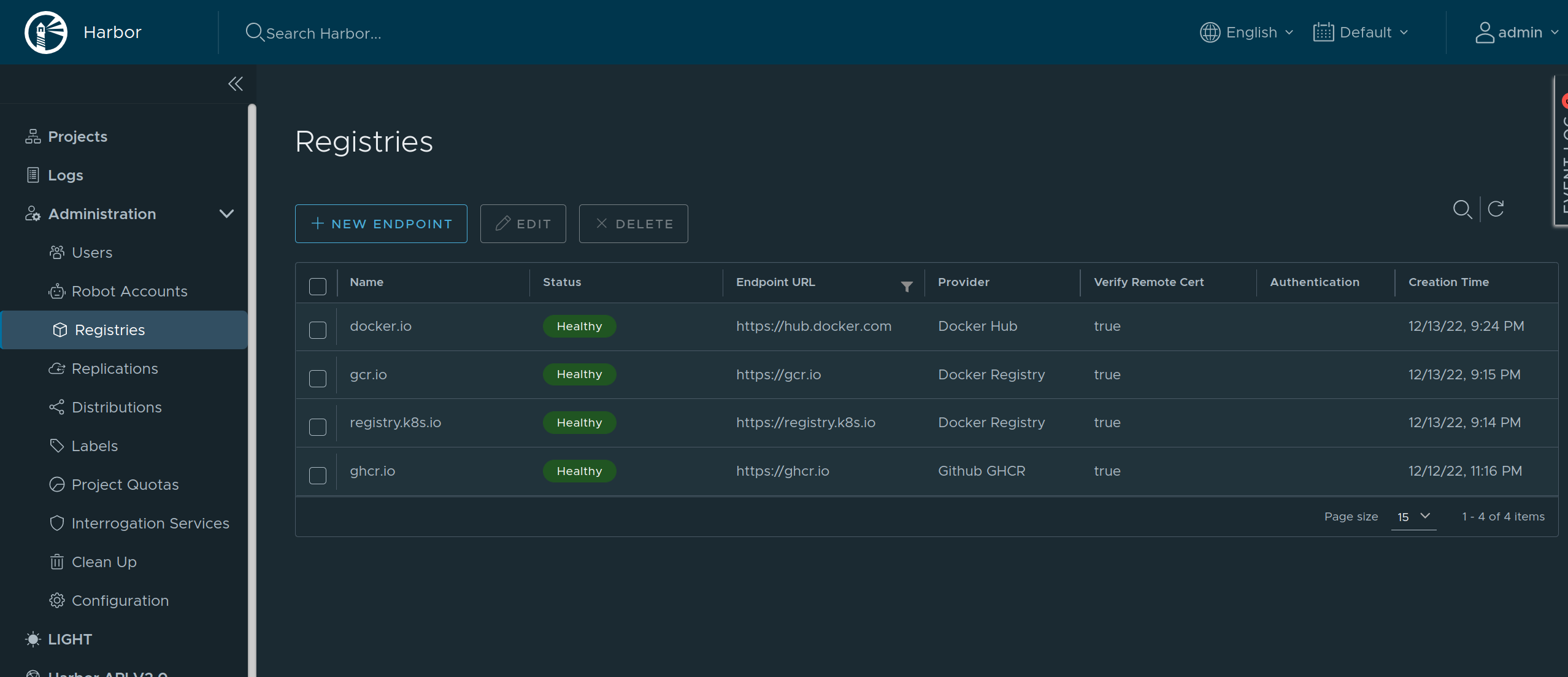
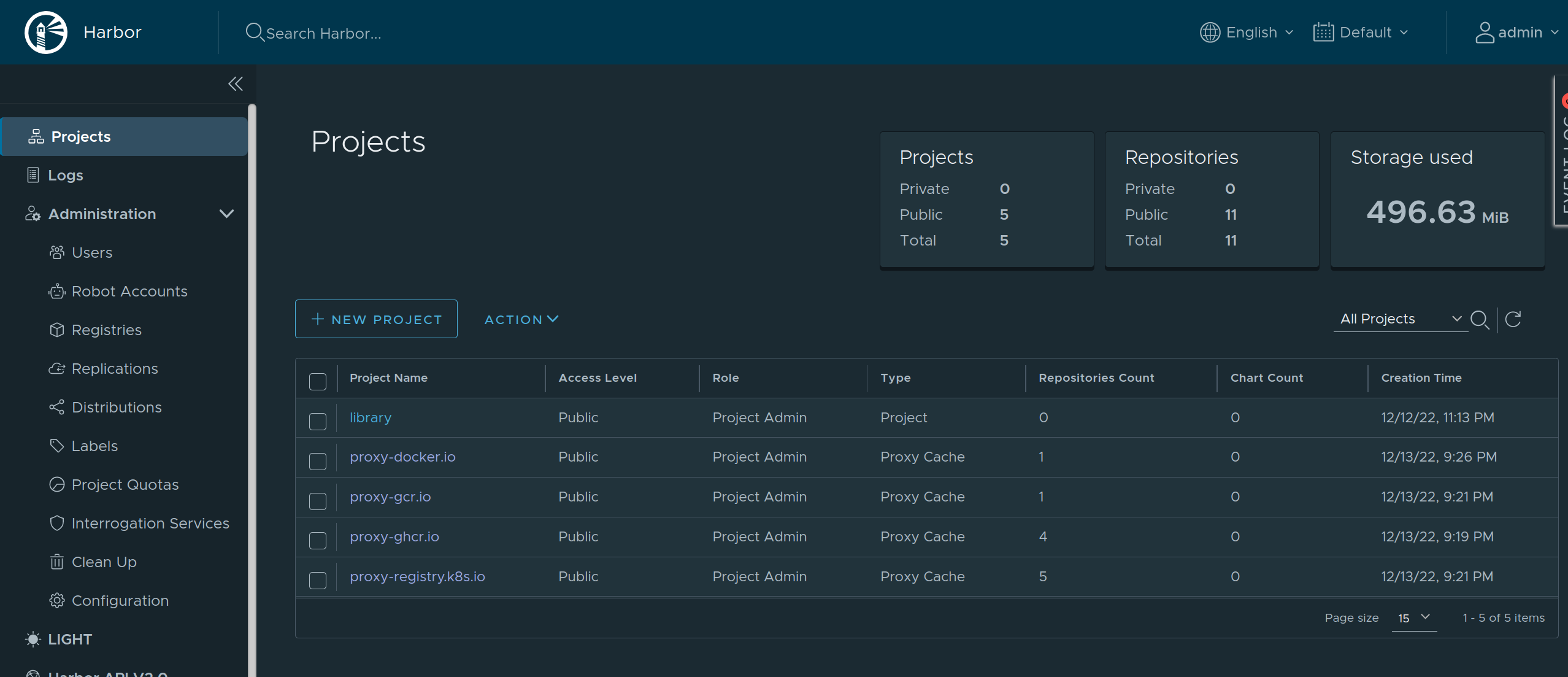
As Harbor puts a registry name in the pull image path, we need to set overridePath: true to prevent Talos and containerd from appending /v2 to the path.
machine:
registries:
mirrors:
docker.io:
endpoints:
- http://harbor/v2/proxy-docker.io
overridePath: true
ghcr.io:
endpoints:
- http://harbor/v2/proxy-ghcr.io
overridePath: true
gcr.io:
endpoints:
- http://harbor/v2/proxy-gcr.io
overridePath: true
registry.k8s.io:
endpoints:
- http://harbor/v2/proxy-registry.k8s.io
overridePath: true
The Harbor external endpoint (http://harbor in this example) can be configured with authentication or custom TLS:
machine:
registries:
config:
harbor:
auth:
username: admin
password: password
11 - Role-based access control (RBAC)
Talos v0.11 introduced initial support for role-based access control (RBAC). This guide will explain what that is and how to enable it without losing access to the cluster.
RBAC in Talos
Talos uses certificates to authorize users. The certificate subject’s organization field is used to encode user roles. There is a set of predefined roles that allow access to different API methods:
os:admingrants access to all methods;os:operatorgrants everythingos:readerrole does, plus additional methods: rebooting, shutting down, etcd backup, etcd alarm management, and so on;os:readergrants access to “safe” methods (for example, that includes the ability to list files, but does not include the ability to read files content);os:etcd:backupgrants access to/machine.MachineService/EtcdSnapshotmethod.
Roles in the current talosconfig can be checked with the following command:
$ talosctl config info
[...]
Roles: os:admin
[...]
RBAC is enabled by default in new clusters created with talosctl v0.11+ and disabled otherwise.
Enabling RBAC
First, both the Talos cluster and talosctl tool should be upgraded.
Then the talosctl config new command should be used to generate a new client configuration with the os:admin role.
Additional configurations and certificates for different roles can be generated by passing --roles flag:
talosctl config new --roles=os:reader reader
That command will create a new client configuration file reader with a new certificate with os:reader role.
After that, RBAC should be enabled in the machine configuration:
machine:
features:
rbac: true
12 - System Extensions
System extensions allow extending the Talos root filesystem, which enables a variety of features, such as including custom container runtimes, loading additional firmware, etc.
System extensions are only activated during the installation or upgrade of Talos Linux. With system extensions installed, the Talos root filesystem is still immutable and read-only.
Installing System Extensions
Note: the way to install system extensions in the
.machine.installsection of the machine configuration is now deprecated.
Starting with Talos v1.5.0, Talos supports generation of boot media with system extensions included, this removes the need to rebuild
the initramfs.xz on the machine itself during the installation or upgrade.
There are two kinds of boot assets that Talos can generate:
- initial boot assets (ISO, PXE, etc.) that are used to boot the machine
- disk images that have Talos pre-installed
installercontainer images that can be used to install or upgrade Talos on a machine (installation happens when booted from ISO or PXE)
Depending on the nature of the system extension (e.g. network device driver or containerd plugin), it may be necessary to include the extension in
both initial boot assets and disk images/installer, or just the installer.
The process of generating boot assets with extensions included is described in the boot assets guide.
Example: Booting from an ISO
Let’s assume NVIDIA extension is required on a bare metal machine which is going to be booted from an ISO.
As NVIDIA extension is not required for the initial boot and install step, it is sufficient to include the extension in the installer image only.
- Use a generic Talos ISO to boot the machine.
- Prepare a custom
installercontainer image with NVIDIA extension included, push the image to a registry. - Ensure that machine configuration field
.machine.install.imagepoints to the custominstallerimage. - Boot the machine using the ISO, apply the machine configuration.
- Talos pulls a custom installer image from the registry (containing NVIDIA extension), installs Talos on the machine, and reboots.
When it’s time to upgrade Talos, generate a custom installer container for a new version of Talos, push it to a registry, and perform upgrade
pointing to the custom installer image.
Example: Disk Image
Let’s assume NVIDIA extension is required on AWS VM.
- Prepare an AWS disk image with NVIDIA extension included.
- Upload the image to AWS, register it as an AMI.
- Use the AMI to launch a VM.
- Talos boots with NVIDIA extension included.
When it’s time to upgrade Talos, either repeat steps 1-4 to replace the VM with a new AMI, or
like in the previous example, generate a custom installer and use it to upgrade Talos in-place.
Authoring System Extensions
A Talos system extension is a container image with the specific folder structure.
System extensions can be built and managed using any tool that produces container images, e.g. docker build.
Sidero Labs maintains a repository of system extensions.
Resource Definitions
Use talosctl get extensions to get a list of system extensions:
$ talosctl get extensions
NODE NAMESPACE TYPE ID VERSION NAME VERSION
172.20.0.2 runtime ExtensionStatus 000.ghcr.io-talos-systems-gvisor-54b831d 1 gvisor 20220117.0-v1.0.0
172.20.0.2 runtime ExtensionStatus 001.ghcr.io-talos-systems-intel-ucode-54b831d 1 intel-ucode microcode-20210608-v1.0.0
Use YAML or JSON format to see additional details about the extension:
$ talosctl -n 172.20.0.2 get extensions 001.ghcr.io-talos-systems-intel-ucode-54b831d -o yaml
node: 172.20.0.2
metadata:
namespace: runtime
type: ExtensionStatuses.runtime.talos.dev
id: 001.ghcr.io-talos-systems-intel-ucode-54b831d
version: 1
owner: runtime.ExtensionStatusController
phase: running
created: 2022-02-10T18:25:04Z
updated: 2022-02-10T18:25:04Z
spec:
image: 001.ghcr.io-talos-systems-intel-ucode-54b831d.sqsh
metadata:
name: intel-ucode
version: microcode-20210608-v1.0.0
author: Spencer Smith
description: |
This system extension provides Intel microcode binaries.
compatibility:
talos:
version: '>= v1.0.0'
Example: gVisor
13 - Time Synchronization
Talos Linux itself does not require time to be synchronized across the cluster, but as Talos Linux and Kubernetes components issue certificates with expiration dates, it is recommended to have time synchronized across the cluster. Some workloads (e.g. Ceph) might require to be in sync across the machines in the cluster due to the design of the application.
Talos Linux tries to launch API even if the time is not sync, and if time jumps as a result of NTP sync, the API certificates will be rotated automatically.
Some components like kubelet and etcd wait for the time to be in sync before starting, as they don’t support graceful certificate rotation.
By default, Talos Linux uses time.cloudflare.com as the NTP server, but it can be overridden in the machine configuration, or provided via DHCP, kernel args, platform sources, etc.
Talos Linux implements SNTP protocol to sync time with the NTP server.
Observing Status
Current time sync status can be observed with:
$ talosctl get timestatus
NODE NAMESPACE TYPE ID VERSION SYNCED
172.20.0.2 runtime TimeStatus node 2 true
The list of servers Talos Linux is syncing with can be observed with:
$ talosctl get timeservers
NODE NAMESPACE TYPE ID VERSION TIMESERVERS
172.20.0.2 network TimeServerStatus timeservers 1 ["time.cloudflare.com"]
More detailed logs about the time sync process can be queried with:
$ talosctl logs controller-runtime | grep -i time.Sync
172.20.0.2: 2024-04-17T18:32:16.690Z DEBUG NTP response {"component": "controller-runtime", "controller": "time.SyncController", "clock_offset": "37.060204ms", "rtt": "3.044816ms", "leap": 0, "stratum": 3, "precision": "29ns", "root_delay": "70.617676ms", "root_dispersion": "259.399µs", "root_distance": "37.090645ms"}
172.20.0.2: 2024-04-17T18:32:16.690Z DEBUG sample stats {"component": "controller-runtime", "controller": "time.SyncController", "jitter": "150.196588ms", "poll_interval": "34m8s", "spike": false}
172.20.0.2: 2024-04-17T18:32:16.690Z DEBUG adjusting time (slew) by 37.060204ms via 162.159.200.1, state TIME_OK, status STA_PLL | STA_NANO {"component": "controller-runtime", "controller": "time.SyncController"}
172.20.0.2: 2024-04-17T18:32:16.690Z DEBUG adjtime state {"component": "controller-runtime", "controller": "time.SyncController", "constant": 7, "offset": "37.060203ms", "freq_offset": -1302069, "freq_offset_ppm": -19}
Using PTP Devices
When running in a VM on a hypervisor, instead of doing network time sync, Talos can sync the time to the hypervisor clock (if supported by the hypervisor).
To check if the PTP device is available:
$ talosctl ls /sys/class/ptp/
NODE NAME
172.20.0.2 .
172.20.0.2 ptp0
Make sure that the PTP device is provided by the hypervisor, as some PTP devices don’t provide accurate time value without proper setup:
talosctl read /sys/class/ptp/ptp0/clock_name
KVM virtual PTP
To enable PTP sync, set the machine.time.servers to the PTP device name (e.g. /dev/ptp0):
machine:
time:
servers:
- /dev/ptp0
After setting the PTP device, Talos will sync the time to the PTP device instead of using the NTP server:
172.20.0.2: 2024-04-17T19:11:48.817Z DEBUG adjusting time (slew) by 32.223689ms via /dev/ptp0, state TIME_OK, status STA_PLL | STA_NANO {"component": "controller-runtime", "controller": "time.SyncController"}
Additional Configuration
Talos NTP sync can be disabled with the following machine configuration patch:
machine:
time:
disabled: true
When time sync is disabled, Talos assumes that time is always in sync.
Time sync can be also configured on best-effort basis, where Talos will try to sync time for the specified period of time, but if it fails to do so, time will be configured to be in sync when the period expires:
machine:
time:
bootTimeout: 2m